
ΑΙhub.org
Working towards explainable and data-efficient machine learning models via symbolic reasoning

By Yuan Yang
In recent years, we have witnessed the success of modern machine learning (ML) models. Many of them have led to unprecedented breakthroughs in a wide range of applications, such as AlphaGo beating a world champion human player or the introduction of autonomous vehicles.
There has been continuous effort, both from industry and academia, to extend such advances to solving real-life problems. However, converting a successful ML model into a real-world product is still a nontrivial task. The reasons for this are two-fold:
Firstly, modern ML methods are known for being data-hungry and inefficient. For example, training a successful AlphaGo agent requires the model to play 5 million complete games. This is possible in the Go game because one can get infinite data by running a game simulator. However, in many domains such as finance, a clinic, or cybersecurity, data is often difficult to gather and expensive to label.
Secondly, many ML methods, especially deep learning methods, are considered “black-box” models. It’s usually hard to explain how the model perceives the world and makes its decision. This “interpretability” issue can be critical when developing a reliable product for end-users who potentially know nothing about neural networks or nonlinear activations. For instance, if a physician wants to use an AI system for breast cancer screening, then from the user side it’s natural to expect the product to be accurate (which has already been achieved by many models) and self-explainable – where the system is able to convince the user that the prediction is reliable rather than just showing the accuracy scores.
So, how can we improve the data efficiency and interpretability of ML models?
We draw our inspiration from the human learning scenario. As a motivating example, consider a 3-year-old learning what a “car” is. By showing the baby a few pictures, it will be able to tell that “a car is something with wheels and windshields that people can drive”.
Typically, humans perceive the world as a set of discrete concepts, e.g. “car”, “person” and so on. We describe the world with natural languages that make use of these concepts and as well the relationships between them. For example, when you see the picture below, you will describe it as “a man that is driving a car”. This is different from many ML models that view it as an array of pixel values.
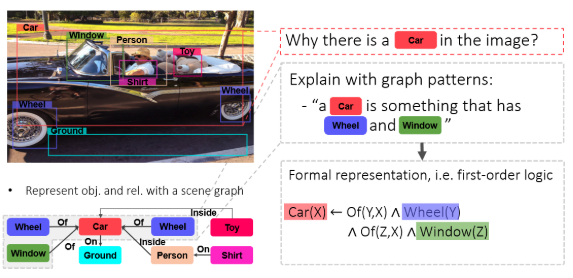
As a consequence, humans learn a new concept by associating it with the concepts that they already know. In the car example mentioned above, we learn it as an object that has wheels and windshields rather than from scratch. We can see that learning with such a symbolic system is potentially data-efficient, because we are utilizing our existing knowledge, and interpretable, because the learned concept is discrete and can be explained with other concepts.
Motivated by this observation, our recent studies seek to realize such capabilities by empowering the ML models with (i) knowledge graphs (KGs) that store the discrete concepts and (ii) the ability to reason over the KGs symbolically.
A knowledge graph is one way to store and represent prior knowledge. As suggested by the name, a KG is a graph that consists of a set of nodes and edges that connect them, where the node corresponds to a specific concept and the edge corresponds to a relation. For example, “Barack Obama is a politician of the United States” can be represented as two nodes, i.e. “Barack Obama” and “United States”, and one edge “PoliticianOf” that connects the two.
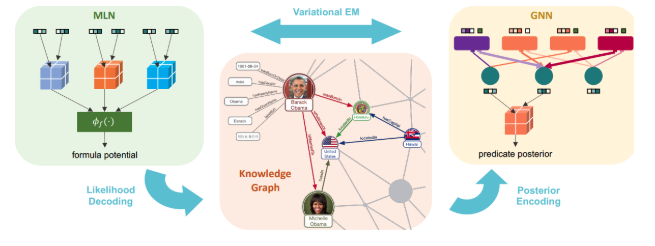
Reasoning with human prior knowledge
With a knowledge graph, the model is able to utilize prior knowledge from humans to reduce the data needed for acquiring the skill. For example, we can instruct the model that “a car is usually something that has wheels and windshields”; such knowledge will now correspond to a sub-pattern in the graph. Whenever the model is presented with a new entity, the model can infer if it is a car by checking the existence of this sub-pattern.
This process is usually referred to as deductive logic reasoning. However, many of the widely used reasoning methods such as Markov Logic Networks are limited to small KGs. In our paper Efficient probabilistic logic reasoning with graph neural networks, we propose an efficient logic reasoning method that can scale to very large KGs such as Freebase and WordNet.
In this work, we propose using graph neural networks, a novel model that excels at recognizing graphs, to make the reasoning generalize to similar graphs without re-training the model. The proposed method, which we refer to as ExpressGNN, is able to make the usage of prior knowledge more efficient.
Mining knowledge and explaining the decisions
Sometimes, prior knowledge isn’t available and we are interested in mining such knowledge from the graph automatically. This is referred to as inductive logic programming (ILP). However, many ILP methods suffer from scalability issues and are limited in expressing complex knowledge found in the graph.
In our paper, Learn to explain efficiently via neural logic inductive learning, we propose an efficient method (NLIL) that mines the common sub-patterns in the graph and represents them into symbolic knowledge that can be inspected by humans. In the experiment, our method outperforms several state-of-the-art ILP methods both in terms of efficiency and knowledge expressiveness.
More importantly, we show that this method also helps improve the interpretability of the ML models. We task our model to learn to recognize the visual objects in the Visual Genome dataset by learning to find the common-sense rules that lead to correct predictions.
We show that by simply relying on the symbolic graph information, our method is able to learn rules to predict object classes with comparable accuracy to deep learning models trained with dense visual features. However, in this way, the learned decisions are represented with explicit logic that is highly interpretable. For example, as shown above, our model predicts “building” as “something that has a roof” and “food” as “something that can be eaten by people”.
Conclusion
Introducing the capability of reasoning with discrete concepts offers an alternative mechanism to allow humans to communicate and instruct our data-driven models more effectively. In this blog post, we have discussed how such a mechanism can be helpful in developing an economic and reliable AI system. In future work, our vision is to build AI agents that can learn new concepts and discover knowledge with less human supervision.
Both of these papers were presented at the International Conference on Learning Representations (ICLR), April 26-30.

AUAI is supported by:








