
ΑΙhub.org
Interview with Lily Xu – applying machine learning to the prevention of illegal wildlife poaching

Lily Xu is a PhD student at Harvard University, applying machine learning and game theory to wildlife conservation. She is particularly focused on the prevention of illegal wildlife poaching, and she told us about this interesting, and critically important, area of research.
Could you give a brief overview of what green security is and what this means in the context of your research?
Green security is the challenge of environmental conservation under some unknown threat. The three domains that we focus on are illegal wildlife poaching, illegal logging and illegal fishing. Across all of these settings we have an environmental challenge, which is to preserve our natural ecosystems.
The “security” aspect focuses on protecting these resources. There are people who go to protected areas to extract resources; we must figure out how to most effectively preserve these resources by ranger-conducted patrols. Ranger patrols are the most practised form of protected area management. They patrol on foot, motorbike or boat throughout these areas and try to look for signs of illegal resource extraction, and then take action against it.
In the domain that we work with most closely, which is illegal wildlife poaching, poachers go into protected areas and place snares. They don’t tend to go in with a gun, or other weapon, to shoot an elephant; rather, they’ll place snares, go away for a week or so, then come back to see if they’ve caught anything. It’s a very passive hunting technique. In these large spaces it’s very hard to directly encounter a person. It’s much more feasible to find and remove their snares, because they are there for a longer period of time, and often there are a lot of snares.
Our goal, in green security, is to help rangers more effectively conduct patrols to guard against logging, fishing and poaching.
 Rangers in Srepok Wildlife Sanctuary, Cambodia, in discussion before a patrol.
Rangers in Srepok Wildlife Sanctuary, Cambodia, in discussion before a patrol.
How are you using AI to help deal with this problem?
We have at our disposal many years of historical patrol data. Typically in protected area management, rangers will carry GPS trackers to record where they’ve been and where they’ve seen illegal activity. We want to leverage this historical data to try to make predictions to more intelligently plan patrols in the future. Looking at this historical data enables us to understand patterns in poaching behaviour (for example, where rangers find snares) and try to work out if there are any poaching hotspots that they are missing.
These parks are very large. For example, one park that we worked very closely with in Cambodia, called Srepok Wildlife Sanctuary, is over 4,000 square kilometres – about the size of Rhode Island! For this entire park they have only 72 rangers. So, there is a problem of limited resources, and they need to strategically allocate those resources. Many areas of the park are underexplored or haven’t even been visited.
We’re trying to help rangers identify underexplored regions that are poaching hotspots. We do so by correlating the historical patrol observations with geographic information about the land (such as elevation, land cover, animal density, where the villages are, the roads, rivers, waterholes). This set of geographic features become the covariants upon which we can train a supervised learning model.
Using past data we can find out what features the areas with and without snares had. We can then use this information to determine whether areas of the park that are underexplored, but which have similar features to those of known areas, are likely to have snares or not.
There are two strands to your research. Firstly, this remote sensing of features of the environment in protected areas. Secondly, there are the strategies for optimising ranger patrols, where you use multi-armed bandit and reinforcement learning techniques. Do both aspects work in tandem?
We treat our work on AI for poaching prevention as a two-stage process. Our first basic challenge is to do supervised learning – the remote sensing part. In this, we’re making the assumption that poacher behaviour is static, so that what has happened in the past year is going to be the same as what’s going to happen next month. That enables us to learn these patterns and leverage our historical data.
We recognize that a fundamental assumption we’re making with this supervised learning process is assuming that we have sufficient historical data with which to learn a good model. But, that’s not always the case. Some parks, like Srepok Wildlife Sanctuary in Cambodia, have many years of historical patrols. But, other parks are only just starting up ranger patrols and have only a few months of data. The challenge is: if we have limited information, we don’t just want to go to the hotspots we know exist; we also want to ensure that we’re exploring unseen areas. It becomes a challenge of trying to balance between proactively exploring new areas, while at the same time ensuring that we’re not ignoring known hotspots. This becomes a fundamental trade-off in online learning, a subset of machine learning which is often addressed with multi-armed bandits. This challenge was the main inspiration for our AAAI paper on dual-mandate patrols [For this work, the authors received a AAAI-21 best paper runners-up prize]. This dual-mandate is both exploring under-visited areas while also ensuring that we are visiting those hotspots that we’ve already identified. We’ve developed this model for online learning, in which we’re having to sequentially plan in order to proactively collect data.
Moving one further step in complexity, now we’re asking what happens if the poacher behaviour is not static. This is a reasonable assumption, particularly in parks where there are more patrols, and where poachers move to different areas of the park when they realise their snares are getting seized by the patrols. This dynamic environment, in which the poachers are actually responding to our actions, drives us to do sequential planning knowing that the actions we take today will impact what the poachers are doing tomorrow.
In addressing this problem, we first started with an analysis of real-world poaching data that we had for two parks in Uganda. We used these data to try to understand this effect, and how the dynamic environment was changing. We were able to identify deterrents, and from that we built a reinforcement learning model in which we’re doing sequential planning. Essentially, we’re planning today’s actions with the understanding that they will change what the patrols are next week.
 Visiting Srepok Wildlife Sanctuary in 2019.
Visiting Srepok Wildlife Sanctuary in 2019.
Did you work with the rangers to develop the models?
Yes, absolutely – working with folks on the ground is really a core tenet of the kind of research that we do in my group. All of our research questions really come from long-term conversations and interactions with these park rangers. We’d have weekly check-ins to let them know about the latest updates to the model, which were often based on their feedback. We’d ask them what they thought of the latest predictions, and asked if there was anything missing.
Through those conversations we were able to identify things that we would never have thought of. For example, they pointed out that the majority of snares are found near waterholes, because that’s where you have a high density of animals. We already had information about rivers, but waterholes in particular are areas where animals tend to congregate. That prompted us to add waterholes as one of the features.
We also learned that there is strong seasonality in Cambodia – a rainy season and a dry season. During the dry season, many of the rivers dry up which means that some areas of the park that were previously inaccessible during the rainy season, because there was a huge river crossing, suddenly become accessible, because you can now walk through this dried-up river. We’ve seen that the poaching, and even where animals are located, change between rainy and dry season. This inspired us to build separate machine learning models for both seasons.
All of these modelling details and processes came through this sustained, long-term engagement with the park managers.
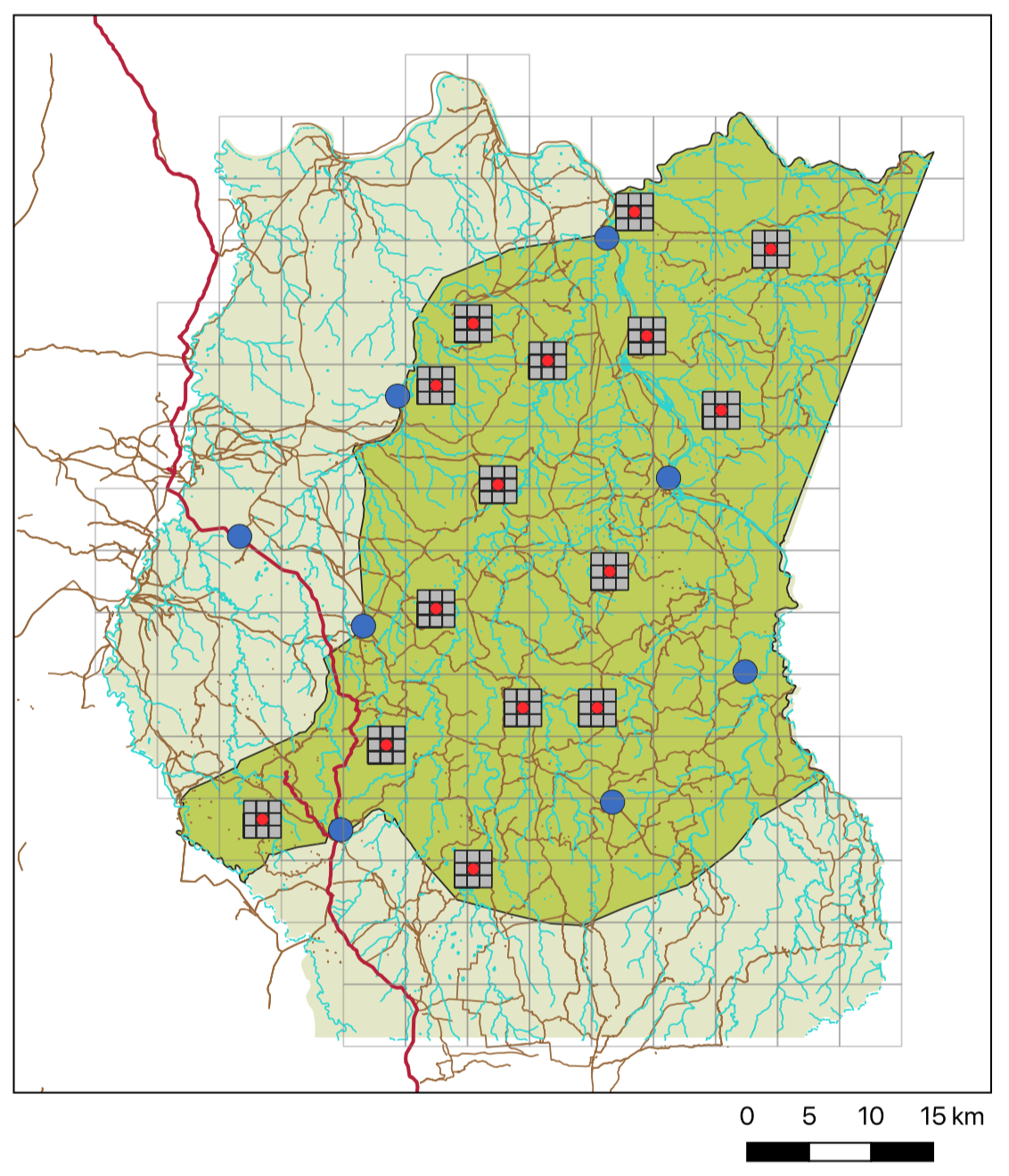 A sample of field test regions used in Srepok Wildlife Sanctuary, Cambodia.
A sample of field test regions used in Srepok Wildlife Sanctuary, Cambodia.
Tell us a bit about the field tests that you conducted.
Following on from our collaboration with the rangers to build the models, we went through the process of deploying field tests to evaluate how well these predictions were doing on the ground.
To carry out these tests, we first made predictions. To ensure that we weren’t just going to known hotspots, we selected previously underexplored areas. We then picked a subset that were predicted to be high risk, a subset that were predicted to be medium risk, and a subset that were predicted to be at low risk of poaching. We sent 15 areas, five in each category, to the rangers and asked them to conduct a month of patrols in those areas. We didn’t tell them the categorisation to keep the experiment blind. We found that the rangers found many more snares in the high-risk areas than in the medium-risk areas, and almost no snares in the low-risk areas. That really validated the ability of our model to discriminate between high- and low-risk areas.
In 2019, we even spent a week in Cambodia visiting the rangers, and accompanying them on a short motorbike patrol. We saw what it was like on the ground which was an incredible experience.
We were really excited about the results of our field test, as were the rangers in Cambodia, and also some folks at WWF who lead more large-scale global poaching prevention initiatives. As a result of all this, we’re working on scaling our algorithms to a more global level. We’re been working with SMART, which is a partnership that produces conservation software that’s used for conservation management in many protected areas around the world. It’s currently in use in over 1,000 protected areas across 80 countries.
The aim is that these predictive algorithms, the same ones that we used in Srepok Wildlife Sanctuary, become available for parks all over the world. All we have to do is take the data that they already have on SMART, about historical patrols and geographical feature data, and run the model. The parks will be able to set their options. For example, they can decide whether they want to predict, for example, snares, illegal logging, or illegal campsites. That will enable them to run these models automatically.
We’re doing a lot of work behind the scenes to make this production-level ready and accessible to a larger number of parks. This is all set up with Microsoft Azure for cloud computing, with support from the Microsoft AI for Good initiative, so even if they don’t have resources on their local computer, all of this can be run on the cloud, and we just send the prediction results back to them. That will help alleviate challenges with computing limitations.
We have an automatic pipeline in place to take publicly available, free, remote sensing data, and use it to augment the features that the parks have. Sometimes parks don’t have GIS experts who are able to create geographic information about the rivers, roads, elevation and so on. By integrating with these publicly available satellite imagery platforms, we can automatically augment the set of geographic characteristics that we’re able to incorporate. Therefore, we can build stronger, more effective models for these parks.
 Accompanying rangers on a patrol.
Accompanying rangers on a patrol.
What are your future plans for this work?
A project that we recently finished considers questions of fairness in this domain. In the past, our focus has been to find as many snares as possible. However, in all of these parks there are animals that are more vulnerable than others. We’ve all heard of the IUCN Red List of Threatened Species. This ranks various animals in terms of how endangered they are, and really helps us prioritise which animals have the most urgent conservation needs.
Looking for snares is a hard challenge on its own, so it’s important to focus on that. But, in areas where we have more comprehensive patrols and more understanding of the animals and patrol patterns, then it makes sense for us to focus on protecting the animals that are more vulnerable. What we’ve seen in Srepok Wildlife Sanctuary is that the locations of the elephants actually differ from the locations of the other animals that are poached. For instance, the elephants are concentrated in one area, whereas the deer and wild pig are concentrated in other areas. It could be that there’s more snaring in the area with the deer and wild pigs, but the snares that are threatening the elephants are in some ways even more pressing. If we can remove one elephant snare, instead of, say, three deer snares, perhaps we want to make this trade-off, because of how vulnerable elephants are. In our new work we’re considering how to more strategically allocate patrols based on this question of fairness across animal species depending on who is most vulnerable.
What inspired you to get into this field?
For a very long time, I have believed that sustainability is the most pressing issue of our generation and this is a personal passion and commitment of mine. I try to be very informed about environmental challenges, I’ve been vegetarian for almost all of my life, for environmental reasons, and I try to take actions in my life that are more sustainable. I always thought that this was just something I could do in my personal life, and as a computer scientist I would work on more technical problems. But then I realised in college that there are actually people who are doing both of these at the same time. My advisor, Milind Tambe, is one of those people. After learning about work on AI for conservation, I thought it would be an absolute dream to work on these problems. I’m just very grateful to have had the opportunity to have this be a focus of my PhD, and to also have opportunities to help grow this community of people working on computer science for environmental challenges, through organising events and workshops and research groups. I’ve definitely noticed that there are a lot more people, particularly those that are current undergraduates in college, who are interested in working on computer science for sustainability.
Are you involved in any other related projects or initiatives?
Yes, one organisation I’m strongly involved with is Mechanism Design for Social Good (MD4SG). We have a working group on environment and climate which brings together researchers and practitioners in environmental challenges. We meet biweekly — if people are interested in AI for Sustainable Development Goals, this group might be a useful network for them to get involved in. It’s a good opportunity to meet and network with others in this space.
Find out more
Research papers:
Enhancing Poaching Predictions for Under-Resourced Wildlife Conservation Parks Using Remote Sensing Imagery, Rachel Guo, Lily Xu, Drew Cronin, Francis Okeke, Andrew Plumptre, Milind Tambe, [NeurIPS ML4D 2020]. PDF
Dual-Mandate Patrols: Multi-Armed Bandits for Green Security, Lily Xu, Elizabeth Bondi, Fei Fang, Andrew Perrault, Kai Wang, Milind Tambe, [AAAI 2021]. PDF. For this work, the authors received a AAAI-21 best paper runners-up prize.
Robust Reinforcement Learning Under Minimax Regret for Green Security, Lily Xu, Andrew Perrault, Fei Fang, Haipeng Chen, Milind Tambe, [UAI 2021]. PDF
Visit the MD4SG working group website.
Lily Xu is a PhD student studying computer science at Harvard University, advised by Prof. Milind Tambe. Her research applies machine learning and game theory to wildlife conservation. She has focused on the prevention of illegal wildlife poaching; her work on predictive models to prevent poaching is being deployed to 1,000 protected areas around the world on the SMART conservation software, in collaboration with the SMART partnership and Microsoft AI for Earth. She is passionate about reducing her negative impact on the environment and increasing her positive impact on society.
tags: Focus on life on land, Focus on UN SDGs

AUAI is supported by:








