
ΑΙhub.org
Learning an artificial language for knowledge-sharing in multilingual translation
In their recent paper Learning an artificial language for knowledge-sharing in multilingual translation, Danni Liu and Jan Niehues investigate multilingual neural machine translation models. Here, they tell us more about the main contributions of their research.
What is the topic of the research in your paper?
Neural machine translation (NMT) is the backbone of many automatic translation platforms nowadays. As there are over 7,000 languages in the world, multilingual machine translation has become increasingly popular for reasons including the following:
- Ease of deployment: no need to build separate models for each language pair;
- Cross-lingual knowledge-sharing: learning to translate multiple languages could create synergies and improve translation performance.
The second characteristic is especially useful in low-resource conditions, where training data (translated sentence pairs) are limited. To enable knowledge-sharing between languages, and to improve translation quality on low-resource translation directions, a precondition is the ability to capture common features between languages. However, most commonly used NMT models do not have an explicit mechanism that encourages language-independent representations.
If we look into the field of linguistics, efforts to represent common features across languages date back decades: artificial languages like Interlingua and Esperanto were designed based on the commonalities of a wide range of languages. Inspired by this, in our paper Learning an artificial language for knowledge-sharing in multilingual translation (to appear in the Conference of Machine Translation in December 2022), we ask the questions:
- Can we adapt the current NMT models to represent input languages in an artificial language?
- Can we use this to improve robustness in low-resource conditions?
- Can we use this to better understand the representations learnt by multilingual NMT models?
Could you tell us about the implications of your research and why it is an interesting area for study?
A practical implication of our work is the importance of choosing a suitable combination of languages when building multilingual translation systems. This appears more crucial than the amount of training data, which is often assumed to be the primary factor influencing model performance. In our experiments on translating several Southeast Asian languages (Malay, Tagalog/Filipino, Javanese), we study the impact of using English and Indonesian as the bridge-language (Figure 1). Many previous works focus on the English-centered data condition, where all training data are translations to English. This is a natural choice, as translations to English are often the easiest to acquire, partly owing to the amount of existing translated materials and the wide adoption of English as a second language. Indeed, our training data (extracted from the OPUS platform) for the English-bridge condition is roughly four times that of the Indonesian-bridge case. However, as the results show, it is the Indonesian-centric case where we see stronger overall performance and more stable zero-shot performance. This is likely because the latter case enables more knowledge-sharing, thereby making the learning task easier even given less data. Our analyses of the learned representations also confirm this.
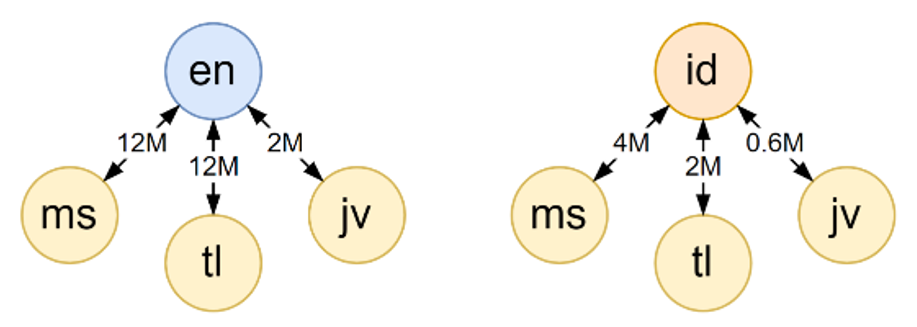 Figure 1: Data condition for English (en), Indonesian (id), Malay (ms), Tagalog (tl), Javanese (jv). Arrows indicate available parallel training data; numerical values indicate the number of translated sentence pairs in the training data.
Figure 1: Data condition for English (en), Indonesian (id), Malay (ms), Tagalog (tl), Javanese (jv). Arrows indicate available parallel training data; numerical values indicate the number of translated sentence pairs in the training data.
From a more theoretical point-of-view, our work shows the possibility of adapting the Transformer model – a prevalent model in NMT – with the additional constraint that discretizes its continuous latent space. The resulting model in effect represents sentences from difference source languages in an artificial language. In terms of performance, this model shows improved robustness in zero-shot conditions. Although the results did not surpass existing methods that enforce language-independent representations in the continuous space, the discrete codes can be used as a new way to analyze the learned representations. It is with these analyses that we substantiate the aforementioned finding on the benefit of incorporating similar bridge languages.
Could you explain your methodology?
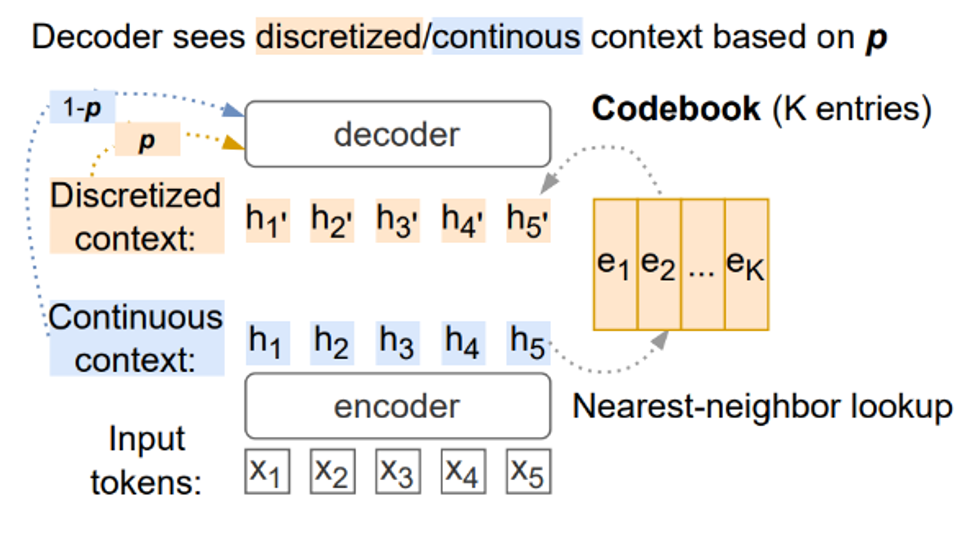
Our proposed model adds a discretization module between the encoder and decoder of the Transformer model (Figure 2). This module consists of a codebook with a fixed number of entries. Each entry in the codebook is analogous to a word in the learned artificial language. The encoded representation of an input sentence is then mapped to a sequence of entries from the codebook. This process transforms the source language into the artificial language.
Figure 2: Illustration of the discretization module (marked in colors) in addition to an encoder-decoder-based translation model.
To make this idea work for our translation task, we addressed multiple challenges:
- Difficulty of end-to-end training: The discretization module, more specifically its nearest-neighbor lookup operation, hinders the training of all model parameters by backpropagation, since neural network training requires continuous differentiable inputs. In response, we use the straight-through estimator to enable gradient flow to the otherwise non-trainable parameters. We also use an auxiliary training objective that minimizes the difference between the discretized and continuous context. This approach is based on the work of van den Oord et al. (2017).
- Information bottleneck: The discretization module supports a finite number of unique combinations, and therefore could become an information bottleneck that negatively impacts how much the model can learn. This could, in turn, harm the translation performance. In response, we propose a “soft” discretization mechanism, where the model alternatively relies on the discretized and continuous representation. This way, the model could still benefit from the richer representations prior to discretization.
- Index collapse: Another challenge occurs when the lookup of artificial language tokens degenerates to always returning the same or a few tokens. This would render the model representation of the input sentences meaningless. We tackle the index collapse problem by slicing the codebook, which in effect uses multiple codebooks of a smaller hidden dimension. This approach is inspired by Kaiser et al. (2018).
What were your main findings?
The main findings from this work are:
- It is possible to add a discretization module in Transformer-based NMT models, which in effect maps the input sentences into an artificial language. While the model suffers from some degradation on supervised directions, it shows stronger performance in zero-shot conditions.
- In multilingual translation, using a similar bridge language not only leads to more knowledge-sharing between the bridge language and the remaining languages, but also among the remaining languages. This shows the importance of choosing a suitable combination of languages when building multilingual translation systems.
What further work are you planning in this area?
Currently, our model maps an input sentence to indices from the learned codebook. This is a sequence of numbers. So although it gives a mechanism to compare model intermediate representations, the codes are not directly interpretable by humans. A potential improvement would be to use an existing codebook that corresponds to an actual human language.
We also would like to explicitly incentivize more shared codes between different, and especially related, languages during training. This would bring the discrete codes closer to a language-independent representation.
About the authors

|
Danni Liu is a PhD student at Karlsruhe Institute of Technology in Germany. She mainly works on multilingual machine translation and speech translation. The main question she is interested in concerns how to learn common representations across different languages or modalities. |

|
Jan Niehues is a professor at the Karlsruhe Institute of Technology leading the “AI for Language Technologies” group. He received his doctoral degree from Karlsruhe Institute of Technology in 2014, on the topic of “Domain adaptation in machine translation”. |

AIhub is supported by:








