
ΑΙhub.org
Explaining machine learning models for natural language
By Sarah Wiegreffe and Yuval Pinter
Natural language processing (NLP) is the study of how computers learn to represent and make decisions about human communication in the form of written text. This encompasses many tasks, including automatically classifying documents, using machines to translate between languages, or designing algorithms for writing creative stories. Many state-of-the-art systems for NLP rely on neural networks – complex machine learning models that achieve incredible performance but are difficult for humans to interpret and understand [1].
In the real world, many NLP systems can have a large impact on humans. Consider, for example, a system designed to read a prisoner’s court documents and arrest record and recommend whether or not they should be released on bail. If the system was found to be making a decision based on the words “white” or “black” (which are strongly indicative of race), this would be immensely problematic and unfair [2]. Another example is computer programs that assist doctors in making diagnoses by reading the text of a patient’s clinical record. The physicians using this clinical decision support system need to understand the underlying characteristics of the patient upon which the machine learning algorithm is basing its prediction [3].
This human understanding often requires “model explainability”: models that can explain their decisions. There are two important and distinct concepts under this umbrella. One is about how humans perceive a model’s decisions, and the other is about understanding the model’s reasoning process. We call the first plausible, and the second faithful.
Plausible explanations are nice for building user trust, such as building rapport between a human and an AI system [4]. However, they don’t tell us much about the underlying algorithmic decision-making process, which is desperately needed as seen in the examples above. Faithful explainability, on the other hand, is centered on explaining a model’s decisions in a way that reflects what actually occurred as the model was making them [5]. This topic has become so important that NLP conferences now have a track and workshop dedicated to it [6,7,8].
Here’s an example of the distinction: an AI system could predict that it’s going to rain today. If we inquire how it knew this, its explanation might involve ocean streams, atmospheric pressure, or cloud formations. Alternatively, it could explain to us that the god of thunder is angry. This is significantly less plausible than the other answers, and thus less satisfying. However, if the AI system was truly basing its predictions on this belief, it would be crucial for the system designer to know that. We could work to correct its faulty representation of the world, to teach it not to rely on mythology for predictions in the future. The “god of thunder” explanation is the faithful explanation of the model, despite not being the plausible one.
In our paper [9], we present an argument that faithful and plausible explanations are different things that prior work has declined to delineate, and we encourage machine learning researchers to be explicit about which type they are investigating.
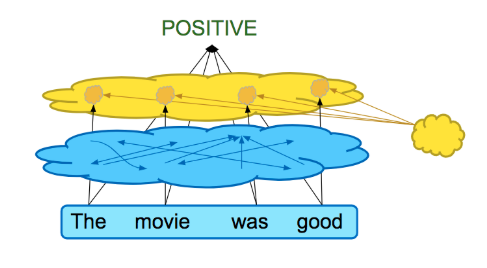
We also investigate one popular method for faithfully explaining neural NLP models: attention weights. Attention is a highly successful model architecture component used in machine learning. It produces an intermediate set of values called weights, which correspond to locations of individual words in a given input: a higher attention weight means that (a vector artifact corresponding to the location of) that word was more important for the model’s prediction. For example, if the goal is to predict the label “five stars” for a movie review, the model might learn to place larger attention weights on the vectors representing words “loved” and “good” rather than “the”, “and”, or “movie”, which don’t really indicate much about the author’s feelings towards the film. See Figure 1 for an example of attention weights on a movie review.

Oftentimes, as in Figure 1, attention scores are presented to the user as a type of heatmap over the original input. However, this can be misleading. Particularly, as can be seen schematically in Figure 2, there is a lot of contextualization happening (denoted by the arrows). Thus, the model may learn vectors that are combinations of many different words before the attention scores are even applied!
For example, the vector aligned with the word “movie” may in fact be only 80% constructed from “movie”, with 20% coming from “the” and “good”. In this case, it would be misleading to say that a high attention weight on this vector means that the word “movie” (and only the word “movie”) is important. In our paper, we show this.
Also, there may be cases in which multiple, very different, attention weights exist that still allow the model to make the same prediction. When this happens, our notion of what the attention weights such as Figure 1 are telling us about the model’s prediction is questioned. In our paper, we show that while these different attention weights can be found, they’re not necessarily as prevalent as others have claimed.
We ultimately define 4 criteria (and 4 tests) that researchers can use to discern whether attention is a good way for explaining their model’s decisions. We find interesting results that contradict some of the findings of prior work, namely that attention weights work better (or worse) for faithful explanation depending on the specific task or dataset. Thus, we really can’t say with certainty what attention weights are telling us about models in general, and caution against a one-size-fits-all stance. We encourage researchers to use our methods to reach individual conclusions about whether attention can provide faithful explanation for a given-task setting and open-source our code for this purpose.
For more details see the paper here: Attention is not not Explanation, Wiegreffe and Pinter (equal contribution). The paper was accepted to the Conference on Empirical Methods in Language Processing (EMNLP 2019).
We also discuss the paper in detail in two recorded talks:
Sarah as a guest speaker at the University of Southern California’s NLP Seminar (paper discussed from 7:45).
Yuval as a guest speaker at AI Socratic Circle’s “ML Papers Explained” (paper discussed from 24:00).
You can also check out Yuval’s Medium post on some of the arguments here laid out in more detail.
Connect with Sarah at @sarahwiegreffe and Yuval at @yuvalpi for further discussions and updates.
Citations
[1] Deep learning, Nature, 2015.
[2] The Age of Secrecy and Unfairness in Recidivism Prediction.
[3] What Clinicians Want: Contextualizing Explainable Machine Learning for Clinical End Use, MLHC Conference 2019.
[4] Rationalization: A neural machine translation approach to generating natural language explanations, AIES 2018.
[5] The Mythos of Model Interpretability, Queue 2018.
[7] Analyzing and interpreting neural networks for NLP: A report on the first BlackboxNLP workshop.
[8] BlackBoxNLP Workshop at EMNLP 2020.
[9] Attention is not not Explanation, EMNLP 2019.
About the authors
 Sarah Wiegreffe is a PhD student in the School of Interactive Computing at Georgia Institute of Technology, studying computer science. Her research interest is in natural language processing and machine learning, with a focus on interpretability, fairness and robustness.
Sarah Wiegreffe is a PhD student in the School of Interactive Computing at Georgia Institute of Technology, studying computer science. Her research interest is in natural language processing and machine learning, with a focus on interpretability, fairness and robustness.
Connect with Sarah at @sarahwiegreffe.
 Yuval Pinter is a Computer Science PhD student in the School of Interactive Computing at Georgia Institute of Technology. He works on Natural Language Processing (NLP), with his interests including lexical semantics, word representation, morphology, interpretability, syntactic parsing, social factors affecting language, and user-generated content.
Yuval Pinter is a Computer Science PhD student in the School of Interactive Computing at Georgia Institute of Technology. He works on Natural Language Processing (NLP), with his interests including lexical semantics, word representation, morphology, interpretability, syntactic parsing, social factors affecting language, and user-generated content.
Connect with Yuval at @yuvalpi.

AIhub is supported by:








