
ΑΙhub.org
A survey on knowledge-enhanced multimodal learning
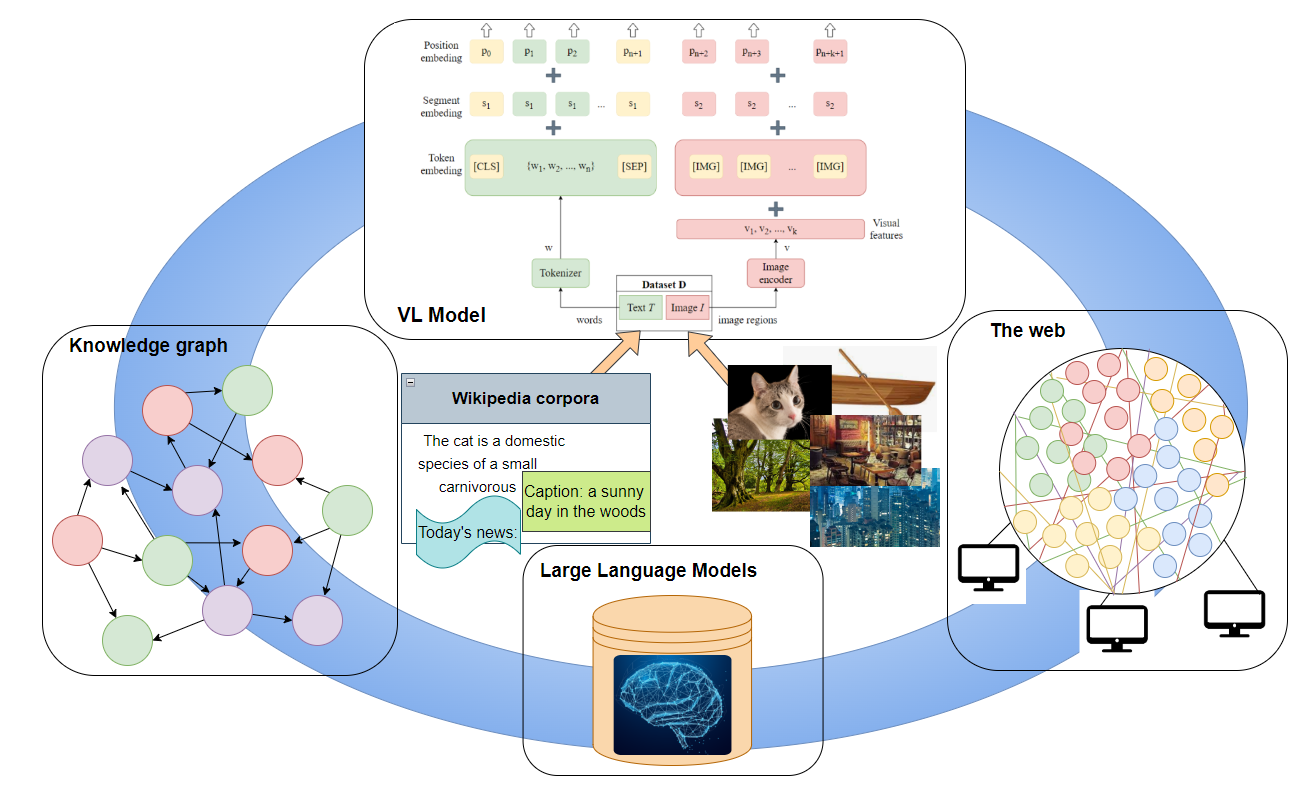
Multimodal learning is a field of increasing interest in the research community, as it is more closely aligned to the way a human perceives the world: a combination of visual information, language, sounds, and other senses provides complementary insights regarding the world state. Significant advancements in unimodal learning, such as the advent of transformers, boosted the capabilities of multimodal approaches, not only in terms of task-specific performance but also regarding the ability to develop multi-task models. Nevertheless, even such powerful multimodal approaches present shortcomings when it comes to reasoning beyond before-seen knowledge, even if that knowledge refers to simple everyday situations such as “in very cold temperatures the water freezes”. This is where external knowledge sources can contribute to enhance model performance by providing such pieces of missing information.
The term “knowledge-enhanced” refers to any model utilizing external (or even internal) knowledge sources to extend their predictive capabilities beyond the knowledge that can be extracted from datasets learned during the training phase. Our analysis focuses on the collaboration of knowledge with models that include vision and language (VL), placed under the term of knowledge-enhanced visiolinguistic (KVL) learning. External knowledge is a description of relevant information which cannot be derived from existing data. It can be in a structured, unstructured or encoded form. An example of structured knowledge representations are knowledge graphs that are currently widely used [1, 2 and others]. Textual knowledge crawled from the web is an example of unstructured knowledge that can dynamically boost the capabilities of VL models, as has been lately proved [3]. On the other hand, pre-trained large language models (LLMs) are steadily gaining ground by storing information learned from extremely large amounts of data, encoding knowledge into the model [4, 5 and others]. We view as internal or self-acquired knowledge any extra information that can be derived from the existing training data. For example, extracting objects from an image of the dataset may provide some extra information, even though the model remains limited to the information provided within the dataset.
Multimodal representation learning
Any VL model relies on a certain understanding of the related modalities before proceeding with task-related predictions. This understanding is obtained through appropriate VL representations, which in turn require independent representations of vision and language. We observed that the way language is represented plays a crucial role in the overall architecture of a model, as well as its capabilities; this is mainly attributed to the choice of using transformers or not. On the contrary, visual representations follow a certain path, mainly relying on popular image classifiers as feature extractors, and even particular variations do not influence subsequent design choices.
The most recent VL architectures adopt the pre-training fine-tuning scheme of language transformers, such as BERT. In those cases, certain modifications on BERT are performed to incorporate the visual modality. The most popular technique is to encode image regions using a pre-trained feature extractor and pass those encodings, together with the encoded text, to the input of a transformer structure. Consequently, during the pre-training stage, visual and linguistic relationships existing in data are learned with the help of objective functions. These functions enable the association of linguistic and visual parts, such as words and objects by forcing the model to pair information between modalities in a self-supervised way. For example, words may be masked, and then the model learns to fill in the sentences via the associated image regions. In order to obtain a more global understanding of image-text pairs, the model learns ground truth image-text matchings as positive pairs, while a random pairing between images and sentences instructs negative pairs containing unmatched features. Pre-training is performed on large amounts of images annotated with captions, so that a generic understanding of how the two modalities interact is obtained.
Fine-tuning requires a comparatively minimal adjustment of the pre-trained model weights on task specific datasets, upon which the capabilities of this model are evaluated. Tasks which combine vision and language can be either tailored to be discriminative or generative, a factor which once again defines design choices. As for discriminative tasks, a model can either perform a variety of them under the same pre-trained body or may focus on a specific task at a time. Discriminative tasks include visual question answering (VQA), visual reasoning (VR), visual commonsense reasoning (VCR), visual entailment (VE), visual referring expressions (VRE), visual dialog (VD), multimodal retrieval (text-image retrieval/TIR or image-text retrieval/ITR), vision-and-language navigation (VLN), visual storytelling (VIST) and multimodal machine translation (MMT). Generative tasks refer to either language generation or image generation. Image captioning (IC) is a language generation task, while some generative tasks stemming from discriminative ones are visual commonsense generation (VCG) and generative VQA. Image generation from text significantly diverges from the practices used in discriminative tasks or language generation. Instead of favoring transformer-based architectures, image generation mainly utilizes generative adversarial networks (GANs) and more recently diffusion models.
Knowledge senses and sources
A categorization of knowledge based on the nature of the associated information can be provided under the term “knowledge senses”. The most prominent knowledge sense refers to commonsense knowledge. This is the inherent human knowledge which is not explicitly taught and is heavily associated with everyday interactions with the world or with some basic rules learned during early childhood. Some subcategories of commonsense knowledge include similarity/dissimilarity relationships, knowledge of parts (the bark is a part of the tree), utility functions (the fork is used for eating), spatial rules (boats are situated near water), comparisons (adults are older than children), intents and desires (a hungry person wants to eat), and others. Other senses include knowledge of temporal events, facts and named entities such as names of famous people, locations, organizations. Combinations of knowledge senses can even lead to advanced reasoning such as counterfactual statements (if the boy had not dropped the glass of water, the glass would not have been broken), which are highly associated with human intelligence. Moreover, visual knowledge combines concepts (such as the concept tree) with the actual visual appearance of this concept (an image of a tree). Despite the simple nature of such knowledge statements from the perspective of a human, an algorithm cannot reproduce such reasoning, if no such statements have appeared in the training phase.
The way external knowledge is provided can be divided into explicit and implicit knowledge. Knowledge graphs are explicit knowledge sources, as all concepts and relationships stored in them are fully transparent, and reasoning paths are tractable. Those characteristics provide explainability in the decision-making process, eliminating the possibility of reproducing biases and errors. However, the construction and maintenance of knowledge graphs requires human effort. Implicit knowledge refers to information stored in neural network weights, as obtained from offline training procedures. Recently, massive pre-training enabled the incorporation of unprecedented amounts of information within state of-the-art large language models(LLM); there is no way that this information could be stored in knowledge graphs. As a result, LLMs present some human-like capabilities, such as writing poems and answering open-ended questions. Efficiently retrieving information from LLMs can fuse these capabilities to VL models, even though prompting LLMs is still an open problem, while the reasoning process of LLMs remains completely opaque. An additional issue accompanying massive pre-training is the computational resources needed, which limits the ability of creating and potentially accessing such knowledge to a handful of institutions. At the same time, environmental issues question the viability of such approaches. A trade-off between explicit and implicit knowledge sources can be found in web-crawled knowledge: web knowledge is already created, therefore no manual construction is required, while power consumption to retrieve relevant data is minimal compared to massive pre-training. A disadvantage of web-crawled knowledge is the potentially reduced validity and quality of the retrieved information.
Trends and challenges around KVL learning
Throughout our analysis, an apparent observation was that transformer-based approaches have naturally started to monopolize the field of knowledge-enhanced VL (KVL) learning, following the same trend as Natural Language Processing. Currently, single-task KVL models significantly outnumber multi-task ones. The pre-training fine-tuning scheme gradually enables the incorporation of multiple tasks in one model, promoting multi-task over single-task learners. Still, multi-task KVL models focus on a narrow set of discriminative tasks, indicating that there is a noticeable gap to be covered from future research. A related challenge comes to the development of multi-task generative KVL models, or the integration of generative tasks with discriminative ones.
Other than that, most already implemented tasks focus on certain knowledge senses, mostly around commonsense-related subcategories. Potentially interesting implementations can include other knowledge senses, such as factual and temporal knowledge. Going one step further, imposing knowledge guided counterfactual reasoning in VL models would open a wide range of new possibilities. Current LLMs such as GPT-3 and ChatGPT have already reached such advanced capabilities in natural language, therefore we would expect their exploitation in forthcoming VL approaches. Such attempts can naturally reveal zero-shot aspects of existing tasks, therefore achieving the real extendability of VL learning.
Of course, testing the limits of KVL approaches cannot be possible without the creation and usage of appropriate datasets per task. So far, knowledge-enhanced VQA has received lots of attention with 8 dedicated datasets, which led to a rich relevant literature. However, the rest of the downstream VL tasks are noticeably underrepresented in terms of knowledge-demanding datasets, with existing implementations competing against the datasets used in knowledge-free setups.
Finally, we view the explainability-performance tradeoff as an issue of utmost importance in KVL learning. Although explainability enhancement was one of the main ventures of primary works in the field, thanks to the usage of explicit knowledge graphs, the focus rapidly shifted towards other usages of knowledge. In total, we spot an interesting emerging contradiction: while the current trend instructs the exploitation of large, though opaque, models, which seem to approach human-level cognitive capabilities, certain issues often lead us to question our trust in such models. Misleading outputs [6] driven by erroneous or purposely manipulated inputs can lead to improper usage of such models, while the reasoning paths followed in such cases are not clearly highlighted.
In conclusion, we believe that the merits of both LLMs and knowledge graphs should be combined to offer trustworthy and impressive applications to this upcoming field of artificial intelligence.
Our survey paper is currently available as an ArXiv pre-print [7]. To the best of our knowledge, it is the first survey paper on the field of KVL learning, referencing several related works.
References
[1] Multi-Modal Answer Validation for Knowledge-Based VQA. Jialin Wu, Jiasen Lu, Ashish Sabharwal, Roozbeh Mottaghi. AAAI 2022.
[2] KM-BART: Knowledge Enhanced Multimodal BART for Visual Commonsense Generation. Yiran Xing, Zai Shi, Zhao Meng, Gerhard Lakemeyer, Yunpu Ma, Roger Wattenhofer. ACL 2021.
[3] Weakly-Supervised Visual-Retriever-Reader for Knowledge-based Question Answering. Man Luo, Yankai Zeng, Pratyay Banerjee, Chitta Baral. EMNLP 2021.
[4] An Empirical Study of GPT-3 for Few-Shot Knowledge-Based VQA. Zhengyuan Yang, Zhe Gan, Jianfeng Wang, Xiaowei Hu, Yumao Lu, Zicheng Liu, Lijuan Wang. AAAI 2022.
[5] StoryDALL-E: Adapting Pretrained Text-to-Image Transformers for Story Continuation. Adyasha Maharana, Darryl Hannan, Mohit Bansal. ArXiv preprint.
[6] Aligning Language Models to Follow Instructions.
[7] A survey on knowledge-enhanced multimodal learning. Maria Lymperaiou and Giorgos Stamou. ArXiv preprint.


AUAI is supported by:








