
ΑΙhub.org
Interview with Marc Habermann – #CVPR2020 award winner

Marc Habermann received an Honorable Mention in the Best Student Paper category at CVPR 2020 for work with Weipeng Xu, Michael Zollhöfer, Gerard Pons-Moll and Christian Theobalt on “DeepCap: Monocular Human Performance Capture Using Weak Supervision”. Here, Marc tells us more about their research, the main results of their paper, and plans for further improvements to their model.
What is the topic of the research in your paper?
The topic of our work is monocular human performance capture which focuses on capturing the pose as well as the deforming 3D surface of a person from a single RGB video. In a daily life scenario, one can then record a video of a person just using his smartphone and DeepCap can recover the 3D geometry of the person who was recorded. It is worth noting that the monocular setting makes it especially challenging due to the inherent depth ambiguity and the large amount of occlusions.
Could you tell us a little bit about the implications of your research and why it is an interesting area for study?
There is a lot of previous work in the area of human performance capture using multiple cameras. They typically provide very high quality results which are for example used in movies. However, most people do not have access to these expensive hardware setups, e.g. multi-camera capture studios. But nowadays everyone has a smartphone that is able to record a video. Therefore, we are interested in developing methods that also work with a single camera to further democratize those technologies.
Moreover, with the current advances in virtual and augmented reality 3D characters become even more important as such characters can greatly improve the immersive experience of these devices. For example, you can capture the person next to you and apply augmentation techniques, for example re-texturing or re-lighting, or you can insert the person’s virtual double in a fully virtual world.
Last, I think the area of human performance capture comes along with very challenging problem settings, e.g. How can you recover the deformations for areas that are not visible to the camera? or How can you recover the depth of the actor from a RGB image/video?. Some of these questions were partially answered in previous work but there are still a lot of unexplored challenges. Therefore, I think there is great potential for future research.
Could you explain your methodology?
Given a single RGB video of the person, we are interested in recovering the 3D geometry for each frame of the video. Therefore, we split the task into two subtasks and solve each of them using deep learning techniques. First, our PoseNet takes the RGB image and regresses the pose of the actor. Second, our DefNet takes the same RGB image and regresses the non-rigid deformation of the surface in a canonical pose to account for clothing deformations, e.g. the swinging of a skirt. Finally, the result of the two networks can be combined using our deformation layer and one obtains the posed and deformed character. The splitting of the task has the advantage that we can solve the problem in a coarse to fine manner which makes it easier to learn for the networks. To train both networks, no manually annotated data is required. Instead, we leverage weak multi-view supervision in form of 2D keypoints and foreground masks per view and frame. Here, our differentiable layers allow us to supervise the 3D geometry only using the weak multiview 2D supervision.
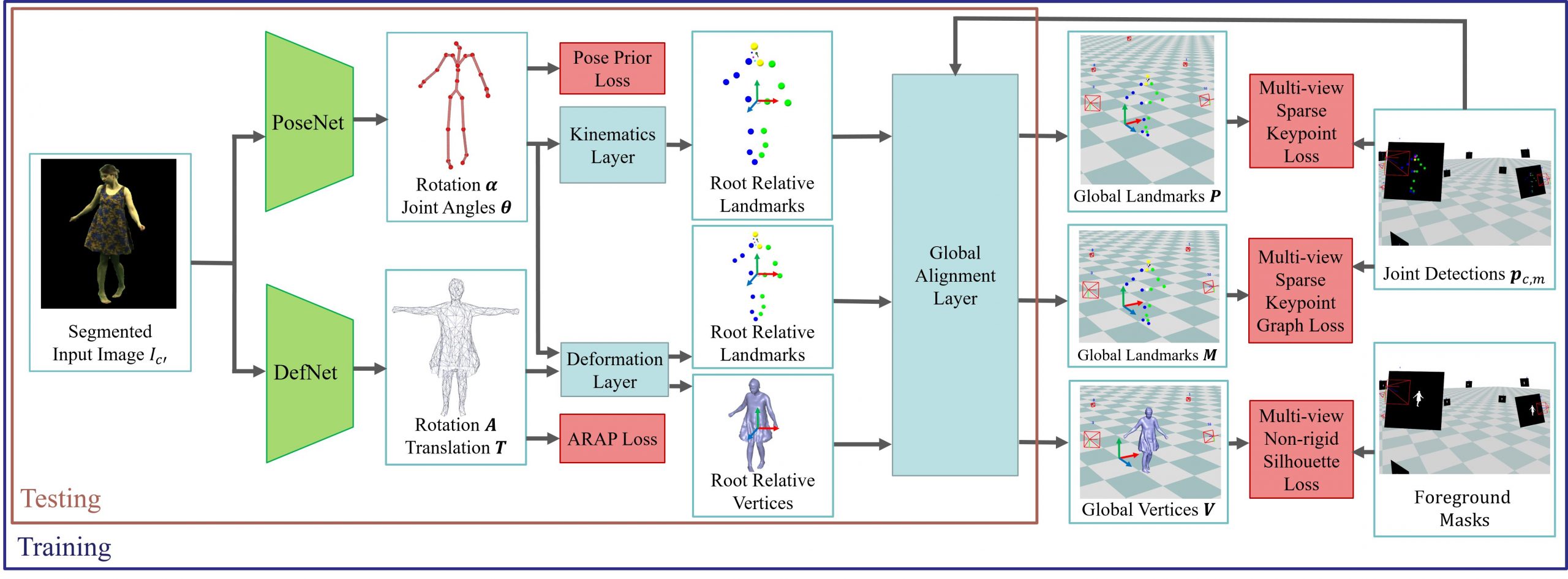
What were your main findings?
The key question, which we asked ourselves when we started the project, was: Can weak multi-view supervision during training help to improve the 3D performance of our approach compared to previous work? Further, we asked ourselves: Can the network correctly predict the 3D deformations even for occluded surface parts given this type of supervision? In our experiments, we were able to show that indeed the network can learn these things and the type of supervision was sufficient for this task. For us, this was the main and most important finding.
What further work are you planning in this area?
I think two important aspects are still missing. First, we used purely geometric priors and our model is not multi-layered which means the geometry is not separated into body and clothing. Having a multi-layered model and a physics-based prior could further improve the tracking quality of the clothing. Second, our approach is person-specific. This implies that if we would like to track a new person or a new type of apparel we have to first capture a training sequence and train our models again. It would be more convenient to have a method that can generalize across people such that once the method is trained it can be applied to arbitrary people and clothing. In our video results, we already showed that our method can to some extend generalize to different people in the same type of clothing but still there was a drop in accuracy and it remains unsolved how to generalize to different types of clothing. But of course, there are also other directions which can be improved in future research like jointly capturing body, hands, face, and clothing or improving the tracking quality even further such that also smaller deformations like fine wrinkles in the clothing can be correctly predicted.
Read the paper in full here.
About Marc Habermann

Marc Habermann
I work as a PhD student in the Graphics, Vision and Video group, headed by Prof. Dr. Christian Theobalt, at the Max Planck Institute for Informatics. Within my theses, I explore the modeling and tracking of non-rigid deformations of surfaces, e.g. capturing the performance of humans in their everyday clothing. In our previous work, LiveCap, we showed that this is possible at real-time frame rates and in our latest work, DeepCap, we further improved the 3D performance using deep learning techniques.

AUAI is supported by:








