
ΑΙhub.org
Interview with Ionut Schiopu – ICIP 2020 award winner
Ionut Schiopu and Adrian Munteanu received a Top Viewed Special Session Paper Award at the IEEE International Conference on Image Processing (ICIP 2020) for their paper “A study of prediction methods based on machine learning techniques for lossless image coding”. Here, Ionut Schiopu tells us more about their work.
What is the topic of the research in your paper?
The research topic of our paper is to introduce a more efficient algorithm for lossless image compression based on Machine Learning (ML) techniques, where the main objective is to minimize the amount of data required to represent the input image without any information loss. In recent years, a new research strategy for coding has emerged by exploring the advances brought by modern ML techniques by proposing novel hybrid coding solutions where specific modules in conventional coding frameworks are replaced with more efficient modules based on ML techniques. The paper follows this research strategy and uses a deep neural network to replace the prediction module in the conventional coding framework.
Could you tell us a little bit about the implications of your research and why it is an interesting area for study?
The latest top-of-the-line cameras have continuously increased the image resolution and require more powerful tools to compress the steadily growing volume of data. There are many applications which require that the original image must be compressed without any information loss as the raw data contains critical information which will be lost after applying a lossy compression technique. Think about having access to medical images where all the details are compressed so that the doctors can make a decision after analyzing the real context. Think about capturing high resolution photographic images without losing the smallest details found in the grass, in a building’s architectural design, in the vivid colors of a forest, etc. Think about capturing satellite images where the information in every pixel is important.
Could you explain your methodology?
In general, a conventional system for lossless image coding consists of three main steps:
- prediction, where the value of the current pixel is predicted using a linear combination of the values of the pixels found in a causal neighborhood around the current pixel, where the neighborhood generally has a small size mainly due to the low complexity constraint;
- error modeling, where the error computed between the true and predicted values is modeled using a complex context modeling method to capture and exploit the higher-order interpixel dependencies and reduce the magnitude of the residual-error; and
- entropy coding, where the modeled error is finally encoded using a powerful entropy coding technique.
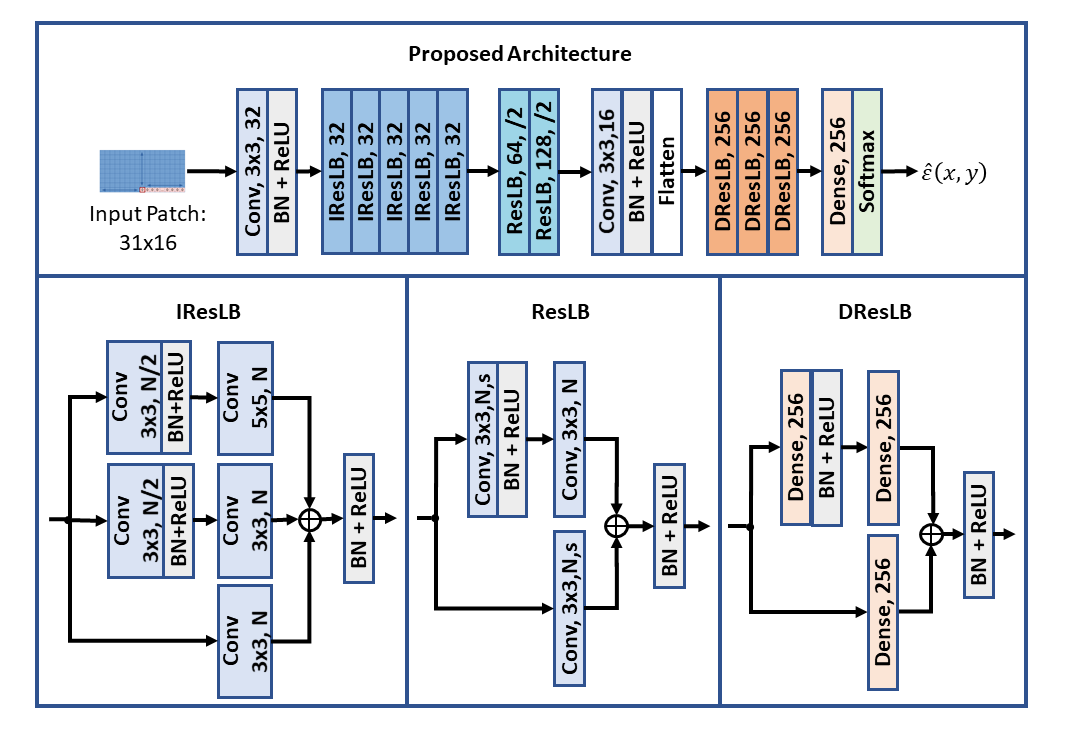
The proposed algorithm is designed to compress high resolution images without any information loss by modifying the conventional framework to employ a deep neural network to replace the traditional prediction method and predict the current pixel based on large neighboring window. In our work, we used a window of size height x width =16×31 pixels. The main idea is that instead of employing a neural network to directly predict the current pixel, first a traditional prediction method is used to compute the initial prediction, and then the proposed neural network is employed to predict the residual error of the initial prediction. More exactly, the proposed network learns where the traditional predictor fails to correctly predict the current value and estimates the corresponding prediction error. The proposed network uses the large neighboring window to understand the context of the current pixel and train its weights to predict how far the initial prediction is from the true value.
What were your main findings?
The paper studies the network designs employed in our previously proposed lossless coding solutions and brings the following novel contributions:
- (a) we propose a novel neural network design based on a more efficient structure of dense layers;
- (b) we study different architecture variations with the goal of finding the best performance-vs-complexity tradeoff;
- (c) we propose modifying the network training procedure by introducing a second training stage where the models are further trained based on a different training configuration.
The neural network architectures employed for prediction are usually designed to first process the input using a complex sequence of convolutional layers, and then extract the final prediction using one or two dense layers, which account for a large percentage of network parameters. In our previous work [A], we proposed a deep network architecture where the complexity of the dense layer-based part of the network was reduced using a sequence of 11 dense layers. In this paper, we propose a new dense layer structure called Dense Residual Learning Block (DResLB) which follows the concept of dual-branch processing where the outputs are added before applying the non-linearity. In comparison with the network architecture from [A], we further replace the sequence of 11 dense layer blocks with 3 DResLB blocks. The DResLB blocks follow the idea that the feature maps computed by the convolutional layer part of the network are better processed using two parallel branches with one and two dense layers, respectively.
In our search for an optimal network design, three other architecture variations were studied:
- we proposed to reduce the number of network parameters by using only 2 DResLBs;
- we proposed to increase the number of parameters by using 4 DResLBs;
- we proposed to modify the DResLB structure by using a 3-branch design with 1, 2, or respectively 3 dense layers for a branch.
The compression results on a set of 4K UHD photographic images demonstrate a systematic and substantial improvement in the coding performance of the proposed method compared to conventional lossless coding paradigms. The proposed codec has 4.95% fewer network parameters compared with our previous design [A] and achieves 47.8% improved performance compared to the traditional lossless image compression codec, free lossless image format (FLIF) [B], and 1.9% improved performance compared to our previous design [A]. One can note that an outstanding performance gap of almost 50% is achieved compared to traditional lossless codecs, which confirms once again that the ML-based tools will play an important role in the design of future lossless image coding standards.
References
[A] Schiopu and A. Munteanu, Deep-Learning-Based Lossless Image Coding IEEE Transactions on Circuits and Systems for Video Technology (2020).
[B] J. Sneyers and P. Wuille, FLIF: Free lossless image format based on MANIAC compression Proc. International Conference on Image Processing (2016).
What further work are you planning in this area?
Our future work plans include studying more efficient ways to further reduce the network complexity while maintain a close performance compared with the proposed method, and to replace the entropy coding method with a ML-based method, which can further increase the performance gap beyond 50%.
About Ionut Schiopu

Ionut Schiopu received a B.Sc. degree in Automatic Control and Computer Science in 2009 and a M.Sc. degree in Advanced Techniques in Systems and Signals in 2011 from Politehnica University of Bucharest, Romania, and a Ph.D. degree in February 2016 from Tampere University of Technology (TUT), Finland. In the period between March 2016 and June 2017, he was postdoctoral researcher at Tampere University of Technology, Finland. Since July 2017, he has been a postdoctoral researcher at Vrije Universiteit Brussel, Belgium. His research interests are design and optimization of machine learning tools for image and video coding applications, view synthesis, depth estimation, semantic segmentation, and entropy coding based on context modeling. He is the author of 34+ journal and conference publications. View his homepage and LinkedIn page.

AUAI is supported by:








