
ΑΙhub.org
Interview with AAAI Fellow Sriraam Natarajan: Human-allied AI

Each year the AAAI recognizes a group of individuals who have made significant, sustained contributions to the field of artificial intelligence by appointing them as Fellows. Over the course of the next few months, we’ll be talking to some of the 2025 AAAI Fellows. In this interview we hear from Sriraam Natarajan, Professor at the University of Texas at Dallas, who was elected as a Fellow for “significant contributions to statistical relational AI, healthcare adaptations and service to the AAAI community”. We find out about his career path, research on human-allied AI, reflections on changes to the AI landscape, and passion for cricket.
Could you start by telling us about your career so far, where you work and your broad area of research?
I grew up in the southern part of India, in Chennai. It was called Madras back then, and in 2001, I graduated from the University of Madras. I moved to Oregon State University in 2001 with the goal of doing a master’s in computer networking. In my first year, I was trying to explore theoretical computer science connected to networking. Then I took a grad course in artificial intelligence with Prasad Tadepalli, a Bayesian networks course with Bruce D’ Ambrosio, and machine learning with Tom Dietterich, and I just fell in love with the subjects of artificial intelligence, machine learning, probabilistic models, and knowledge representation. I started taking more courses and Prasad asked me if I wanted to do a PhD in machine learning. Of course, I said yes. I finished my PhD at the end of December 2007, then moved to Wisconsin, Madison in 2008. If you read my PhD thesis, there is not a lot of reference to medicine or healthcare, but when I moved to Wisconsin, I was fortunate to work with Jude Shavlik and David Page. They were stalwarts in machine learning, but they were also looking at machine learning for medicine. I was funded from a DARPA grant, so most of my time was spent on inductive logic programming, and statistical relational learning, but I also decided that I was going to use my evenings and weekends to do machine learning for medicine. After three years of training there, I moved to a medical school, Wake Forest School of Medicine, because I wanted to actually get my hands dirty on healthcare data. That’s where I established a lot of collaborations. I worked there for nearly three years, and then I moved to Indiana University where I helped establish the Health Informatics program. And then, because of my wife’s job situation, we moved to Dallas in 2017, and I’ve been in Dallas since then.
In terms of my areas of research, these are human-allied artificial intelligence, statistical relational AI, and probabilistic graphical models with a focus in healthcare.
In the area of human-allied AI, could you talk about some of the projects that you are currently working on?
To give some background, at a fairly high level, with human-allied AI, we are asking whether we can elicit constraints from human experts that go beyond the data. So, can we get some sort of domain knowledge into the learning system, and also output back to the human by explaining the findings of the model in a human-understandable way?
For me, there are a few problems to solve. One project is building explainable models that can take expert knowledge as constraints, particularly in probabilistic models. We are looking at deep, tractable probabilistic models where you can do inference in a tractable manner. We ask the question of learning from these domain constraints and have a unified way of giving these constraints to tractable probabilistic models.
The second project that I’m working on in this direction is the integration of planning and reinforcement learning. So, you have relational planning at a high level, which allows you to generalize and be deliberative and think about the impacts of these tasks and subtasks, and then use that information to instantiate appropriate reinforcement learning (reactive) tasks. For example, if I’m planning to, let’s say, come to London, I’m just going to book my tickets and book a hotel, make sure the professor that I’m going to meet there is available, etc. Then, at the point of execution, I sit down in my car to go to the airport. That’s when I think about what route I have to take, the speed I should drive at, the angle I should turn my car, etc. These kinds of lower-level actions are done at the execution level and then you have a deliberative reasoning level which says, “OK, these are high level things that we need to do”. So, what we are trying to do is come up with these combinations of planning and reinforcement learning paradigms, which explicitly reason about where you have to be deliberative, and where you have to be reactive. And we have figured out ways where the human experts can provide feedback, both at the higher level and at the lower level of reinforcement learning.
The third direction that I’m working on with relation to this is building systems that continuously interact with physicians. An example domain is cardiovascular health – we’ve been working on this one for about 15 years now. My passion for the last eight-nine years has been working on modelling and mitigating adverse pregnancy outcomes. We’ve been building systems to see if we can model adverse outcomes such as pre-term birth, preeclampsia, hypertension, gestational diabetes and so on. How can we build models that can predict and mitigate these outcomes? Our latest funded project is on looking at neurological injuries in children. We are doing all of this in the presence of domain experts, who in our case are physicians.
Have you been using any of these models in the field?
Yes, we have been working with the doctors. For instance, we developed a model that learned the interaction between the prior risk of having gestational diabetes and the level of exercise in predicting gestational diabetes. We are now talking to the doctors to see how we can translate the findings into actionable outcomes. The same with gestational diabetes and the risk of pre-term birth. What are the interventions that we should take to avoid this? So, once we establish these interactions across cohorts, then we can provide policy advice back to the domain experts who then take it to their associations, and present these results. Hopefully, this will allow us to make changes in the recommendations for these doctors. Deployment in healthcare is going to be slow, but it’s going to have a high impact once we get there. Before deployment you want to make sure that it’s generalizable, and it’s correct, and that it’s as close to reality as possible.
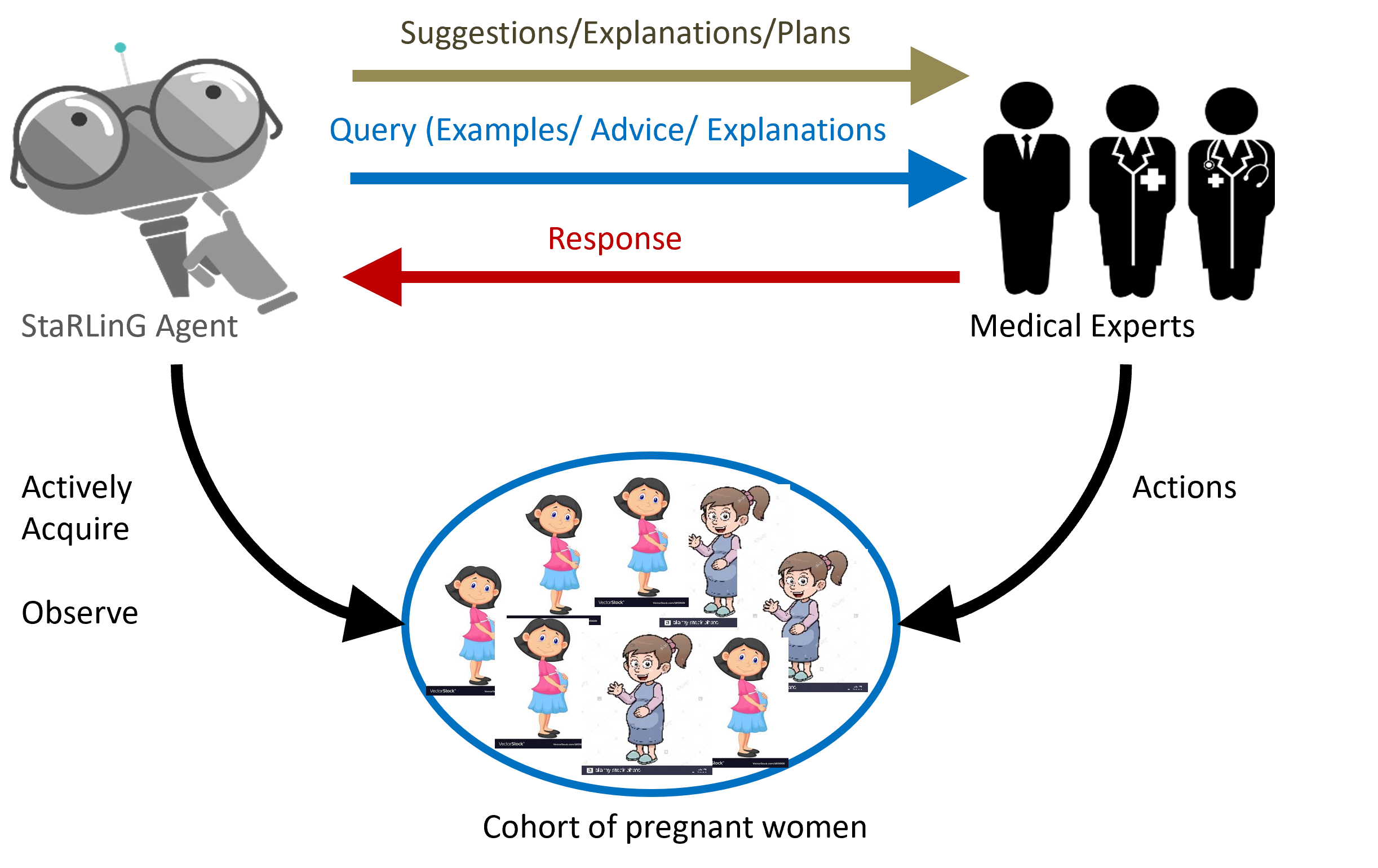
At AAAI 2025, you’ll be presenting a blue sky paper entitled: “Human-in-the-loop or AI-in-the-loop? Automate or Collaborate?”. Could you tell us a bit about that paper and the key ideas you put forward?
The key argument in that paper is to really understand who is in control of the decision-making. One of the fears that most people have is who’s making these decisions in these systems. And the claim we are trying to make here is, for these high-risk applications – healthcare, finance, defense, security, social decisions, and so on – I think it should be the human who makes the final decision, and the AI is there to make the human’s life easier. Whereas if you take a system like movie recommendation, where it is basically of lower risk, that can be an AI that makes the decision, but the human can provide constraints. You can click and say “I don’t like this movie” or “this is inappropriate for my kids” and then that becomes information for the AI system to use to improve its model. I believe that this distinction between who is in control, whether it’s a human or AI, is extremely important for developing appropriate evaluation techniques. The argument we are making in the paper is that the current machine learning evaluations overemphasize the machine component and overlook the experts’ role. And we really need to understand in many systems, particularly if the human is in control, if we are providing these systems with the appropriate evaluation metrics – are they helping humans? Which component is the most useful one? Which component is the most risky? We need to understand the depth of these evaluations before we deploy these systems in the real world. For me, the paper highlights this aspect and motivates a holistic understanding of both the problem that you are trying to work on and the solution that you are trying to deploy. I think that once we understand both of them correctly, then we can deploy the appropriate system.
I was interested in some of the changes in the AI research landscape that you’ve seen throughout your career.
There have been a lot of changes, particularly in the adaptation of these techniques to real problems. When we started doing machine learning and AI, you could use a synthetic data set and that would be enough, because it was just proof of concept that we were looking for. But now, the adaptations are just amazing. The scale at which these things are operating is huge. Back then, if you got 300 examples for a particular task it was great, but now 300 million is very easy to get for some of these tasks. We need to understand the scale and appreciate it. The applications are very wide-reaching at this point too, all the way from dental issues to insole fitting of shoes to fashion design. Back in the day we were thinking about GPS or airline ticket pricing, etc, some of these standard things where AI made a dent, but now it’s pretty much everywhere. That, to me, is fantastic.
The funny thing is, back in the day, we used to think overfitting was extremely important, and I still think it’s very, very important, by the way. But now you hear all this about grokking of transformers; that’s pretty interesting, and it’s a massive change. Having said that, I want to really emphasize that many of the fundamental questions inside machine learning are still the same or very, very relevant. Overfitting, as I mentioned, and generalization are still extremely relevant in several tasks and need to be carefully addressed. The notion of continual learning or active learning has been around for close to 30 years now, and that’s still an important problem. And the interaction between learning and reasoning is something that we’ve been thinking about for 40 years. Causal models have been around since the 1980s when Judea Pearl came up with these books. In my opinion, the holy grail of AI is figuring out how to build these casual models. More importantly, is there a way we can learn from data by using some domain knowledge and how can we do this? And of course, my pet problem is how can we elicit expert knowledge and how can we provide explanations to these experts? So, there have been a lot of changes, particularly in the scale and in the adaptations, but the fundamental questions are still valid, and they are still important, and we still are looking at those as a community.
I was wondering if there’s any advice you would give to PhD students or early career researchers?
Firstly, I would always advise PhD students to read deeply. Some ideas are necessarily old, but in my view, they are worth their weight in gold. So, you really have to understand that just because an idea is slightly old doesn’t mean it’s not valuable. Don’t assume that machine learning started in 2014 and don’t just cite papers from the last five years in your papers. Understand that, when you consider a problem, you have to figure out where it fits in this history of AI and figure out why some of these older formulations are also important.
Secondly, I see a lot of mental health issues because papers get rejected. Do not get dejected because of a single paper rejection. The noise at this scale is unavoidable. We do not want our models to overfit, so we should not overfit to one reviewer, or one reviewer’s views of your paper. You want to understand deeply where the mistakes are and how you can fix it and improve. My request all the time to students is to not overfit to one decision.
Finally, I want to emphasize, and I tell this to my students all the time, a good review is not an aggressive review – a good review means you provide constructive feedback. I do this exercise with my students where I ask them to put themselves in the position of the author and ask if the review they’ve written is just unnecessarily brutal or could be rewritten in a way that is more constructive.
Finally, have you got any interesting hobbies or interests outside of research?
I grew up in India in the 1980s, when we won the Cricket World Cup (in 1983), so cricket has been in my blood since then. So, I am an avid cricket watcher, I play cricket, but more importantly, I analyze cricket deeply. I have read about 50 biographies and autobiographies of cricketers, I have read books on the history of cricket, I own two copies of the Encyclopedia of Cricket, and so I am fully into cricket. Cricket is something that fuels me, I think that’s my passion and hobby. If I was not a machine learning researcher, I want to believe that I would have been a cricket commentator or a cricket writer or something in that space.
I also love music, but I didn’t have the bandwidth to learn anything formally until about two years ago. For the last two years I’ve been learning South Indian classical music. There is an instrument called mridangam that I am learning to play along with my kid. The two of us are learning together, and so I am growing with him in this music. Finally, I would love to kick back and watch nature/science documentaries with my wife and kid during Friday and Saturday nights!
About Sriraam

|
Sriraam Natarajan is a Professor and the Director for Center for ML at the Department of Computer Science at University of Texas Dallas. He is a AAAI fellow, a hessian.AI fellow at TU Darmstadt and a RBDSCAII Distinguished Faculty Fellow at IIT Madras. His research interests lie in the field of Artificial Intelligence, with emphasis on Machine Learning, Statistical Relational Learning and AI, Reinforcement Learning, Graphical Models and Biomedical Applications. He was the program chair of AAAI 2024, the general chair of CoDS-COMAD 2024, program co-chair of SDM 2020 and ACM CoDS-COMAD 2020 conferences. He was the specialty chief editor of Frontiers in ML and AI journal, and is an associate editor of JAIR, DAMI and Big Data journals. |
tags: AAAI, AAAI Fellows

AUAI is supported by:








