
ΑΙhub.org
Topics in data analysis
This series of blog posts is based on the Fall 2019 10-718 Data Analysis class at Carnegie Mellon University, taught by Leila Wehbe, with the assistance of Jacob Tyo, Aria Wang and Fabricio Flores. The blog posts were written by the students and edited by the instructors and the ML@CMU blog team.
What is data analysis? A simple definition is: the application of machine learning and statistical methods to real world data to solve a problem. While this statement is simple, data analysis eventually requires expertise from a vast number of disciplines such as the real world domain in question (e.g. healthcare, specific scientific field, finance, etc.) and machine learning and statistics, but could also require knowledge from other fields as diverse as computing or policy or law. The complexity of data science leads to a plethora of possible pitfalls, with no clear instructions on how to avoid them. It is very difficult to construct a specific set of such instructions because every application domain has very specific setups, goals and constraints.
We focus here on these issues from the perspective of a machine learning expert and attempt to provide some general guidelines to avoid pitfalls. In some cases where it’s difficult to provide guidelines, we present a set of notable mistakes to avoid. Unlike usual machine learning classes or tutorials that focus on introducing methods and algorithms, we focus on the higher level of motivating the use of these algorithms and testing the generalizability of their conclusions. We focus on the connection between machine learning and its practice.
In this series of educational blog posts, we highlight components of data analysis by focusing on 7 topics. Each topic is based on key papers, book chapters or blog posts that we have discussed in class. For each topic, we highlight pitfalls to watch out for and propose solutions when possible, some inspired by the literature and others by class discussion. We invite the readers to share their comments with us to help us improve the posts.
1 – The Importance of Domain Knowledge

Why is domain knowledge important in data science? This blog post shows the value of domain knowledge in data analysis from multiple perspectives. It includes some simple case studies to demonstrate how domain knowledge can help us with every stage of the data analysis workflow, focuses on several examples to give an in-depth view of the use of domain knowledge in specific tasks and includes an interesting discussion about the relationship between domain knowledge and machine learning algorithms.
https://blog.ml.cmu.edu/2020/08/31/1-domain-knowledge/
2 – Data Exploration
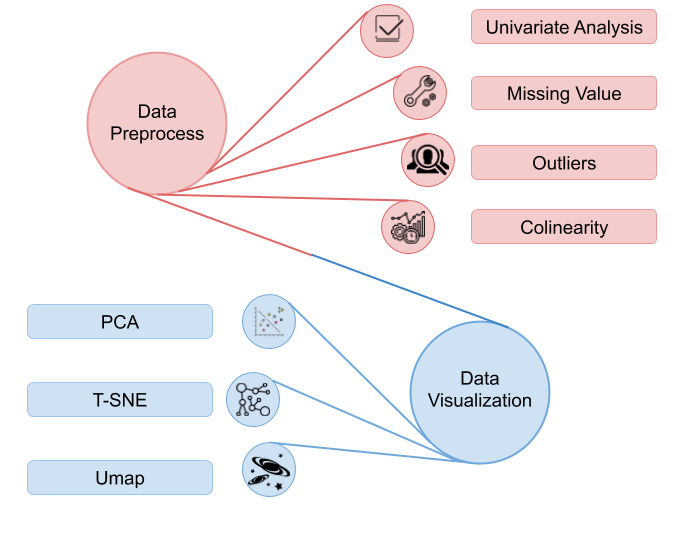
Although sometimes practitioners tend to spend more time on model architecture design and parameters tuning, the importance of data exploration should not be ignored. If data breaks the assumption of the model or contains errors, it will not be possible to get desired results even with the best of models. This blog post introduces a protocol for data exploration along with several methods that may be useful in this process, including statistical and visualization methods, as well as examples of traps in data exploration and of how data exploration helps reduce bias in the dataset.
https://blog.ml.cmu.edu/2020/08/31/2-data-exploration/
3 – Baselines
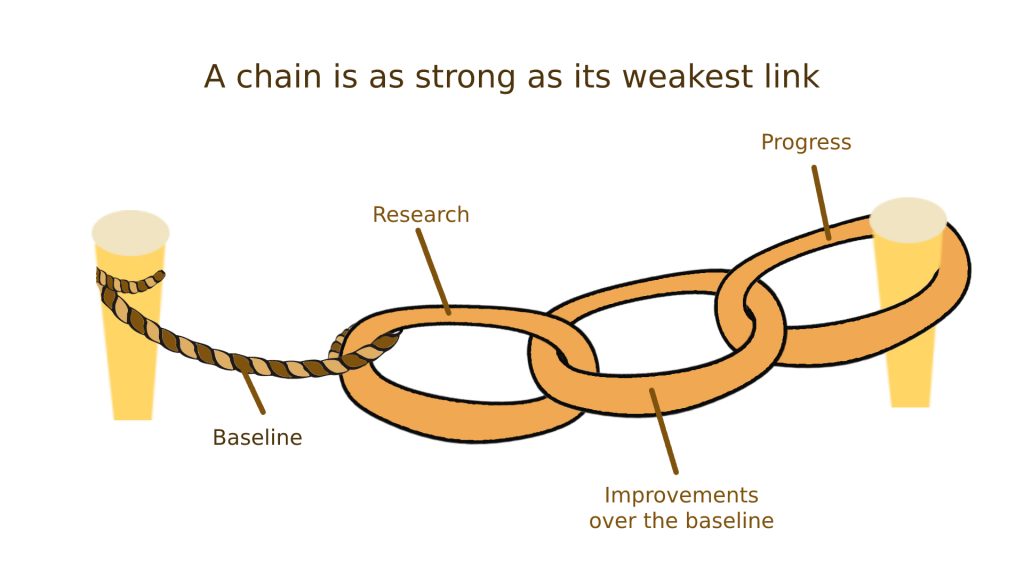
A baseline guides our selection of more complex models and provides insights into the task at hand. Nonetheless, such a useful tool is not easy to handle, and many researchers tend to compare their novel models against weak baselines which poses a problem in the current research sphere as it leads to optimistic, but false results. This blog provides a definition of different types of baselines, case studies of examples in which they are not correctly used, a discussion on such issues and questions that are still open-ended.
https://blog.ml.cmu.edu/2020/08/31/3-baselines/
4 – The Overfitting Iceberg

Overfitting, as a conventional and important topic of machine learning, has been well-studied with tons of solid fundamental theories and empirical evidence. However, as breakthroughs in deep learning are rapidly changing science and society in recent years, practitioners have observed many phenomena that seem to contradict classical learning theory. This blog aims to understand the nuances and subtleties behind this apparent contradiction by introducing a proposed mechanism for their emergence; it also summarizes some state-of-the-art strategies to deal with overfitting in the modern DL practice.
https://blog.ml.cmu.edu/2020/08/31/4-overfitting/
5 – Reproducibility
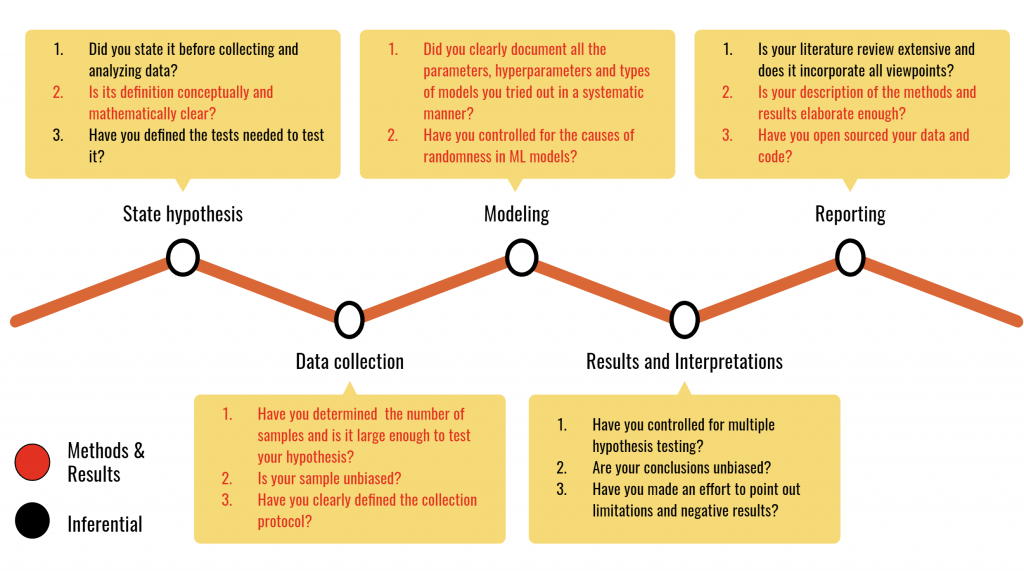
It is now widely agreed that reproducibility is a key part of any scientific process and that it should be considered a regular practice to make our research reproducible. Despite this widely accepted notion, many fields including machine learning are experiencing a reproducibility crisis. This blog explains the different definitions of reproducibility, relates the reproducibility crisis and discusses its implications for scientific research and its more general impacts on society.
https://blog.ml.cmu.edu/2020/08/31/5-reproducibility/
6 – Interpretability
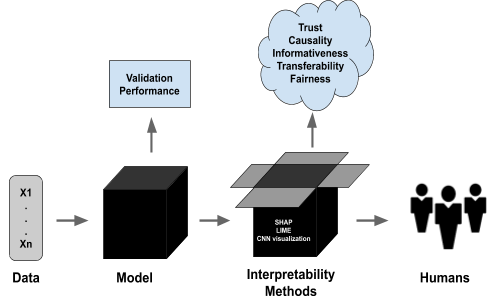
The objectives that machine learning models optimize for do not always reflect the actual desiderata of the task at hand. Interpretability in models allow us to evaluate their decisions and obtain information that the objective alone cannot confer. Interpretability takes many forms and can be difficult to define; this blog explores general frameworks and sets of definitions in which model interpretability can be evaluated and compared and analyzes several well-known examples of interpretability methods in the context of this framework.
https://blog.ml.cmu.edu/2020/08/31/6-interpretability/
7 – Causal Inference

The rules of causality play a role in almost everything we do and it is reasonable to assume that considering causality in a world model will be a critical component of intelligent systems in the future. However, the formalisms, mechanisms, and techniques of causal inference remain a niche subject few explore. In this blog we formally consider the statement “association does not equal causation”, review some of the basics of causal inference, discuss causal relationship discovery, and describe a few examples of the benefits of utilizing causality in AI research.
https://blog.ml.cmu.edu/2020/08/31/7-causality/
This article was initially published on the ML@CMU blog and appears here with the authors’ permission.

AUAI is supported by:








