
ΑΙhub.org
Document grounded generation
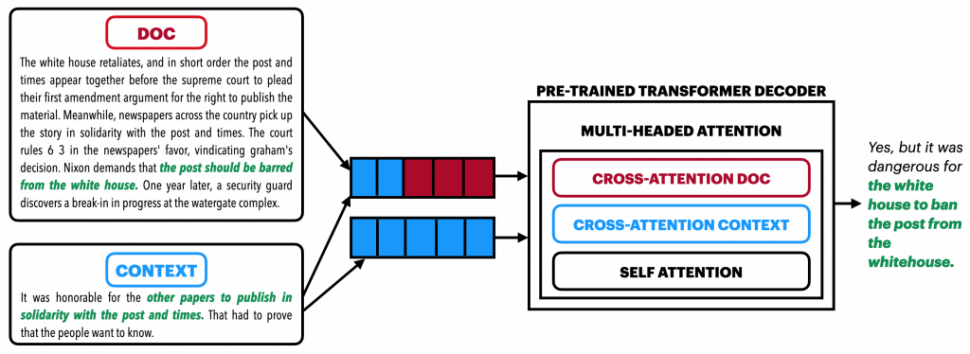
Figure 1: Document Grounded Generation – An example of a conversation that is grounded in the given document (text in green shows information from the document that was used to generate the response).
Natural language generation (NLG) systems are increasingly expected to be naturalistic, content-rich, and situation-aware due to their popularity and pervasiveness in human life. This is particularly relevant in dialogue systems, machine translation systems, story generation, and question answering systems. Despite these mainstream applications, NLG systems face the challenges of being bland, devoid of content, generating generic outputs and hallucinating information (Wiseman et al., EMNLP 2017; Li et al., NAACL 2016; Holtzman et al., ICLR 2020). Grounding the generation in different modalities like images, videos, and structured data alleviates some of these issues. Generating natural language from schematized or structured data such as database records, slot-value pair, and Wikipedia Infobox has been explored extensively in prior work. Although useful, these tasks encounter difficulties such as general applicability (databases may not be available for all domains) and are constrained by the available resources (size of the database).
Document grounded generation mitigates these applicability issues by exploiting the vast availability of data in unstructured form (e.g. books, encyclopedias, news articles, and Wikipedia articles). This enhances the applicability of document grounded generation to a wide range of domains with limited (or no) availability of structured data. Hence, recent work has focused on defining new tasks and carving the scope of the problems (Liu et al., ICLR 2018; Prabhumoye et al., NAACL 2019; Zhou et al., EMNLP 2018).
Defining Document Grounded Generation
The task is to generate text given a context and a source of content (document). Additionally, we want the generated text to coherently fit the context and contain information from the document. Formally, the task is: given an existing context (or curated text)  and a document
and a document  describing novel information relevant to the context, the system must produce a revised text
describing novel information relevant to the context, the system must produce a revised text  that incorporates the most salient information from . Note that the context and document play different roles in impacting the generation — for example in a dialogue generation task, the context sets the background of the conversation while the document provides the content necessary to generate the response.
that incorporates the most salient information from . Note that the context and document play different roles in impacting the generation — for example in a dialogue generation task, the context sets the background of the conversation while the document provides the content necessary to generate the response.
Figure 1 illustrates an example of the document grounded dialogue response generation task. Dialogue response generation is traditionally conditioned only on the dialogue context. This leads to responses which are bland and devoid of content. Figure 1 illustrates that the generator has to account for two inputs the dialogue context (shown in blue) and the document (shown in red) to generate the response grounded in (text shown in green). If the generative model was only conditioned on dialogue context, then it could produce generic responses like “Do you think they did the right thing?” or “Yes, I agree” or hallucinate information like “Yes, and the Times published it on the front page”. These responses would be appropriate to the given context but are devoid of content or contain wrong information. Document grounded models are capable of responding with interesting facts like “Yes, but it was dangerous for the white house to ban the post from the white house”. Hence, we need models that can ground the responses in sources of information. As Figure 1 demonstrates, the generative model is conditioned on both the document as well as the dialogue context.
Another task that falls under the family of ‘Document Grounded Generation‘ is the Wikipedia Update Generation task shown in Figure 2. This task involves generating an update for Wikipedia context given a news article. The dataset was collected by parsing Wikipedia articles and Common Crawl for news articles. It consists tuples of the form ( ,
,  ,
,  ), where the grounding document is the news article which contains information for the reference update . is written by a Wikipedia editor as an update to the Wikipedia context . The goal of the task is to generate (shown in orange) given the Wikipedia context (shown in yellow) and the document (shown in green).
), where the grounding document is the news article which contains information for the reference update . is written by a Wikipedia editor as an update to the Wikipedia context . The goal of the task is to generate (shown in orange) given the Wikipedia context (shown in yellow) and the document (shown in green).
The most straightforward way of using a pre-trained encoder decoder model like BART for modeling  is to concatenate the tokens of the context and the document and pass the concatenated sequence
is to concatenate the tokens of the context and the document and pass the concatenated sequence ![[\mathbf{s}_i;\mathbf{d}_i]](https://aihub.org/wp-content/ql-cache/quicklatex.com-c3b794db5abad7bcb61c4b5245e30ab9_l3.png "Rendered by QuickLaTeX.com") to the BART encoder, and then the decoder generates .
to the BART encoder, and then the decoder generates .
We discuss two ways of building effective representations for pre-trained encoder-decoder models to focus on : (1) combine encoder representations of and , (2) include an additional attention multi-head at each layer of the transformer to specifically focus on the content in .
Context Driven Representation
One of the sub-tasks of document grounded generation is to build representation of the content in the document which is not present in the context. The goal is to identify new information (in particular, \ ) that is most salient to the topic or focus of the context, then generate a single sentence that represents this information. We leverage self-attention mechanism of transformers to build such a representation. We propose to use two separate encoder representations for the context and document as follows:
![\mathbf{h}_d = \mathsf{Encoder}([\mathbf{s}_i; \mathbf{d}_i]](https://aihub.org/wp-content/ql-cache/quicklatex.com-407b6db5462b1c1597f4c7099c2f89b1_l3.png "Rendered by QuickLaTeX.com") this is the contextualized representation of conditioned on the context .
this is the contextualized representation of conditioned on the context .  is equivalent to the representation used in the BART baseline.
is equivalent to the representation used in the BART baseline.- We then apply the same BART encoder to the context alone:

- We finally concatenate the encoder outputs
![\mathbf{h} = [\mathbf{h}_s;\mathbf{h}_d]](https://aihub.org/wp-content/ql-cache/quicklatex.com-a043d1c19a7b67b5a814ee0aa2b6e93d_l3.png "Rendered by QuickLaTeX.com") before passing them to the BART decoder.
before passing them to the BART decoder.
This  is the Context Driven Representation (CoDR). Hence, the decoder gets access to the context representation
is the Context Driven Representation (CoDR). Hence, the decoder gets access to the context representation  and a representation of the document . This method does not require any model architectural modification, and instead the encoder and decoder are fined-tuned to use the multiple input representations.
and a representation of the document . This method does not require any model architectural modification, and instead the encoder and decoder are fined-tuned to use the multiple input representations.
Document Headed Attention
Documents are typically longer than context. Hence, we need additional parameters to pay specific attention to the information in the document. Document Headed Attention (DoHA) is introduced to further enhance the use of the multiple input representations.
A decoder in transformer encoder-decoder models has two types of multi-head attention mechanism, SelfAttention and CrossAttention with the source sequence. SelfAttention module allows each position in the decoder to attend to all positions in the decoder up to and including that position. CrossAttention module performs multi-head attention over the output of the encoder stack and attends over the source sequence. While our CoDR method uses the two different source representations, and , CrosstAttention is still shared over the concatenated representation .
We add an additional multi-head attention CrossAttention_Doc to specifically attend over the tokens of the document; while the original CrossAttention (named as CrosstAttention_Cxt here), only attends over the tokens of the context.
The multi-head function shown below receives three inputs – a query  , key
, key  and value
and value  .
.  is an output projection of the concatenated outputs of the attention heads.
is an output projection of the concatenated outputs of the attention heads.
![\[\mathsf{MultiHead}(Q, K, V) = [\mathbf{H}_1; \ldots; \mathbf{H}_m]\mathbf{W}^{o}\]](https://aihub.org/wp-content/ql-cache/quicklatex.com-a43577cf22492259c2236a1770033955_l3.png "Rendered by QuickLaTeX.com")
Each  is the output of a single attention head and
is the output of a single attention head and  ,
,  and
and  are head-specific projections for , , and , respectively.
are head-specific projections for , , and , respectively.
![\[H_j = \mathsf{Attention}(Q\mathbf{W^{Q}_{j}}, K\mathbf{W^{K}_{j}}, V\mathbf{W^{V}_{j}})\]](https://aihub.org/wp-content/ql-cache/quicklatex.com-e6e6676e655f6d4af70906c7383c7029_l3.png "Rendered by QuickLaTeX.com")
Hence, the multi-head CrossAttention_Doc is defined by:
![\begin{eqnarray*}\mathsf{CrossAttention\_Doc}(Q, K, V) = [\mathbf{H}_1; \ldots; \mathbf{H}_m]\mathbf{W^{do}}, \\ \mathbf{H}_j = \mathsf{Attention}(Q\mathbf{W^{dQ}_{j}}, K\mathbf{W^{dK}_{j}}, V\mathbf{W^{dV}_{j}}),\end{eqnarray*}](https://aihub.org/wp-content/ql-cache/quicklatex.com-101901fb1f0868c0edbe2c5ef4761d87_l3.png "Rendered by QuickLaTeX.com")
where  and
and  are parameters trained specifically to focus on document. The parameters of CrossAttention_Doc are initialized with those of CrossAttention_Cxt.
are parameters trained specifically to focus on document. The parameters of CrossAttention_Doc are initialized with those of CrossAttention_Cxt.
Each decoder layer follows the following sequence of functions:

where  are the embeddings of the tokens generated up to the current time step,
are the embeddings of the tokens generated up to the current time step,  is the representation of the context,
is the representation of the context,  is the representation of the document,
is the representation of the document,  is a sequence of
is a sequence of  , followed by
, followed by  . We integrate the additional attention head CrossAttention_Doc by passing the output of the previous attention head CrossAttention_Cxt as query. This technique of fusing the additional attention head is novel and useful as it does not require any additional parameters for the fusion.
. We integrate the additional attention head CrossAttention_Doc by passing the output of the previous attention head CrossAttention_Cxt as query. This technique of fusing the additional attention head is novel and useful as it does not require any additional parameters for the fusion.
Figure 1, shows an example of a transformer decoder with an additional CrossAttention_Doc to focus on the document.
Manual Inspection of Generations
We manually inspect the outputs of the CoDR model on the development set of Wikipedia Update Generation task to understand their quality. Rouge-L measures the longest common subsequence between the generated sentence and the reference, capturing both lexical selection and word order. We inspect 60 samples which have Rouge-L score  . These are chosen such that we have 10 samples in each of the 6 buckets of Rouge-L score (buckets are range of 10 points: 0-9, 10-19, 20-29, 30-39, 40-49 and 50-59). We analyze the generated outputs along the two aspects of appropriateness of the generation to the context and its grounding in the document.
. These are chosen such that we have 10 samples in each of the 6 buckets of Rouge-L score (buckets are range of 10 points: 0-9, 10-19, 20-29, 30-39, 40-49 and 50-59). We analyze the generated outputs along the two aspects of appropriateness of the generation to the context and its grounding in the document.
1. Linguistic Variation
In this error class, the reference and the generation are both grounded. The generation is appropriate to the Wikipedia context but it is a linguistic variation of the reference or an alternate appropriate update. The generation in this case is perfectly acceptable and yet it gets a low Rouge-L score! A substantial 43% of the cases fall in this error class. As we can see in the example shown below, the generation is correct and yet it gets a Rouge-L score of 41.
Reference: December 12 - The Smiths play Brixton Academy, their last ever gig before their dissolution.Generation: December 12 - The Smiths perform their final show, at Brixton Academy in London.2. Partial Hallucination
In this case, the reference and generation are both grounded in the document. The generation has captured some information from the document that is present in the reference. But it may either be missing some information (missed information is shown in red in the reference) or hallucinates some information (hallucinated information is shown in red in generation). A good 23% cases fall in this category.
Reference: America Online and Prodigy (online service) offered access to the World Wide Web system for the first time this year, releasing browsers that made it easily accessible to the general public.Generation: The World Wide Web was first introduced on January 17, 1995 on Prodigy.3. Incoherent Reference
The reference itself does not coherently follow the Wikipedia context in this case. 22% cases fall in this category. This is primarily observed for Wikipedia pages that are in the form of a list like 1340s and Timeline of DC Comics (1950s). Yet, for 50% of these cases, the generation is grounded in the document and very close to the reference (like the example shown below). This example is perfectly acceptable alternative to the reference and gets a Rouge-L score of 26.
Reference: "The Naked Ape", by Desmond Morris, is published.Generation: Zoologist Desmond Morris publishes "The Naked Ape".4. Incorrect Generation
Only for 7% of the cases, the generation is completely incorrect. The generation is either not appropriate or is not grounded (completely hallucinates the information). All the information in the generated example shown below is hallucinated and hence marked in red.
Reference: The year 2000 is sometimes abbreviated as "Y2K" (the "Y" stands for "year", and the "K" stands for "kilo-" which means "thousand").Generation: The Y2K conspiracy theory claimed that a secret nuclear attack by the United States on 2 January 2000 was planned to begin World War 2.5. Reference is not grounded
For 5% cases, the reference itself is not grounded in the document provided. This is dataset noise which cannot be improved through model improvements. The information mentioned in the reference is not present in document provided for this example.
Reference: This was achieved under dead calm conditions as an additional safety measure, whereas the Wrights flew in a 25 mph+ wind to achieve enough airspeed on their early attempts.Generation: This was verified by a video crew present at the test flight.Comparison of Generated text with Reference
The models get scored in the range of  s on a scale of
s on a scale of  for automated metrics like BLEU, METEOR and Rouge-L. Details about the automated evaluation and human evaluation are provided in our paper. But the manual inspection indicates that the quality of the model generated text is better than what is portrayed by the automated metrics. With the insights from manual inspection, we performed another comparative study with human judges (on Amazon Mechanical Turk). This was to understand how our models perform in comparison with the reference. The human judges are provided with the following instruction:
for automated metrics like BLEU, METEOR and Rouge-L. Details about the automated evaluation and human evaluation are provided in our paper. But the manual inspection indicates that the quality of the model generated text is better than what is portrayed by the automated metrics. With the insights from manual inspection, we performed another comparative study with human judges (on Amazon Mechanical Turk). This was to understand how our models perform in comparison with the reference. The human judges are provided with the following instruction:
Pick the option that is most appropriate to the given context
We annotated samples for each DoHA and CoDR model in comparison with the reference on the Dialogue Response Generation and Wikipedia Update Generation tasks. We perform two separate comparative experiments: Reference vs CoDR and Reference vs DoHA.
The results in Table 1 show consolidated results for the two models. It shows the percentage of times reference was selected, the percentage of times ‘No Preference’ was selected or the percentage of times CoDR or DoHA outputs were selected. The table shows that model generated output was selected more number of times by human judges in comparison to the human written references. This demonstrates that both CoDR and DoHA models produce appropriate outputs which can be used as alternate responses/updates. These models are preferred over the reference in both the tasks suggesting that the automated evaluation is insufficient and the sole reference should not be considered as the only correct response to the context.
| Task | Reference | No Preference | DoHA or CoDR |
| Wikipedia Update Generation | 33.9 | 28.3 | 37.8 |
| Document Grounded Dialogue Response Generation | 22.8 | 45.6 | 31.6 |
Ethical Considerations
The intended use of the models described above is to aid the NLG systems in generating content-rich text. Note that this does not imply that the models generate factually correct text. The generation entirely depends on the information in the document provided. If the document itself is factually incorrect then the generation would be grounded in false content and hence generate inaccurate text. The trained models are faithful to the information in the document and do not fact-check the document.
We hope that this technology is used for socially positive applications like building trust of users in dialogue systems like Alexa, Siri and Google Home by providing users with credible information. This work has specifically focused on two datasets of dialogue response generation with the aim that this research not only helps in generating responses which contain useful information but also increase credibility of responses by disclosing the source of information. If dialogue systems base their responses on certain sources of information then they can potentially disclose the source of information to the user. The user then has the agency to make informed decision about trusting the system responses or not.
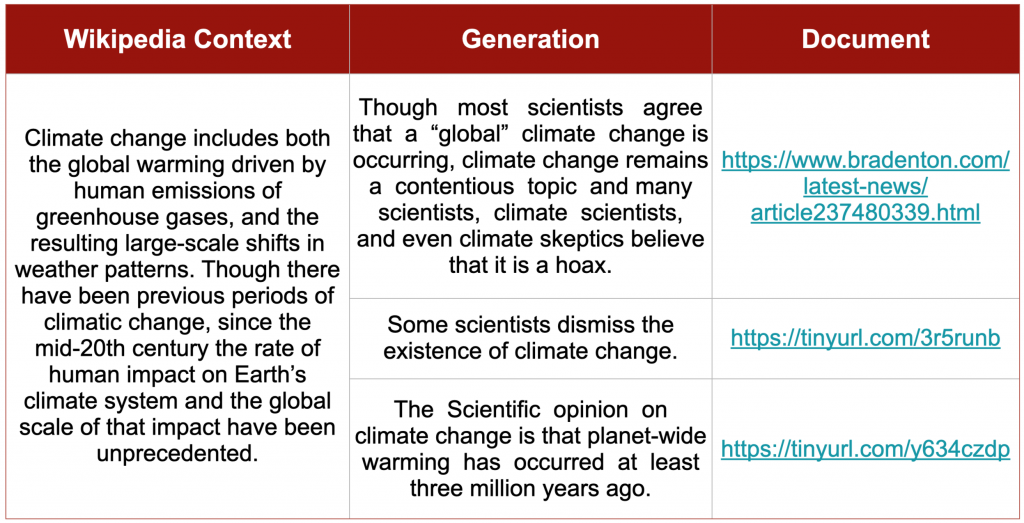
We hand selected a few news articles which contained inaccurate information. We provided relevant Wikipedia context and generated an update for the context using the trained DoHA model on Wikipedia Update generation dataset. The generations are shown in Table 2. Note that this shows the potential misuse of the task design. Interestingly, it also shows the sensitivity of the trained model to the document information. It consists of the same context and different documents were provided as inputs to the model and the generated outputs. The generated outputs are different for each document.
For more details please check our paper here and the code accompanying the paper here.
DISCLAIMER: All opinions expressed in this post are those of the author and do not represent the views of CMU.
This article was initially published on the ML@CMU blog and appears here with the authors’ permission.

AIhub is supported by:








