
ΑΙhub.org
RoboNet: A dataset for large-scale multi-robot learning
By Sudeep Dasari
This post is cross-listed at the SAIL Blog and the CMU ML blog.
In the last decade, we’ve seen learning-based systems provide transformative solutions for a wide range of perception and reasoning problems, from recognizing objects in images to recognizing and translating human speech. Recent progress in deep reinforcement learning (i.e. integrating deep neural networks into reinforcement learning systems) suggests that the same kind of success could be realized in automated decision making domains. If fruitful, this line of work could allow learning-based systems to tackle active control tasks, such as robotics and autonomous driving, alongside the passive perception tasks to which they have already been successfully applied.
While deep reinforcement learning methods – like Soft Actor Critic – can learn impressive motor skills, they are challenging to train on large and broad data that is not from the target environment. In contrast, the success of deep networks in fields like computer vision was arguably predicated just as much on large datasets, such as ImageNet, as it was on large neural network architectures. This suggests that applying data-driven methods to robotics will require not just the development of strong reinforcement learning methods, but also access to large and diverse datasets for robotics. Not only can large datasets enable models that generalize effectively, but they can also be used to pre-train models that can then be adapted to more specialized tasks using much more modest datasets. Indeed, “ImageNet pre-training” has become a default approach for tackling diverse tasks with small or medium datasets – like 3D building reconstruction. Can the same kind of approach be adopted to enable broad generalization and transfer in active control domains, such as robotics?
Unfortunately, the design and adoption of large datasets in reinforcement learning and robotics has proven challenging. Since every robotics lab has their own hardware and experimental set-up, it is not apparent how to move towards an “ImageNet-scale” dataset for robotics that is useful for the entire research community. Hence, we propose to collect data across multiple different settings, including from varying camera viewpoints, varying environments, and even varying robot platforms. Motivated by the success of large-scale data-driven learning, we created RoboNet, an extensible and diverse dataset of robot interaction collected across four different research labs. The collaborative nature of this work allows us to easily capture diverse data in various lab settings across a wide variety of objects, robotic hardware, and camera viewpoints. Finally, we find that pre-training on RoboNet offers substantial performance gains compared to training from scratch in entirely new environments.

Our goal is to pre-train reinforcement learning models on a sufficiently diverse dataset and then transfer knowledge (either zero-shot or with fine-tuning) to a different test environment.
Collecting RoboNet
RoboNet consists of 15 million video frames, collected by different robots interacting with different objects in a table-top setting. Every frame includes the image recorded by the robot’s camera, arm pose, force sensor readings, and gripper state. The collection environment, including the camera view, the appearance of the table or bin, and the objects in front of the robot are varied between trials. Since collection is entirely autonomous, large amounts can be cheaply collected across multiple institutions. A sample of RoboNet along with data statistics is shown below:

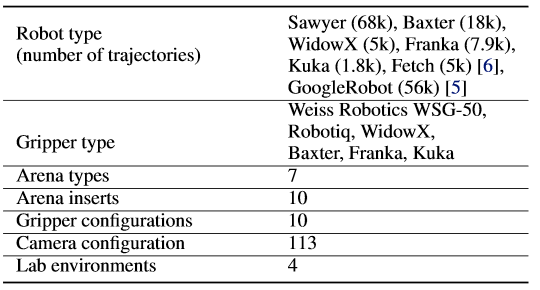
A sample of data from RoboNet alongside a summary of the current dataset. Note that any GIF compression artifacts in this animation are not present in the dataset itself.
How can we use RoboNet?
After collecting a diverse dataset, we experimentally investigate how it can be used to enable general skill learning that transfers to new environments. First, we pre-train visual dynamics models on a subset of data from RoboNet, and then fine-tune them to work in an unseen test environment using a small amount of new data. The constructed test environments (one of which is visualized below) all include different lab settings, new cameras and viewpoints, held-out robots, and novel objects purchased after data collection concluded.

Example test environment constructed in a new lab, with a temporary uncalibrated camera, and a new Baxter robot. Note that while Baxters are present in RoboNet that data is not included during model pre-training.
After tuning, we deploy the learned dynamics models in the test environment to perform control tasks – like picking and placing objects – using the visual foresight model based reinforcement learning algorithm. Below are example control tasks executed in various test environments.

Kuka can align shirts next to the others

Baxter can sweep the table with cloth

Franka can grasp and reposition the markers

Kuka can move the plate to the edge of the table

Baxter can pick up and reposition socks

Franka can stack the towel on the pile
Here you can see examples of visual foresight fine-tuned to perform basic control tasks in three entirely different environments. For the experiments, the target robot and environment was subtracted from RoboNet during pre-training. Fine-tuning was accomplished with data collected in one afternoon.
We can now numerically evaluate if our pre-train controllers can pick up skills in new environments faster than a randomly initialized one. In each environment, we use a standard set of benchmark tasks to compare the performance of our pre-trained controller against the performance of a model trained only on data from the new environment. The results show that the fine-tuned model is ~4x more likely to complete the benchmark task than the one trained without RoboNet. Impressively, the pre-trained models can even slightly outperform models trained from scratch on significantly (5-20x) more data from the test environment. This suggests that transfer from RoboNet does indeed offer large performance gains compared to training from scratch!
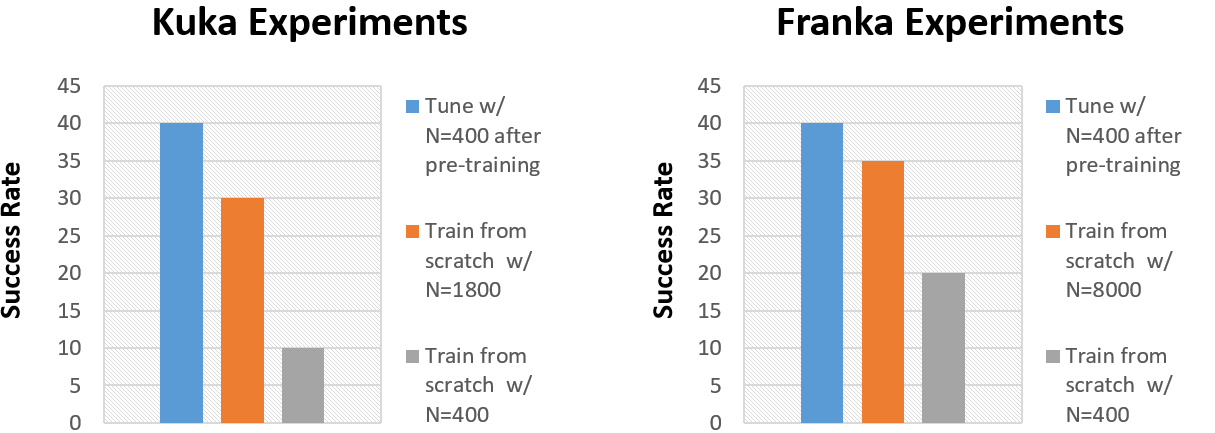
We compare the performance of fine-tuned models against their counterparts trained from scratch in two different test environments (with different robot platforms).
Clearly fine-tuning is better than training from scratch, but is training on all of RoboNet always the best way to go? To test this, we compare pre-training on various subsets of RoboNet versus training from scratch. As seen before, the model pre-trained on all of RoboNet (excluding the Baxter platform) performs substantially better than the random initialization model. However, the “RoboNet pre-trained” model is outperformed by a model trained on a subset of RoboNet data collected on the Sawyer robot – the single-arm variant of Baxter.
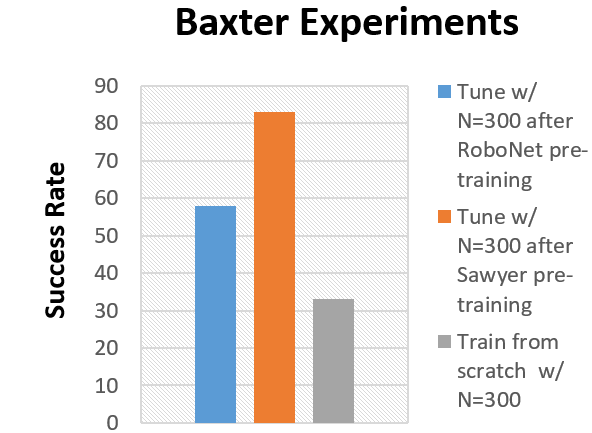
Models pre-trained on various subsets of RoboNet are compared to one trained from scratch in an unseen (during pre-training) Baxter control environment
The similarities between the Baxter and Sawyer likely partly explain our results, but why does simply adding data to the training set hurt performance after fine-tuning? We theorize that this effect occurs due to model under-fitting. In other words, RoboNet is an extremely challenging dataset for a visual dynamics model, and imperfections in the model predictions result in bad control performance. However, larger models with more parameters tend to be more powerful, and thus make better predictions on RoboNet (visualized below). Note that increasing the number of parameters greatly improves prediction quality, but even large models with 500M parameters (middle column in the videos below) are still quite blurry. This suggests ample room for improvement, and we hope that the development of newer more powerful models will translate to better control performance in the future.

We compare video prediction models of various size trained on RoboNet. A 75M parameter model (right-most column) generates significantly blurrier predictions than a large model with 500M parameters (center column).
Final Thoughts
This work takes the first step towards creating learned robotic agents that can operate in a wide range of environments and across different hardware. While our experiments primarily explore model-based reinforcement learning, we hope that RoboNet will inspire the broader robotics and reinforcement learning communities to investigate how to scale model-based or model-free RL algorithms to meet the complexity and diversity of the real world.
Since the dataset is extensible, we encourage other researchers to contribute the data generated from their experiments back into RoboNet. After all, any data containing robot telemetry and video could be useful to someone else, so long as it contains the right documentation. In the long term, we believe this process will iteratively strengthen the dataset, and thus allow our algorithms that use it to achieve greater levels of generalization across tasks, environments, robots, and experimental set-ups.
For more information please refer to the the project website. We’ve also open sourced our code-base and the entire RoboNet dataset.
Finally, I would like to thank Sergey Levine, Chelsea Finn, and Frederik Ebert for their helpful feedback on this post.
This article was initially published on the BAIR blog, and appears here with the authors’ permission.
This blog post was based on the following paper:
- RoboNet: Large-Scale Multi-Robot Learning.
S. Dasari, F. Ebert, S. Tian, S. Nair, B. Bucher, K. Schmeckpeper, S. Singh, S. Levine, C. Finn.
In Conference on Robot Learning, 2019.

AIhub is supported by:








