
ΑΙhub.org
Privacy-driven speech transformation with adversarial learning
By Brij Mohan Lal Srivastava, Nathalie Vauquier and COMPRISE
This post introduces the concept of speech representation and explains the use of an adversarial approach to train speech-to-text systems. The basics of privacy within the context of speech processing are also considered.
Speech representation
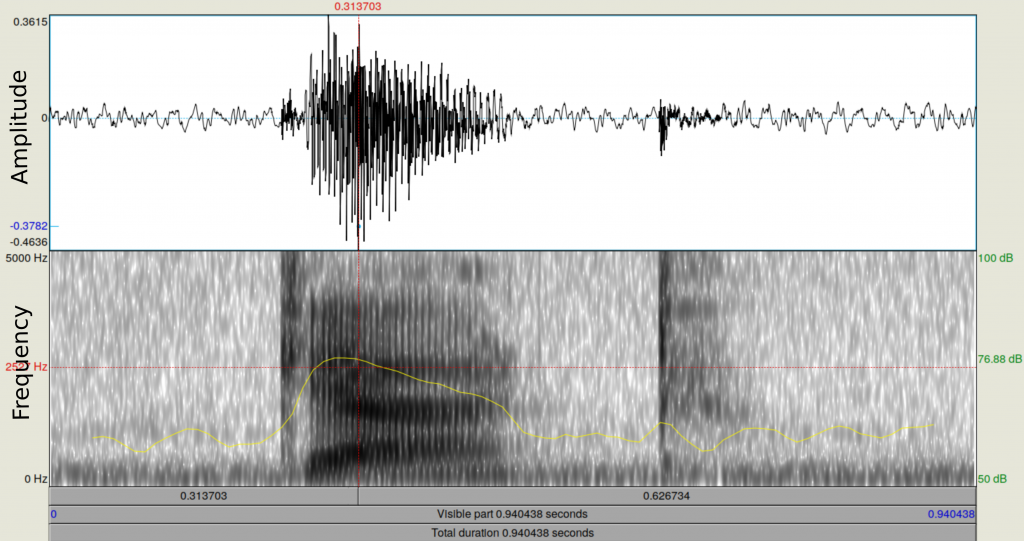
In order to process speech using a computer, a microphone output is collected and represented as a waveform. The figure above shows a snapshot from the Praat software (free to download) which is commonly used for speech analysis. The top image shows the waveform of a male speaker saying “cat”. The horizontal axis represents time.
Analyzing a waveform is difficult because it conveys one-dimensional information. Hence, we use a Fourier transform to decompose it into its frequency components and to compute the corresponding intensities. The bottom image shows the resulting representation, known as the spectrogram, of the waveform above. The horizontal axis represents time and the vertical axis represents frequency, with darker shades corresponding to higher intensity. The yellow curve, which indicates total intensity, peaks around the darker region. This representation is more expressive than the waveform.
The spectrogram representation is used extensively in speech research since it clearly displays the perceptual difference between various speech sounds. For instance, it is used as an input by most speech-to-text systems (a key component of these systems is recognition of the sequence of phonemes pronounced, e.g., cat is pronounced using three phonemes: K AE T) or speaker recognition systems (if there is a single speaker, the speaker’s identity remains fixed over time). Another important aspect is that the recording is not processed at once, but is divided into equal length overlapping segments. These segments are called frames. Relevant features are extracted from each frame and then the sequence of features is processed by algorithms.
Encoder-decoder
Now, let us briefly introduce the concept of utility vs. privacy with respect to speech processing. We are interested in preserving the privacy of individuals but we do not want to distort speech to the extent where it loses all the utility. For us, utility is defined in terms of automatic speech recognition (ASR, a.k.a. speech-to-text) performance. Privacy is defined in terms of speaker identification. Ultimately the transformed speech must be usable for transcription, annotation or other non-sensitive attribute retrieval purposes. Suppose an attacker got hold of a few audio samples coming through an insecure channel. These samples must be rendered neutral so that the original speaker is not uniquely identifiable. We propose to use the principles of privacy-by-design in combination with suitable speech transformation techniques to render the transmitted speech neutral towards such privacy attacks.
Note that it is not necessary that this transformation always outputs a speech waveform. It may work in a suitable representation domain and produce representations (such as spectrograms or feature sequences) which lack speaker characteristics but are still rich in linguistic content. This idea leads to the inception of our first approach: speaker-adversarial ASR. Let us first understand how ASR works.
Broadly speaking, ASR takes a spectrogram as input and produces the text being spoken in the utterance. In our study we use an end-to-end speech recognition framework. The following illustration displays the major components of this framework.
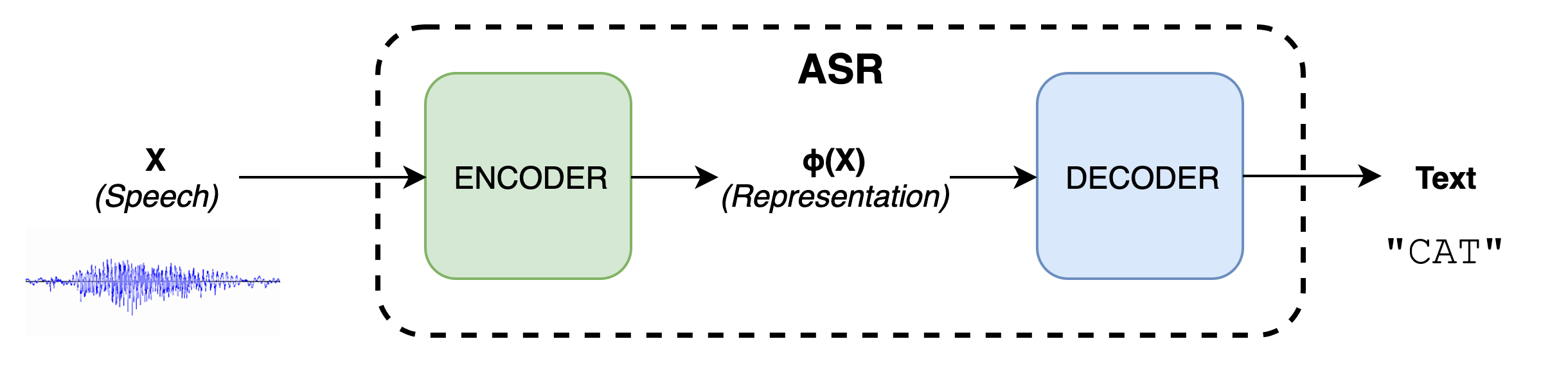
The speech waveform is first converted into spectral features such as the spectrogram (X). It passes through a neural network (encoder) which transforms the features into another set of features ?(X). These features are rich in linguistic content so that text can be easily decoded from them. The decoder parses these features and produces a graph; the best path in this graph indicates the most probable text output.
Now that we know the basic principle, let’s dive into the details of the transformation which enables us to produce a suitable ?(X).
Adversarial approach
The basic idea behind this approach is the “adversary”. We simulate an adversary within the speech recognition framework during training time. This adversary will learn all the attributes in ?(X) which are relevant to recognize a speaker. Once the adversary has learnt well, we derive a feedback signal from it to identify and remove such features from the encoder and effectively from ?(X). This technique is called gradient reversal and has been used to make the representation invariant to a particular attribute.
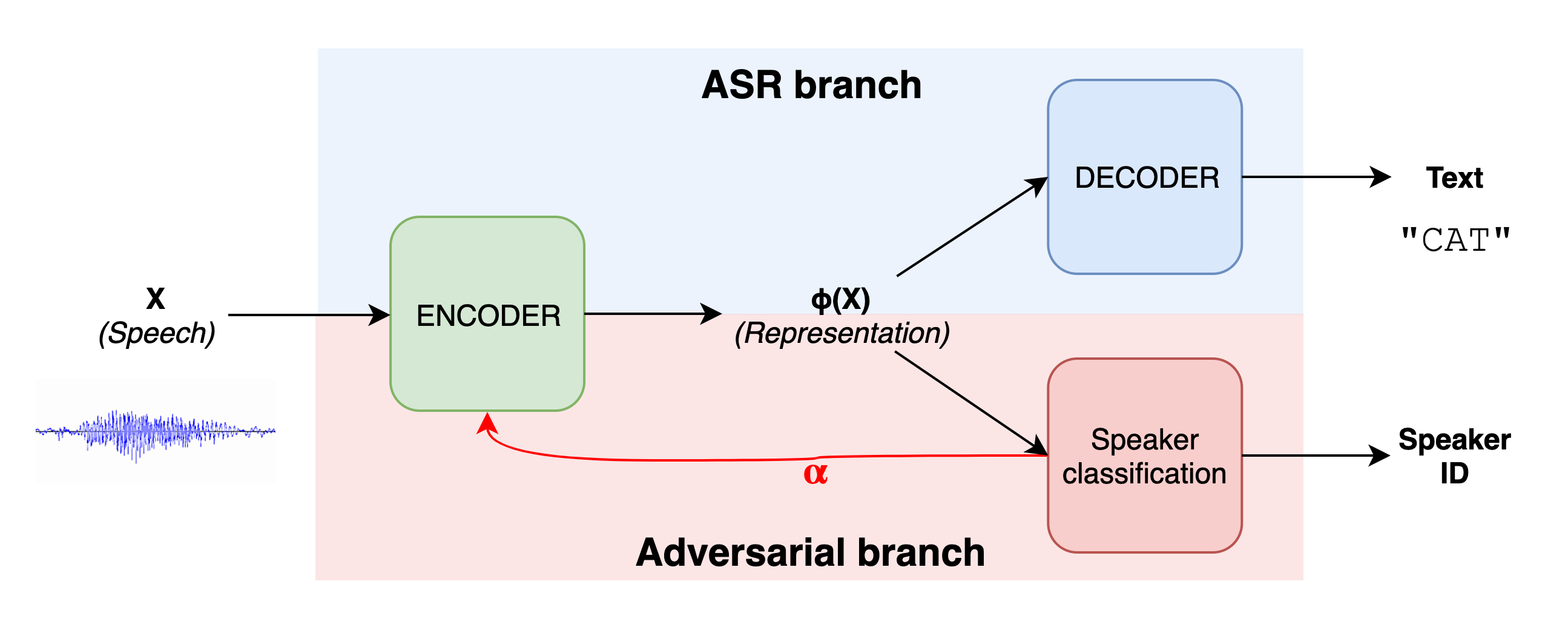
The adversary must learn the features relevant to this attribute by classifying them with high accuracy. After removing the speaker-specific features from the encoder, the whole network is trained for several iterations. This can be seen as a game between the encoder and the adversary: the encoder tries to fool the adversary by removing speaker-specific attributes and the adversary tries to adapt quickly to correctly classify the speaker again. After a few iterations, when the network has converged to produce a stable privacy vs. utility tradeoff, the encoder can be used to remove speaker information from any speech signal. The resulting representation can be used for ASR decoding, and it can also be shared after further sanitization (e.g., sensitive text removal) for ASR training.
In order to evaluate the degree of anonymization achieved by this technique, we follow two different speaker recognition schemes: closed-set vs. open-set. The closed-set scheme measures the speaker classification accuracy when the test speaker is present in the ASR training set with different linguistic content. This scheme was used in previous studies to measure privacy. In our work, we introduce an open-set scheme which uses the idea of speaker verification (a.k.a. authentication). The speaker is enrolled using a few seconds of speech, then trials are conducted using the test data. These speakers are not present in the training set. Here are the results of our experiments.
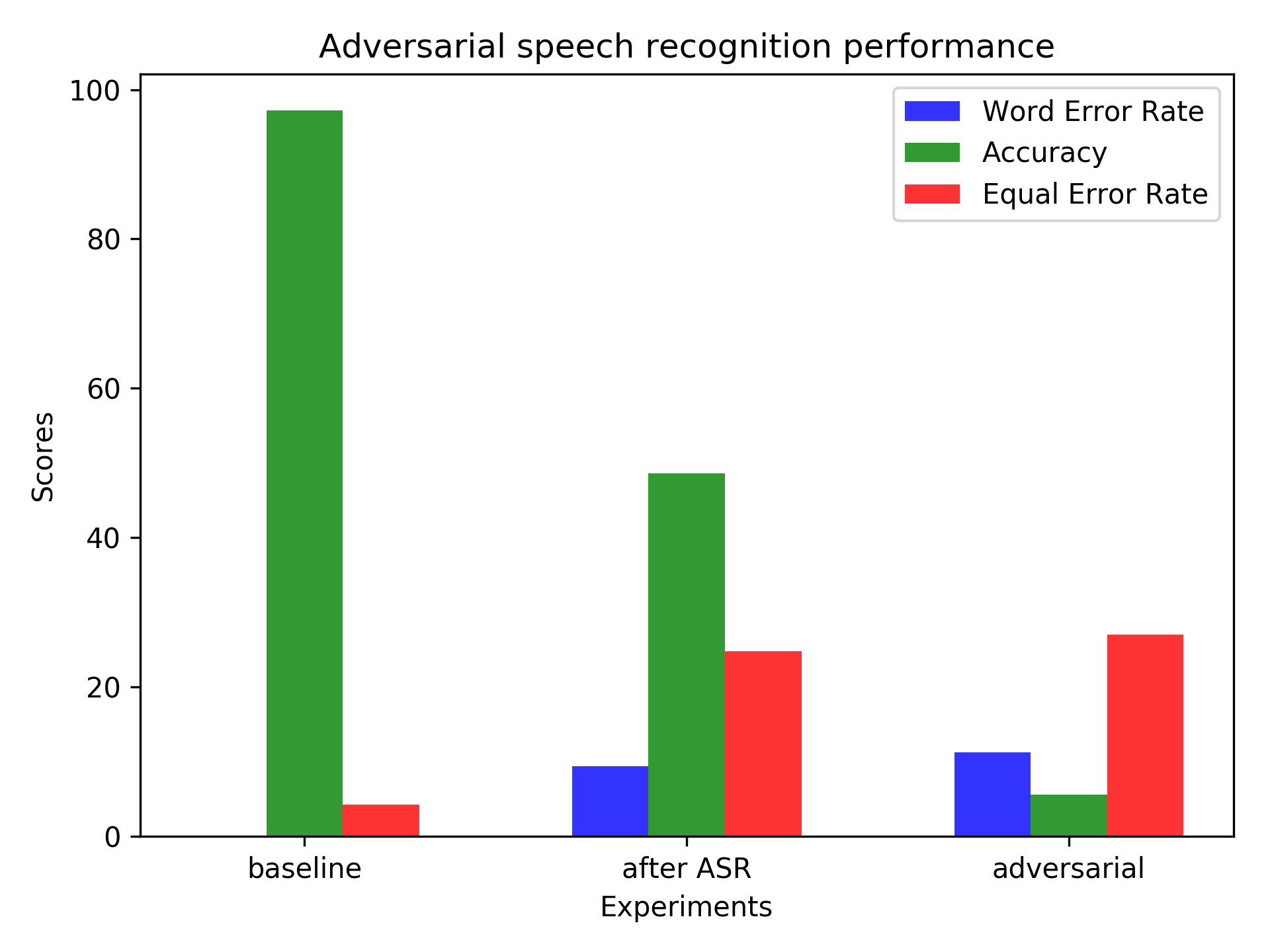
The green bar shows the speaker recognition (closed-set) accuracy which has, intuitively, decreased after ASR training and then decreased further after the adversarial training. This shows that the encoder is able to fool the adversary, and the speaker information is being removed from the representation. The blue bar shows the word error rate (WER) which measures the utility of the anonymized representations. We notice that the utility is more or less stable before and after adversarial training. The red bar indicates the equal error rate (EER) which is the average verification error while recognizing unseen speakers (open-set). We notice that the error increases by more than 20% after ASR training, but adversarial training has only a slight affect on it. This shows that a simple version of adversarial training does not generalize well over unseen speakers but is highly effective for speakers known during training.
We have described the basics of privacy within the context of speech processing, and presented our adversarial approach for training the speech recognition system. We show that simple adversarial training does not generalize well for unseen speakers and it requires further research to achieve a stable privacy guarantee.
AIhub is supported by:








