
ΑΙhub.org
Voice assistants – strategies for handling private information

In the latest in this series of posts, researchers from the EU-funded COMPRISE project write about privacy issues associated with voice assistants. They propose possible ways to maintain the privacy of users whilst ensuring that manufacturers can still access the quality usage data vital for improving the functionality of their products.
Professor Marc Tommasi talks about the COMPRISE project:
Is There Anything Else I Should Know About You?
“Tell me what you read and I tell you who you are.” – Pierre de La Gorce
Voice assistants, such as Alexa, Siri, or Google Assistant, are becoming increasingly popular. Some users are, however, worried about their vocal interactions with these devices being stored in the cloud, together with a textual transcript of every spoken word. But is there an actual threat associated with the collection of these data? And if so, could such threats be prevented?
When companies have access to lots of their users’ dialog data, they can use it to make their voice assistants work better. So, that’s great news for the users, isn’t it? Well, for one, the recordings of a user’s voice could be abused to impersonate them using artificial neural networks. While reputable companies are usually not in the identity-theft business, this might become a more realistic threat in cases where the stored user recordings are leaked to the wrong people, for instance, after a successful hack.
But it’s not just the sound of your voice that is potentially at risk of misuse here. What you say also reveals a lot about you. Saying “turn on the living room lights” in a smart home today may be considered rather harmless, but future versions of voice assistants will be increasingly capable. They will engage in more involved conversations with the user and assist with complex tasks such as booking your next holiday trip from start to finish, including choosing your hotel, booking the flights, and planning leisure time activities. From the user’s perspective, such interactions will likely contain quite a lot of private information.
To illustrate, let’s focus on five simple types of entities that we might find in a conversation with a voice assistant: people, organizations, locations, and dates and times. Here’s an example where all of these appear:
• USER: New calendar entry: meeting with Mrs Norton from Mycom next Tuesday.
• SYSTEM: What time?
• USER: The whole day. And please look up train connections to Berlin for that day.
This short exchange already contains a lot of details that draw a specific picture of the person speaking. For instance, we can guess with some confidence that the conversation is about a business meeting, allowing us to conclude that the speaker works in a position where attending such meetings is part of the job. But more specifically, we now know where the speaker will be on a specific day: next Tuesday, he or she will be in Berlin. The speaker’s preferred mode of transportation for getting to Berlin is revealed as well. In addition, we can also infer a couple of – let’s call them – negative pieces of information, namely that the speaker is not Mrs Norton, does not work for Mycom, and does not reside in Berlin. And finally, although we may not be absolutely sure about it, this small snippet of a voice interaction also allows us to hypothesize some facts with a certain level of probability: for instance, the current location of the speaker cannot be too far away from Berlin or else a train ride there would probably be too inconvenient to consider.
If such a short vocal exchange as this provides so much information for profiling a speaker, it becomes clear that more, longer, and more elaborate recordings and transcriptions of voice interactions bear even greater potential for abuse. In a slight variation to the quote at the beginning of this blog post, we really have reason to be worried: Tell me what you said and I tell you who you are.
The above example of course contains information not just about the speaker, but also about the other person mentioned: we know now that a Mrs Norton works for a company called Mycom and will also be in Berlin on Tuesday. Thus, privacy threats in recorded conversations do not only affect the people who actually participated in the conversation, but potentially third parties as well.
Identifying privacy threats in dialogues
The EU-funded research project COMPRISE seeks to find novel ways to protect the privacy of the users of voice assistants, while at the same time keeping in mind the need to improve the performance of such systems through continuous data collections. We employ state-of-the-art artificial intelligence and natural language processing methods to find ways to protect the users’ privacy by transforming the dialogue transcripts before they are uploaded to the cloud. The goal is to “disarm” the conversations from any privacy threats, so that even in cases where they accidentally get into the wrong hands, little to no harm can be done.
So how can this be achieved?
The names of people and organizations, and the mentions of locations and dates or times, are instances of what are referred to as “named entities” in the computational linguistics literature. One route to improved privacy consists of detecting these named entities automatically and either deleting them altogether or replacing them with something else, so that the result is less of a privacy concern for all parties involved.
Techniques for detecting named entities have long been studied because they are very useful for a lot of different applications, not just privacy protection. Therefore, without the need to reinvent the wheel, we can draw on existing approaches which are now as good as people at detecting named entities. State-of-the-art systems for this task employ contextual word embedding, such as BERT, and modern neural network architectures, such as the Transformer, to reach top performance.
Here’s the same voice interaction as shown above but with the different named entities identified, highlighted and labelled:
• USER: New calendar entry: meeting with Mrs. Norton [PER] from Mycom [ORG] next Tuesday [DATE].
• SYSTEM: What time?
• USER: The whole day [TIME]. And please look up train connections to Berlin [LOC] for that day [DATE] .
Detecting private information in dialogues is only the first step. The question is what to do with it once it has been identified? As part of the COMPRISE project, we’ve so far compared three different approaches and studied their pros and cons.
Handling private information in text
Removing sensitive portions from text, sometimes known as “sanitizing”, is often done by simply blacking out the relevant words. Many of us have seen such a redacted document at some point; it’s a technique commonly applied to classified government reports, for example. A recent, prominent example of such a document is the Mueller report, which was only released to the public in redacted form.
When this technique is implemented properly (i.e., the blacking out cannot be undone), it arguably provides a high level of privacy protection. However, it also has some downsides. For one, it makes it absolutely clear to everyone that the document has been transformed, and, also, exactly which parts were edited. In some situations, this might not be desirable. Further, blacking out some portions of a text is akin to deleting them and thus quite drastic. To illustrate the point, let’s apply redaction to our tried and trusted dialogue example, which was discussed above:
• USER: New calendar entry: meeting with ▬▬▬▬▬ from ▬▬▬ ▬▬ ▬▬▬ .
• SYSTEM: What time?
• USER: ▬ ▬▬▬ ▬▬ . And please look up train connections to ▬▬▬ for ▬▬ ▬▬ .
The problem is that what remains is quite difficult to read; without the redacted words, the sentences become ungrammatical. But the reason we are interested in privacy-transforming such dialogues in the first place is that we want to use more data to train machine learning models on them. Ungrammatical, ambiguous and often nonsensical data such as the above are very limited in their usefulness towards that goal.
An alternative to blacking out or removing sensitive words is to replace them with proxy words that keep the sentence structure intact but still improve privacy. It seems intuitive to use some kind of randomness in such a replacement approach, as opposed to some pre-defined mapping that would be trivial to reverse. At the same time, fixing a mapping for a specific context, say, the course of one document, makes sense too: always replacing each occurrence of a certain term with the same (random) replacement term guarantees coherence across the transformed document.
There is, however, a counter-argument to be made here. As well as modern named entity recognition systems perform, there is a chance that they occasionally miss one. Now, if an attacker got a hold of a transformed text where all occurrences of some private entity had been replaced by something else except for one, there is a good chance that from context, it would become apparent that that one un-replaced instance was the true word for all the other instances that did get replaced. Not good. If instead all of the same original words got replaced by different words every time, missing one would not stand out at all. But, again, it would come at the cost of losing text coherence.
The main question, however, is how to select the replacement terms for the identified private entities?
Replacement strategies
Let’s quickly discuss two aspects here: how to choose random replacement words and what to do about multi-word expressions.
In order to select replacement words by means of a random sampling procedure, we require two things: a vocabulary of candidate words and a probability distribution that tells us for each word in the vocabulary how likely it is to get selected as a replacement. So, where should those two things come from? A number of possibilities are conceivable.
For the vocabulary, here are two ideas: if you have already collected a sufficient amount of data before you want to transform them, you can first identify the contained Named Entities and extract the vocabulary from them. Naturally, it makes sense to have a separate vocabulary for each type of named entity, i.e., one for person names, one for organizations, etc. The advantage of extracting a vocabulary directly from collected data is that it will be an in-domain vocabulary which lowers the chance that some completely unrealistic replacements are chosen. If that is not an option, a general list of names, organizations, dates, times extracted, e.g., from census data, company registers, Wikipedia, etc., could be used instead.
Depending on exactly how the vocabulary was chosen, different options for suitable probability distributions become available. Of course, a uniform distribution where each candidate replacement is selected with the same probability is always a possibility. When the underlying vocabulary has been extracted, it is possible to use a distribution based on the frequency of occurrence in the data, which in some situations might be desirable. But since the purpose of collecting data is to use them for a subsequent learning task, we could also try to design an artificial distribution that is optimal for whatever task the data is used for.
In all of this, one detail gains prominence, and that is the fact that a lot of times, named entities consist of more than one word, as we have already seen in our small dialogue example (“Mrs Norton” or “next Tuesday”). Intuitively, it makes sense to replace the full expression with another full expression — so, for instance, replace “Mrs Norton” with “Mr Smith”. However, text coherence is again what poses a challenge here: the same entities can be referred to by different expressions. For instance, the same text could use “Mrs Merkel”, “Angela Merkel”, “Chancellor Merkel”, etc., all to refer to the head of the government of Germany. When each of these expressions gets randomly transformed into a completely unrelated replacement, it will be quite difficult to understand the meaning of the text after it has undergone transformation.
This is a difficult problem. A simple, albeit imperfect approach to solving it could be to not replace multi-word expressions as a single unit but instead replace each contained word individually. Especially if we had a means to maintain more fine-grained replacement vocabularies, e.g., one for first names, one for last names, one for titles, etc., then we would have a chance to end up with a coherently transformed text. An example of such a single-word transformation could look like this:
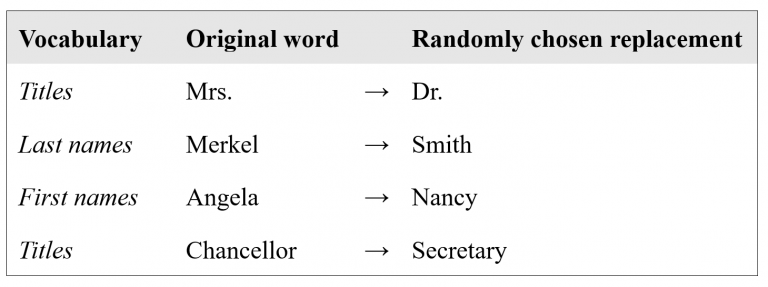
But such an approach only really works under the best of circumstances, such as in this idealized example. In general, the coherence problem is very hard to tackle. For instance, the question of what a first name is and what a last name is is very hard to pin down, and in some cultures these notions might not even be applicable at all.
Our simple named entity system from above does not distinguish between the different parts of a multi-word person name. Nevertheless, it is a replacement strategy that has enough merit to be considered as an alternative to always replacing entities as a whole.
AUAI is supported by:








