
ΑΙhub.org
#ICML2021 invited talk round-up 2: randomized controlled trials, encoding speech, and molecular science
In this post, we summarise the final three invited talks from the International Conference on Machine Learning (ICML). These presentations covered: how machine learning can complement randomised controlled trials, encoding and decoding speech, and molecular science.
Plumbers and mechanics: how ML can complement RCT in policy experiments – Esther Duflo
Esther’s work centres on the use of randomised controlled trials (RCT) and she runs policy experiments with the aim of understanding which policies work and which don’t. Her work is particularly focussed on reducing poverty. Work of this type involves many causal questions, for which there are often many competing ideas. Such is the field that there is no real guidance for theory; experiments are needed to determine successful policies. Esther believes that RCT are a useful tool as they force researchers and policy makers to try things out, and from those experiments one can learn a great deal.
Explaining the title of her talk, Esther said that economists can be viewed as plumbers – they need to use tools in the real world, tinker with them, and try things out. Keeping with the analogies, she described machine learning experts as mechanics – they are trying to make machines learn, and tuning their procedures, often quite empirically.
At first glance, the fields of empirical economics and machine learning seem quite different. Machine learning is for predictions and economists use RCT for causal inference in very low dimensional settings. However, there is benefit in combining the fields. Indeed, machine learning is also used for causal inference, and RCT could provide a useful benchmark for comparing the performance of machine learning tools.
Esther pointed to an example of economics and machine learning pairing up, in the form of a collaboration between Josh Blumenstock and colleagues and the government of Togo. Machine learning was used to determine priority recipients of emergency cash transfers.
Another area where one might find a useful collaboration between machine learning and RCT is in the practice of the experiments themselves, and specifically what Esther referred to as policy experiments. In simple experiments, such as a clinical trial where there is only one possible treatment to be tested, it is not necessary to use machine learning. However, in large-scale experiments with many variables, which are designed to provide guidance for policy makers, there is nothing to tell us in advance which course of action is best, and for whom, and when. These are the kinds of experiments where machine learning is particularly useful.
Esther provided the example of a study she has been working on in collaboration with the Indian government. In Haryana, India, only around 40% of children get immunised and the aim was to work out how to increase this. Previous research has shown that things like incentives, recruiting vaccination ambassadors, and SMS reminders can have a positive impact. In this study in Haryana there were 75 different treatment options and the goal was to work out which would be most successful for different sub-groups. With so many options, and much of the resulting data interlinked, this is where machine learning comes to the fore, providing the means to sift through the data. The goal is to define an algorithm that can give you the right cut of the data for a particular situation, not just a specific cut of the data.
Esther concluded with a machine learning wish list of tools that she would find useful for her research. This includes: tools for smaller datasets, tools for multiple inferences, and tools for data cleansing, anonymising and consistency checks.
You can find Esther Duflo’s biography here.
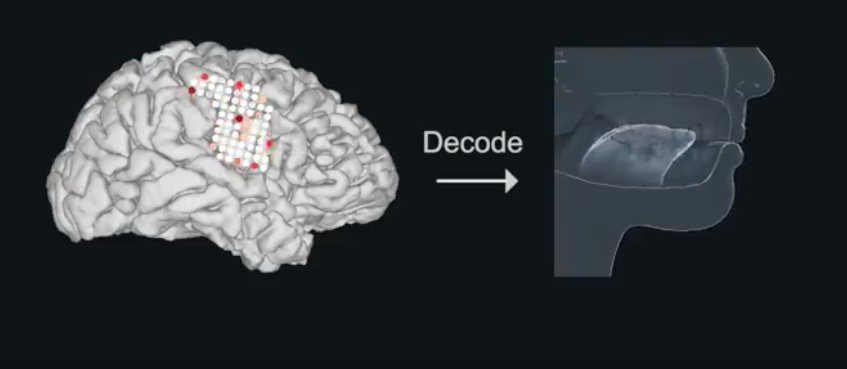
Encoding and decoding speech from the human brain – Edward Chang
Edward reviewed recent progress in understanding how speech is processed by the cerebral cortex. Although he is a neurosurgeon, machine learning is critical to the work he does and he hopes to interact further with the community.
Speaking is a very complex motor skill and requires coordination across more than 100 muscles. It is by far the fastest way that we transfer information, with standard speech at around 120-150 words per minute. The speech motor cortex is the part of the brain that controls the vocal tract, and Edward’s work focusses on understanding how this part of the brain works when we speak.
In his role as a neurosurgeon, Edward works with volunteers who have epilepsy. One area of study involves a procedure whereby an array of electrodes are attached to the brain to try and figure out where the seizures originate. While the team are investigating this, they are also able to study other brain activity. The electrode array allows them to see the parts of the brain that are active when someone speaks. This method is extremely valuable as it gives both spatial resolution and temporal resolution.
In his talk, Edward showed how each electrode represents brain activity for speech. He gave some examples of different speech sounds and showed which electrodes are active when we move our tongues and mouths to make those sounds. Two electrodes in close proximity to each other can have very different encodings of movement.
The team looked at hundreds of electrodes, and sorted and clustered the data. The results represent the different displacement of various parts of the vocal tract and form a “dictionary” for all of the sounds and all of the movements of the vocal tract. This study has a enabled researchers to gain a much better understanding of how this part of the brain controls the vocal tract during speech.
In the next part of his talk, Edward described how he and his team have used these findings to build a speech neuroprosthetic – a system that can translate brain activity (associated with the act of trying to talk, rather than just thoughts) into words. The motivation is to be able to restore speech to people who have lost it as the result of a neurological injury, with brain activity being used to control an artificial vocal tract. You can find out more about this impressive work in their 2019 article Speech synthesis from neural decoding of spoken sentences. Edward shared this video during the talk, which demonstrates the speech synthesiser in action:
In this later work, Neuroprosthesis for Decoding Speech in a Paralyzed Person with Anarthria, which was also touched on during the talk, Edward and colleagues added a natural language model that yielded next-word probabilities given the preceding words in a sequence, to decode full sentences as the participant attempted to say them.
Find out more about Edward’s work here.
Machine learning for molecular science – Cecilia Clementi
Cecilia presented an overview of the different ways machine learning is having an impact in molecular science. She focussed in particular on theoretical and computational biophysics at the molecular scale, and how machine learning is revolutionising molecular simulation techniques.
The talk began with a Paul Dirac quote highlighting that, in order to use quantum mechanics practically, we need to use approximations. The calculations are just too complex and vast to be able to apply to real-world systems. Cecilia sees machine learning as an extra tool which researchers in her field can use to aid them in approximating physical problems.
For problems nowadays, the data we are trying to interpret is very complex, non-linear, and high-dimensional. For many years we were stuck not being able to extract what we needed from the data. With the development of machine learning, we’ve been able to extend what was previously possible with traditional methods. Cecilia mentioned a couple of areas of theoretical and computational biophysics where machine learning has facilitated advances in recent years. The first is protein folding, as we’ve seen recently with AlphaFold. The second concerns atomic-resolution of systems. It is now possible to simulate large molecules for a short time, or small molecules for a longer timescale. There are still huge challenges remaining with both of these. For example, there is a big difference between determining a protein structure from a sequence of amino acids, and understanding the full dynamics and the role of any intermediates.
What Cecilia would like to be able to do in the future is to tackle processes such as exocytosis, a form of active transport and bulk transport in which a cell transports molecules (e.g., neurotransmitters and proteins) out of the cell. The process is orchestrated by a larger number of proteins and involves very dynamic interactions. This is just one of a range of similar systems that scientists would like to understand.
At the moment, the big computational players in this space are molecular dynamics and quantum mechanics. These two theories are not just used for biophysics, but also for many other systems ranging from drug development to finding more efficient materials for solar cells, for example. Cecilia focused on molecular dynamics and how machine learning is revolutionising this approach.
When using molecular dynamics for biophysical systems there are three main challenges that need to be addressed: 1) development of an interatomic potential (or force field), 2) the kinetics, 3) the equilibrium statistical mechanics. In all three aspects, machine learning has been added to the armoury of researchers. An example is in the case of the interatomic potential, which in principle needs us to solve the Schrödinger equation. However, the quantum mechanics method which was traditionally used has been replaced by a neural network.
Despite the advances, Cecilia feels that we are just scratching the surface of what is possible with machine learning in this field. At the moment, researchers are just taking the tools developed for other applications (such as image recognition) and applying them to molecular science. The two questions she raised as areas for progress were: 1) Can we use explainable AI methods to gain insights into the mechanisms that give rise to a particular physiochemical quantity? 2) Can we use machine learning to discover new organising principles and to develop new theories?
Find out more about Cecilia’s research here.
tags: ICML, ICML2021

AUAI is supported by:








