
ΑΙhub.org
Usage of speaker embeddings for more inclusive speech-to-text
English is one of the most widely used languages worldwide, with approximately 1.2 billion speakers. The number of non-native speakers far outweighs the number of native speakers. In order to maximise the performance of speech-to-text systems it is vital to build them in a way that recognises different accents.
Recently, spoken dialogue systems have been incorporated into various devices such as smartphones, call services, and navigation systems. These intelligent agents can assist users in performing daily tasks such as booking tickets, setting-up calendar items, or finding restaurants via spoken interaction. They have the potential to be more widely used in a vast range of applications in the future, especially in the education, government, healthcare, and entertainment sectors. However, due to the range in language fluency of the users, these systems must include an adaption mechanism for dealing with these varying speech characteristics.
Speech-to-text systems are quite sensitive to variations in speaker characteristics. It has been frequently reported that their performance severely degrades when there is a mismatch between the training and test speakers. There are two main reasons for these mismatches. The first one is a disparity in the characteristics of the recording environment. Changes in the environment such as using different microphones or different room acoustics impair speech-to-text systems. The second reason is the variability in speakers due to the diversity of genders, vocal tract lengths, accents, or speaking styles. For instance, the effect of vocal tract length on the acoustic features can be estimated, and then feature normalization (known as vocal tract length normalization) can be applied on top of that.
In this blog post, we focus on this second reason and discuss our methodology to reduce the gap in speech-to-text performance for accented users. We’ll investigate how speaker embeddings can be utilized inside the speaker adaptation problem to achieve more inclusive speech-to-text. The systems trained using this strategy become more independent of speaker variations and generalize better to unseen speakers with different accents due to the mitigation of inter-speaker variability.
The role of speaker embeddings
Speaker embedding is a simple but effective methodology to represent the speaker’s identity in a compact way (as a vector of fixed size, regardless of the length of the utterance). A natural approach is to represent each speaker by a one-hot speaker code. Although this idea works well for speakers in a training set, it cannot (i) deal with speakers not seen in the training set, and (ii) find the desired speaker among a large number of candidate speakers. More advanced speaker codes have been proposed for alleviating these problems.
Identity vectors (i-vectors for short) encode both speaker and channel variabilities in a common low-dimensional space (referred to as the “total variability space”). In this approach, the data is partitioned into pseudo-phonetic classes by means of a Gaussian mixture model (GMM). The differences between the pronuciation of a given speaker and the average pronuciation are computed for all phonetic classes and projected onto a low-dimensional vector called i-vector which is estimated in the maximum a posteriori (MAP) sense. This provides an elegant way of reducing high-dimensional sequential input data to a low-dimensional fixed-length vector while retaining most of the relevant information.
I-vectors are unsuitable for short utterances because the MAP point estimate does not model the overall uncertainty well. Additionally, their performance quickly reaches a ceiling as the amount of data increases, which means that they are unable to fully exploit the availability of large-scale training data. The success of deep learning for speech-to-text has motivated researchers to develop neural network based speaker embeddings. Early implementations used deep neural networks (DNNs) to extract so-called bottleneck features, or to partition the data in the i-vector framework.
A more effective approach is to employ DNNs trained to predict speaker identity from given acoustic features. Embeddings extracted from a hidden layer then encode the speaker characteristics onto a fixed-length vector. A d-vector is a well-known example of DNN-based speaker embedding. A DNN is trained frame-by-frame and the d-vector is extracted by averaging all the activations of a selected hidden layer from an utterance. This idea works for unseen speakers and solves the first problem defined above (i.e., defined in (i)), yet it cannot solve the second problem (i.e., defined in (ii)), because it is only used for verification of a specific speaker, and its vector coordinates in the embedding space do not correlate with the inter-speaker similarity. In other words, inside the d-vector approach, perceptually similar speakers are not necessarily encoded close to each other. Concerning frame-wise training of d-vectors, only temporal information is kept, yet the speaker information tends to reside within long-term segments.
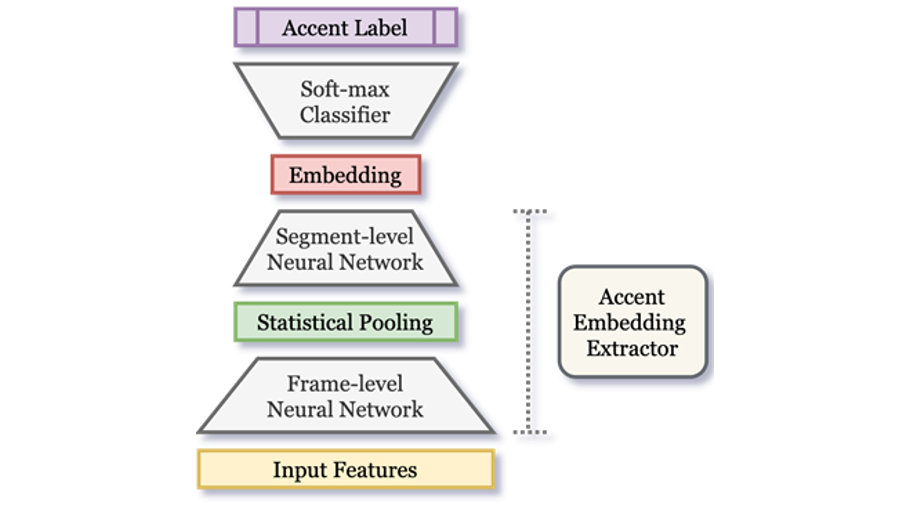
To address these problems, recurrent architectures have been introduced to directly capture segment information. Speaker variability is usually considered as a result of channel effects although this is not strictly accurate since intra-speaker variation and phonetic variation are also involved. A recent approach is therefore trained to discriminate between speakers, and maps variable-length utterances to fixed-dimensional embeddings that we call x-vectors. The x-vector embedding extraction system usually consists of two components: frame-level feature processing and segment (utterance) level feature processing. Frame-level processing deals with a local short span of acoustic features. It can be done via time-delayed neural networks (TDNNs). Segment-level processing forms accent representation based on the frame-level output. A pooling layer is used to gather frame-level information to form an utterance-level representation. Methods such as statistical pooling or max-pooling are popular choices.
Our approach in COMPRISE
In COMPRISE, we propose a framework to perform acoustic model adaptation for accented speech samples. We compute x-vector-like accent embeddings and use them as auxiliary inputs inside a TDNN-based acoustic model trained on native data only in order to improve the speech-to-text performance on multi-accent data comprising native, non-native, and accented speech. By doing so, we are forcing our embedding model to discriminate accent classes better. Accent embeddings, which provide a fixed lower-dimensional representation of the main acoustic characteristics from many accents, are estimated for each accent and then appended to all the input features from the same speaker.
We evaluated our method on native, non-native, and accented speech. For the native and non-native data, we used the Verbmobil corpus which contains spontaneous speech from human meeting scheduling dialogs. In Verbmobil, we selected American English dialogs as native data and English (US) dialogs from German (DE) speakers as non-native data. We also gathered British (UK), Indian (IN), and Australian (AU) non-professional accented speech recordings from VoxForge. The embedding network is trained on the utterances of all native (US) and accented (UK, IN, AU, DE) speakers in Verbmobil and VoxForge, excluding those in the test set for the acoustic model. These are included in the adaptation set for the acoustic model.
We ran two different types of experiments on native, non-native, and accented data. All of them follow exactly the same TDNN topology. In the first part of the experiments, we only train our acoustic models using native (US) data. In the second part, we add 1-hour of (transcribed) adaptation data for each accent class into the training set to make our framework more robust. Note that training, test, and adaptation sets are organized with disjoint speakers.
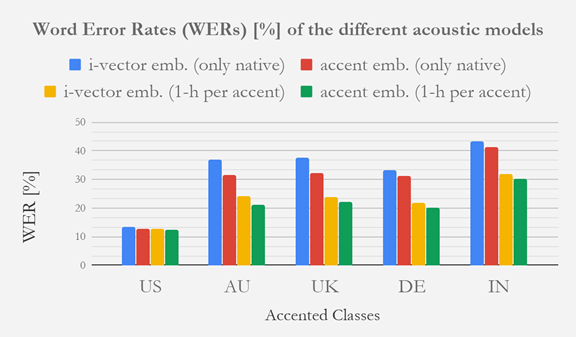
Blue and yellow colors in the table above present the results of i-vector-based speaker adaptation with native data only and with 1-hour adaptation data per accent, respectively. We show the proposed accent embedding based adaptation method in red and green colors. Compared with i-vectors, we observe relative word error rate (WER) improvements of 7% on non-native German (DE) data, 11% on native data (US), and 14 to 20% on accented data (AU, UK, IN). These improvements are remarkable since these models are trained on native data only. Our proposed x-vector-like accent embeddings also achieve superior performance with 1-hour adaptation data per accent. As expected, adding additional accented data does not make a significant difference in the results over native (US) speech.
To sum up, we have proposed an acoustic model adaptation method that relies on x-vector-like accent embeddings to achieve multi-accent speech-to-text. It is worth mentioning that our method is fully unsupervised; i.e., the accented data used to train the embeddings is untranscribed and, although the 1-hour adaptation data considered above is transcribed, we have also achieved significant performance improvement using untranscribed adaptation data. As future work, we plan to combine the proposed acoustic modeling scheme with language model adaptation. We expect this to benefit non-native speech-to-text, since non-native speakers may also use specific language variants.
AUAI is supported by:








