
ΑΙhub.org
Maintaining the illusion of reality: transfer in RL by keeping agents in the DARC

By Benjamin Eysenbach
Reinforcement learning (RL) is often touted as a promising approach for costly and risk-sensitive applications, yet practicing and learning in those domains directly is expensive. It costs time (e.g., OpenAI’s Dota2 project used 10,000 years of experience), it costs money (e.g., “inexpensive” robotic arms used in research typically cost 10,000 to 30,000 dollars), and it could even be dangerous to humans. How can an intelligent agent learn to solve tasks in environments in which it cannot practice?
For many tasks, such as assistive robotics and self-driving cars, we may have access to a different practice area, which we will call the source domain. While the source domain has different dynamics than the target domain, experience in the source domain is much cheaper to collect. For example, a computer simulation of the real world can run much faster than real time, collecting (say) a year of experience in an hour; it is much cheaper to simulate 1,000 robot manipulators in parallel than to maintain 1,000 robot manipulators. The source domain need not be a simulator, but rather could be any practice facility, such as a farm of robot arms, a playpen for learning to walk, or a controlled testing facility for self-driving vehicles. Our aim is to learn a policy in the source domain that will achieve high reward in a different target domain, using a limited amount of experience from the target domain.
This problem (domain adaptation for RL) is challenging because the source and target domains might have different physics and appearances. These differences mean that strategies that work well in the practice facility often don’t transfer to the target domain. For example, a good approach to driving a car around a dry racetrack (the source domain) may entail aggressive acceleration and cutting corners. If the target domain is an icy, public road, this approach may cause the car to skid off the road or hit oncoming traffic. While prior work has thoroughly studied the domain adaptation of appearance in RL [Bousmalis 2017, Ganin 2016, Higgins 2017], it ignores the domain adaptation of the physics.
Method
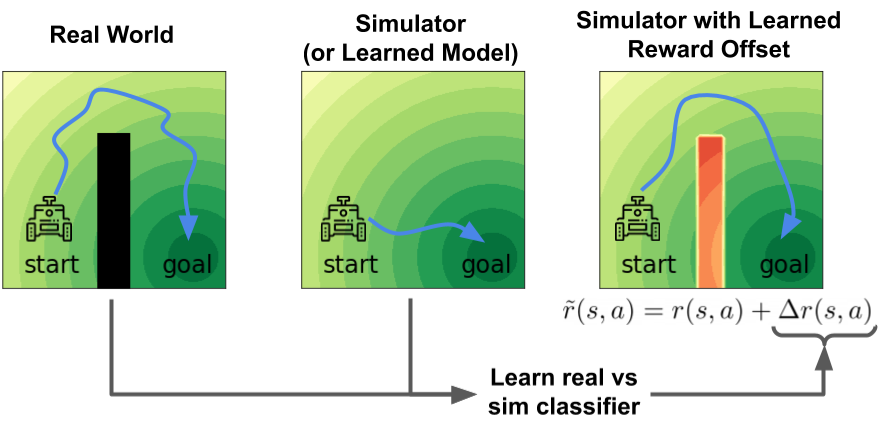
Our approach stems from the idea that the agent’s experience in the source domain should look similar to its experience in the target domain. We can achieve this goal by compensating for the difference in dynamics by modifying the reward function. The figure below above shows an illustrative example, where the real world (left) contains an obstacle that is unmodeled in the simulator (center). Our method automatically learns to assign a high penalty when the agent takes actions in the simulator that would not be possible in the real world. For this example, our method puts a high penalty (red region) in the middle of the practice facility, as transitions through that region will not be possible in the real world. In effect, the agent is penalized for transitions that would indicate that the agent is interacting with the source domain, rather than the target domain.
Formally, we will search for a policy whose behavior in the source domain both receives high reward and has high likelihood under the target domain dynamics. It turns out that this objective can be written as a combination of the standard MaxEnt RL objective [Ziebart 2010] together with a reward correction,
![\[\max_\pi \mathbb{E}_\pi\bigg[\sum_t \underbrace{r(s_t, a_t) + \mathcal{H}_\pi[a_t \mid s_t]}_{\text{MaxEnt RL}} + \underbrace{\Delta r(s_t, a_t, s_{t+1})}_{\text{reward correction}} \bigg],\]](https://aihub.org/wp-content/ql-cache/quicklatex.com-20c6fb9c7593f2be45a5c21339c78be7_l3.png "Rendered by QuickLaTeX.com")
where the reward correction  measures the discrepancy between the dynamics in the source domain (p_source) and the target domain (p_target):
measures the discrepancy between the dynamics in the source domain (p_source) and the target domain (p_target):
![\[\Delta r(s_t, a_t, s_{t+1}) = \log p_\text{target}(s_{t+1} \mid s_t, a_t) - \log p_\text{source}(s_{t+1} \mid s_t, a_t).\]](https://aihub.org/wp-content/ql-cache/quicklatex.com-e0a36c9f4cc68e9d6a32b05027576f0d_l3.png "Rendered by QuickLaTeX.com")

The combined objective has a number of intuitive interpretations:
- Viewing the next state shouldn’t give you any additional information about whether you are in the source or target domain.
- You should maximize reward, subject to the constraint that physics seen by your robot in the source domain looks like the physics of the target domain.
- Our method aims to acquire a policy that remains ignorant of whether it is interacting with the simulator or the real world.
While is defined in terms of dynamics, it turns out that we can estimate without learning a dynamics model. Applying Bayes’ Rule, we can rewrite as
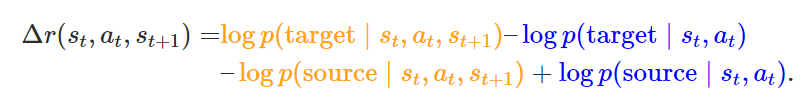
The orange terms can be estimated by learning a classifier that distinguishes source vs target given  ; the blue terms can be estimated using a classifier that distinguishes source vs target given
; the blue terms can be estimated using a classifier that distinguishes source vs target given  . We therefore call our method Domain Adaptation with Rewards from Classifiers, or DARC. While we do require a limited amount of experience from the target domain to learn these classifiers, our experiments show that learning a classifier (which has a binary output) is easier than learning a dynamics model (which must predict a high-dimensional output). DARC is simple to implement on top of any MaxEnt RL algorithm (e.g., on-policy, off-policy, and model-based).
. We therefore call our method Domain Adaptation with Rewards from Classifiers, or DARC. While we do require a limited amount of experience from the target domain to learn these classifiers, our experiments show that learning a classifier (which has a binary output) is easier than learning a dynamics model (which must predict a high-dimensional output). DARC is simple to implement on top of any MaxEnt RL algorithm (e.g., on-policy, off-policy, and model-based).
Connection with Observation Adaptation: Now that we’ve introduced the DARC algorithm, we pause briefly to highlight the relationship between domain adaptation of dynamics versus observations. Consider tasks where the state  is a combination of the system latent state
is a combination of the system latent state  (e.g., the poses of all objects in a scene) and an observation
(e.g., the poses of all objects in a scene) and an observation  (e.g., a camera observation). We will define
(e.g., a camera observation). We will define  and
and  as the observation models for the source and target domains (e.g., as defined by the rendering engine or the camera model). In this special case, we can write as the sum of two terms, which correspond to observation adaptation and dynamics adaptation:
as the observation models for the source and target domains (e.g., as defined by the rendering engine or the camera model). In this special case, we can write as the sum of two terms, which correspond to observation adaptation and dynamics adaptation:
![\[\begin{aligned} \Delta r(s_t, a_t, s_{t+1}) =& \underbrace{\log p_{\text{target}}(o_t \mid z_t) - \log p_{\text{source}}(o_t \mid z_t)}_{\text{Observation Adaptation}} \\ & + \underbrace{\log p_{\text{target}}(z_{t+1} \mid z_t, a_t) - \log p_{\text{source}}(z_{t+1} \mid z_t, a_t)}_{\text{Dynamics Adaptation}} . \end{aligned}\]](https://aihub.org/wp-content/ql-cache/quicklatex.com-3d2bea4890bd1ea1a34c953ac637feeb_l3.png "Rendered by QuickLaTeX.com")
While prior methods excel at addressing observation adaptation [Bousmalis 2017, Gamrian 2019, Fernando 2013, Hoffman 2016, Wulfmeier 2017], only our method captures both the adaptation and dynamics terms.
Experiments

We applied DARC to a number of simulated robotics tasks. On some tasks, we crippled one of the robot’s joints in the target domain, so the robot has to use practice on the fully-functional robot (source domain) to learn a policy that will work well on the broken robot. In another task, the target domain includes a new obstacle, so the robot has to use practice in a source domain (without the obstacle) to learn a policy that will avoid the obstacle. We show the results of this experiment in the figure above, plotting the reward on the target domain as a function of the number of transitions in the target domain. On all tasks, the policy learned in the simulator does not transfer to the target domain. On three of the four tasks our method matches (or even surpasses) the asymptotic performance of doing RL on the target domain, despite never doing RL on experience from the target domain, and despite observing 5 – 10x less experience from the target domain. However, as we scale to more complex tasks (“broken ant” and “half cheetah obstacle”), we observe that all baselines perform poorly.
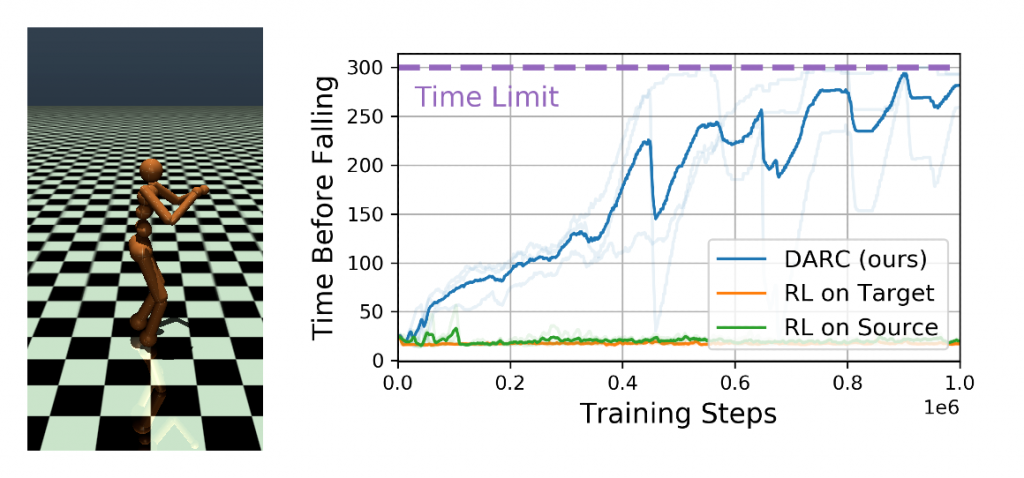
Our final experiment showed how DARC can be used for safety. In many applications, robots have freedom to practice in a safe and cushioned practice facility, where they are preemptively stopped when they try to take unsafe actions. However, the real world may not contain such safeguards, so we want our robots to avoid relying on these safeguards. To study this setting, we used a simulated human robot. In the source domain, the episode terminates if the agent starts to fall; the target domain does not include this safeguard. As shown in the plot above, our method learns to remain standing for nearly the entire episode, while baselines fall almost immediately. While DARC was not designed as a method for safe RL [Tamar 2013, Achaim 2017, Berkenkamp 2017, Eysenbach 2017], this experiment suggests that safety may emerge automatically from DARC, without any manual reward function design.
Conclusion
The main idea of this project is that agents should avoid taking actions that would reveal whether they are in the source domain or the target domain. Even when practicing in a simulator, the agent should attempt to maintain the illusion that it is in the real world. The main limitation of our method is that the source dynamics must be sufficiently stochastic, an assumption that can usually be satisfied by adding noise to the dynamics, or ensembling a collection of sources.
For more information, check out the paper or code!
Acknowledgements: Thanks to Swapnil Asawa, Shreyas Chaudhari, Sergey Levine, Misha Khodak, Paul Michel, and Ruslan Salakhutdinov for feedback on this post.
This article was initially published on the ML@CMU blog and appears here with the authors’ permission.

AUAI is supported by:








