
ΑΙhub.org
Robots learning to move like animals

Whether it’s a dog chasing after a ball, or a monkey swinging through the trees, animals can effortlessly perform an incredibly rich repertoire of agile locomotion skills. But designing controllers that enable legged robots to replicate these agile behaviors can be a very challenging task. The superior agility seen in animals, as compared to robots, might lead one to wonder: can we create more agile robotic controllers with less effort by directly imitating animals?

Quadruped robot learning locomotion skills by imitating a dog.
In this work, we present a framework for learning robotic locomotion skills by imitating animals. Given a reference motion clip recorded from an animal (e.g. a dog), our framework uses reinforcement learning to train a control policy that enables a robot to imitate the motion in the real world. Then, by simply providing the system with different reference motions, we are able to train a quadruped robot to perform a diverse set of agile behaviors, ranging from fast walking gaits to dynamic hops and turns. The policies are trained primarily in simulation, and then transferred to the real world using a latent space adaptation technique, which is able to efficiently adapt a policy using only a few minutes of data from the real robot.
Framework
Our framework consists of three main components: motion retargeting, motion imitation, and domain adaptation. 1) First, given a reference motion, the motion retargeting stage maps the motion from the original animal’s morphology to the robot’s morphology. 2) Next, the motion imitation stage uses the retargeted reference motion to train a policy for imitating the motion in simulation. 3) Finally, the domain adaptation stage transfers the policy from simulation to a real robot via a sample efficient domain adaptation process. We apply this framework to learn a variety of agile locomotion skills for a Laikago quadruped robot.
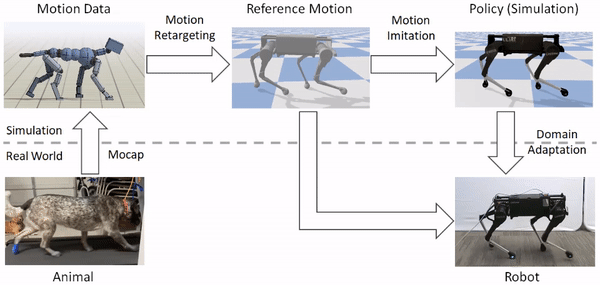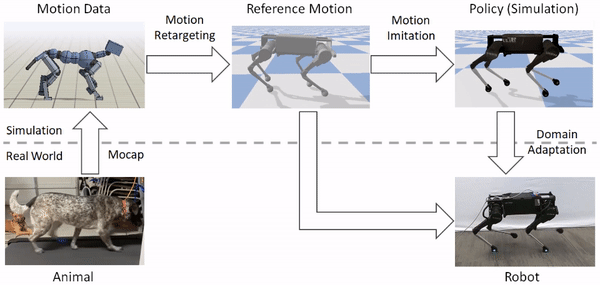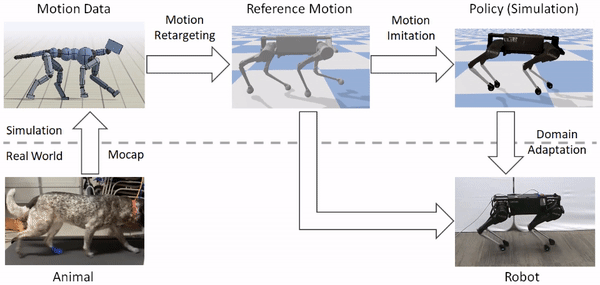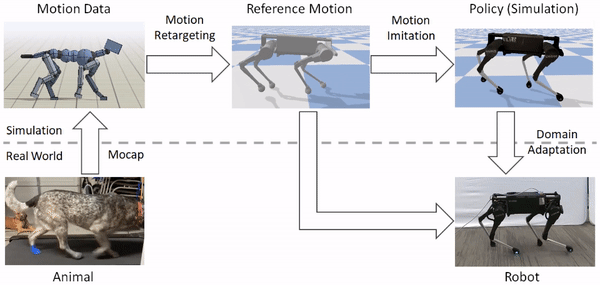
The framework consists of three stages: motion retargeting, motion imitation, and domain adaptation. It receives as input motion data recorded from an animal, and outputs a control policy that enables a robot to reproduce the motion in the real world.
Motion Retargeting
An animal’s body is generally quite different from a robot’s body. So before the robot can imitate the animal’s motion, we must first map the motion to the robot’s body. The goal of the retargeting process is to construct a reference motion for the robot that captures the important characteristics of the animal’s motion. To do this, we first identify a set of source keypoints on the animal’s body, such as the hips and the feet. Then, corresponding target keypoints are specified on the robot’s body.
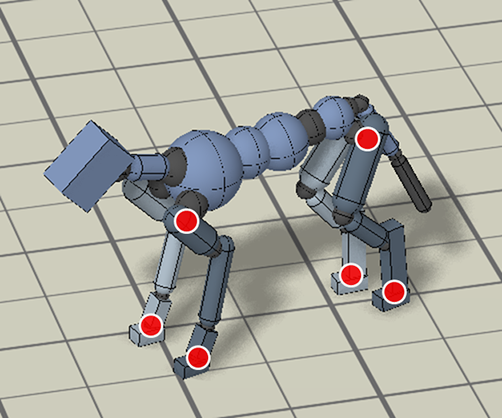

Inverse-kinematics (IK) is used to retarget mocap clips recorded from a real dog (left) to the robot (right). Corresponding pairs of keypoints (red) are specified on the dog and robot’s bodies, and then IK is used to compute a pose for the robot that tracks the keypoints.
Next, inverse-kinematics is used to construct a reference motion for the robot that tracks the corresponding keypoints from the animal at every timestep.
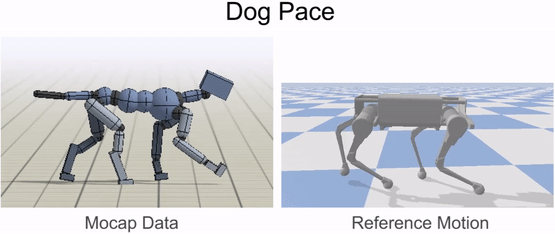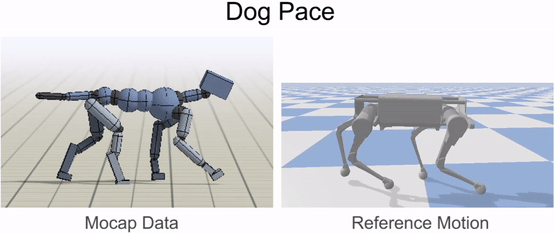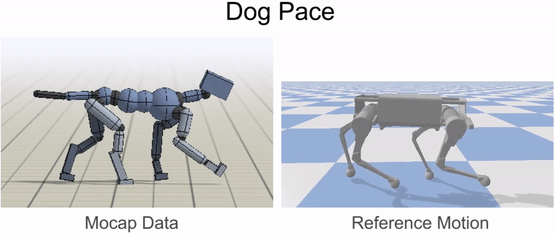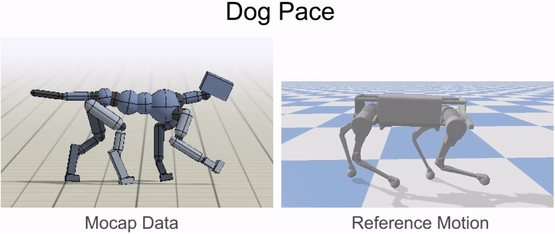
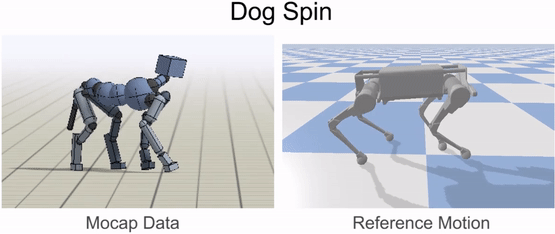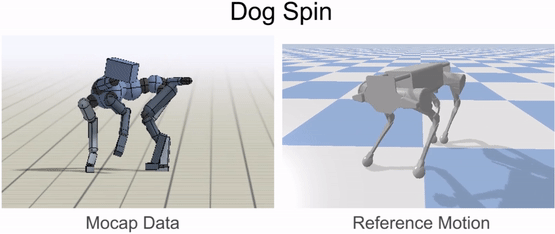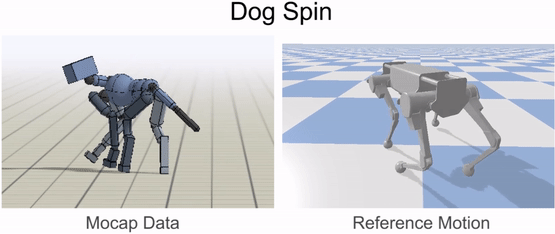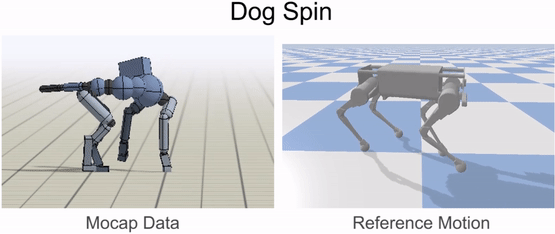
Inverse-kinematics is used to retarget mocap clips recorded from a dog to the robot.
Motion Imitation
After retargeting the reference motion to the robot, the next step is to train a control policy to imitate the retargeted motion. But reinforcement learning algorithms can take a long time to learn an effective policy, and directly training on a real robot can be fairly dangerous (both for the robot and its human companions). So, we instead opt to perform most of the training in the comforts of simulation, and then transfer the learned policy to the real world using more sample efficient adaptation techniques. All simulations are performed using PyBullet.
The policy  , takes as input a state
, takes as input a state  , which represents the configuration of the robot’s body, and a goal
, which represents the configuration of the robot’s body, and a goal  , which specifies target poses from the reference motion that the robot is to imitate. It then outputs an action
, which specifies target poses from the reference motion that the robot is to imitate. It then outputs an action  , which
, which
specifies target angles for PD controllers at each of the robot’s joints. To train the policy to imitate a reference motion, we use a reward function that encourages the robot to minimize the difference between the pose of the reference motion  and the pose of the simulated character
and the pose of the simulated character  at every timestep
at every timestep  ,
,
By simply using different reference motions in the reward function, we can train a simulated robot to imitate a variety of different skills.
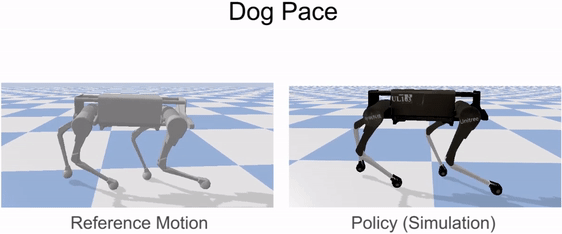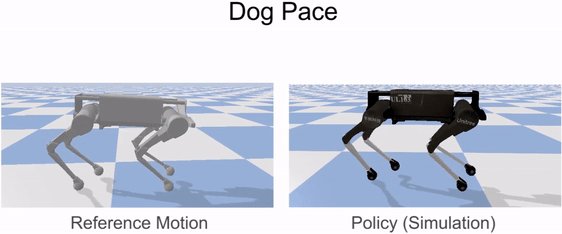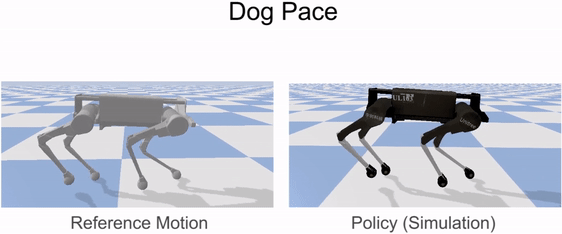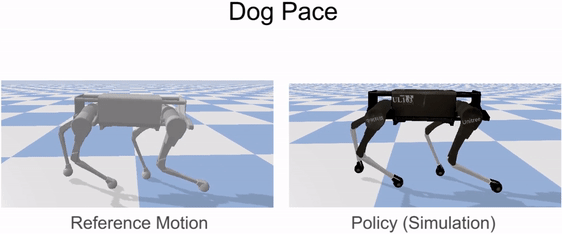
Reinforcement learning is used to train a simulated robot to imitate the retargeted reference motions.
Domain Adaptation
Since simulators generally provide only a coarse approximation of the real world, policies trained in simulation often perform fairly poorly when deployed on a real robot. Therefore, to transfer a policy trained in simulation to the real world, we use a sample efficient domain adaptation techniques that can adapt the policy to the real world using only a small number of trials on the real robot. To do this, we first apply domain randomization during training in simulation, which randomly varies the dynamics parameters, such as mass and friction. The dynamics parameters are then also collected into a vector  and encoded into a latent presentation
and encoded into a latent presentation  by an encoder
by an encoder  . The latent encoding is passed as an additional input to the policy
. The latent encoding is passed as an additional input to the policy  .
.
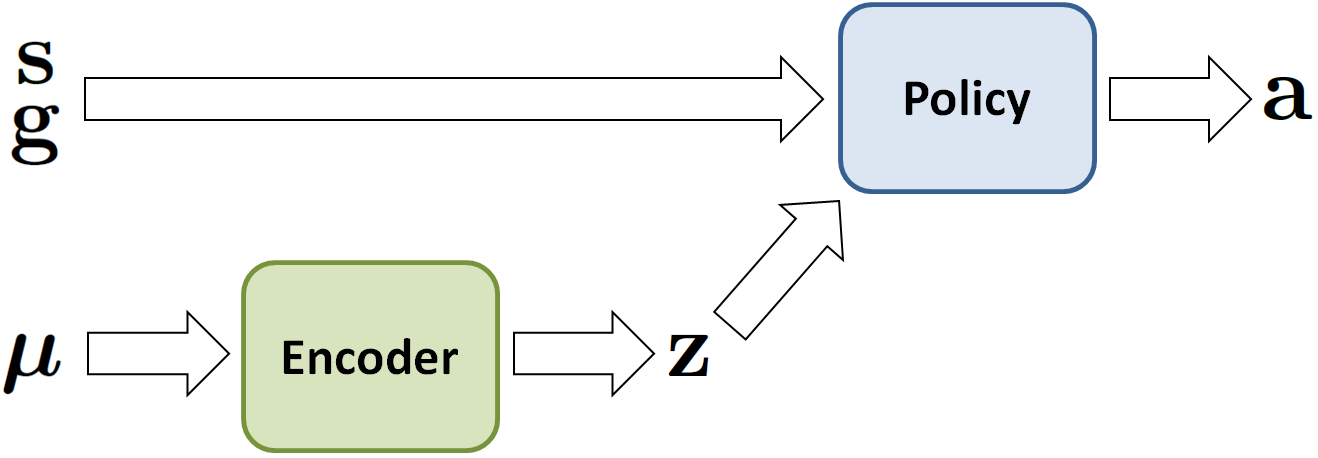
The dynamics parameters of the simulation are varied during training, and also encoded into a latent representation that is provided as an additional input to the policy.
When transferring the policy to a real robot, we remove the encoder and directly search for a that maximizes the robot’s rewards in the real world. This is done using advantage weighted regression, a simple off-policy reinforcement learning algorithm. In our experiments, this technique is often able to adapt a policy to the real world with less than 50 trials, which corresponds to roughly 8 minutes of real-world data.


Comparison of policies before and after adaptation on the real robot. Before adaptation, the robot is prone to falling. But after adaptation, the policies are able to more consistently execute the desired skills.
Results
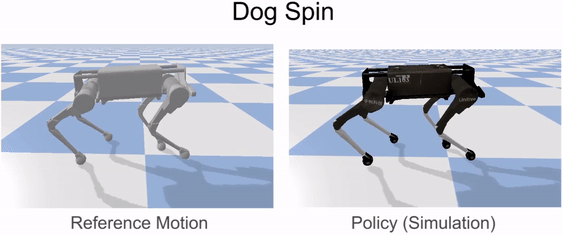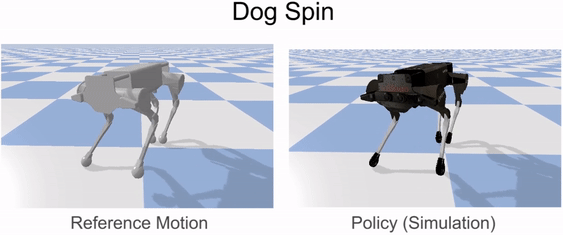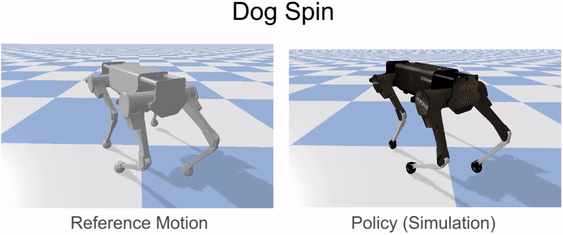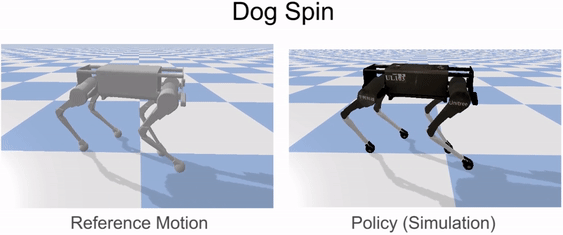
Our framework is able to train a robot to imitate various locomotion skills from a dog, including different walking gaits, such as pacing and trotting, as well as a fast spinning motion. By simply playing the forwards walking motions backwards, we are also able to train the robot to walk backwards.

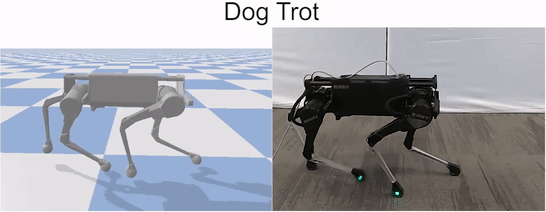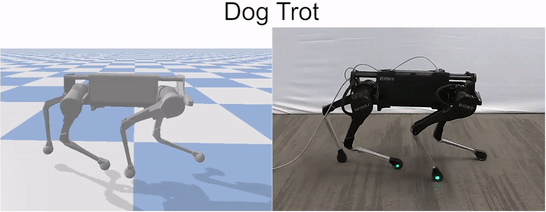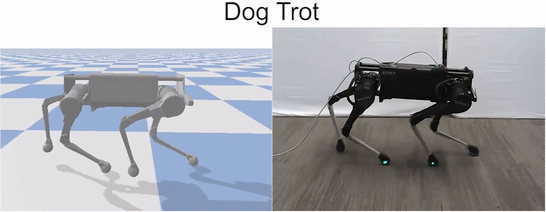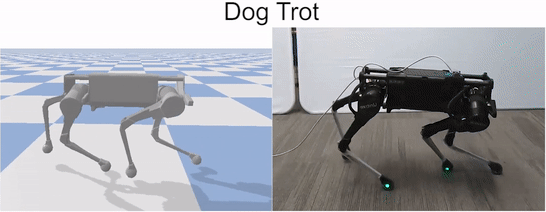


Laikago imitating various skills from a dog.
In addition to imitating motions from real dogs, we can also imitate artist-animated keyframe motion, including a dynamic hop-turn:


Hop Turn

Skills learned by imitating artist-animated keyframe motions.
We also compared the learned policies with the manually-designed controllers provided by the manufacturer. Our policies are able to learn faster gaits.

Comparison of learned trotting gait with the built-in gait provided by the manufacturer.
Overall, our system has been able to reproduce a fairly diverse corpus of behaviors with a quadruped robot. However, due to hardware and algorithmic limitations, we have not been able to imitate more dynamic motions such as running and jumping. The learned policies are also not as robust as the best manually-designed controllers. Exploring techniques for further improving the agility and robustness of these learned policies could be a valuable step towards more complex real-world applications. Extending this framework to learn skills from videos would also be an exciting direction, which can substantially increase the volume of data from which robots can learn from.
To learn more, check out the paper and code.
We would like to thank Erwin Coumans, Tingnan Zhang, Tsang-Wei Lee, Jie Tan, Sergey Levine, Byron David, Thinh Nguyen, Gus Kouretas, Krista Reymann, and Bonny Ho for all their support and contribution to this work. This project was done in collaboration with Google Brain.
This article was initially published on the BAIR blog, and appears here with the authors’ permission.

AUAI is supported by:








