
ΑΙhub.org
Tilted empirical risk minimization
By Tian Li
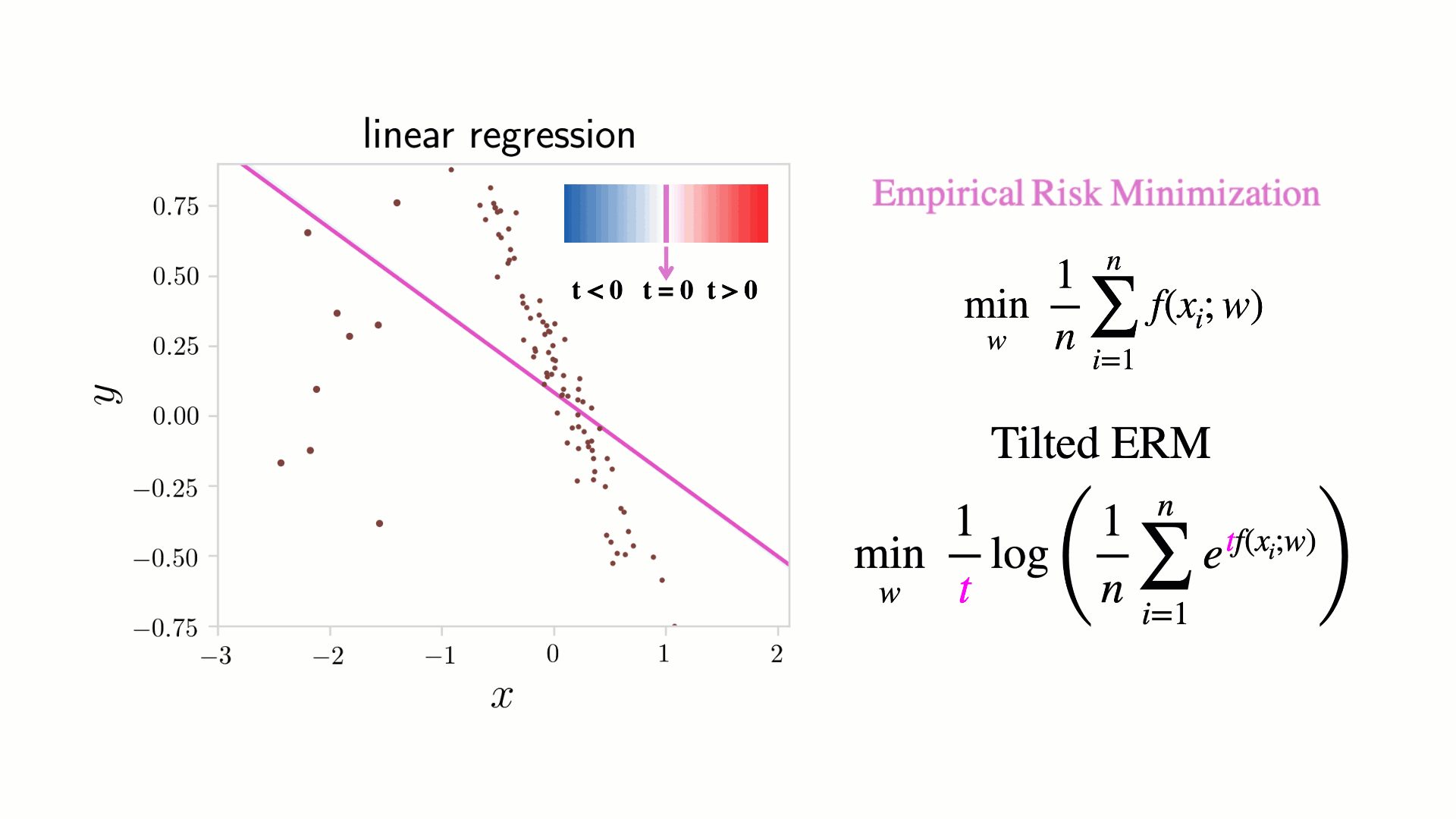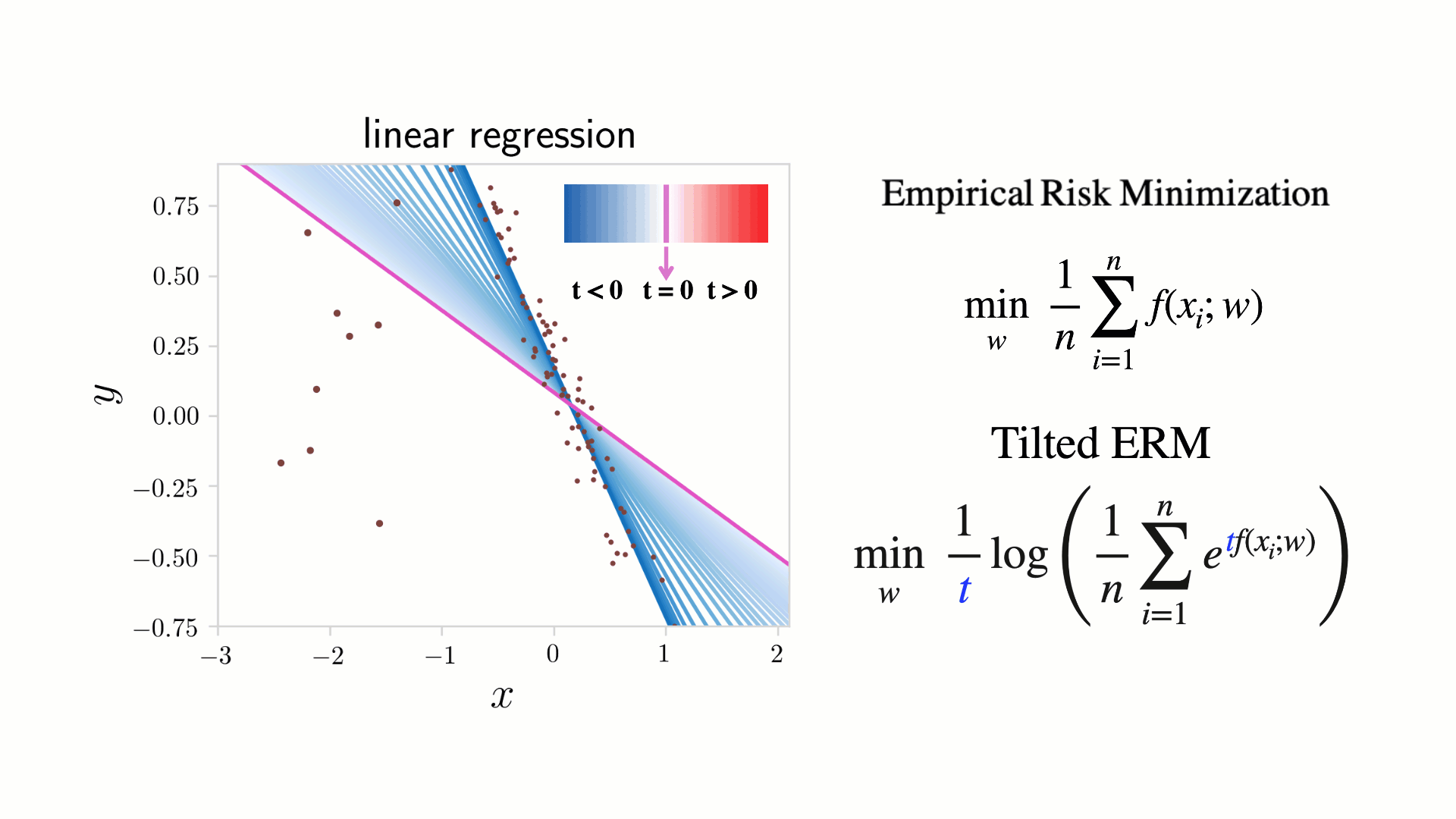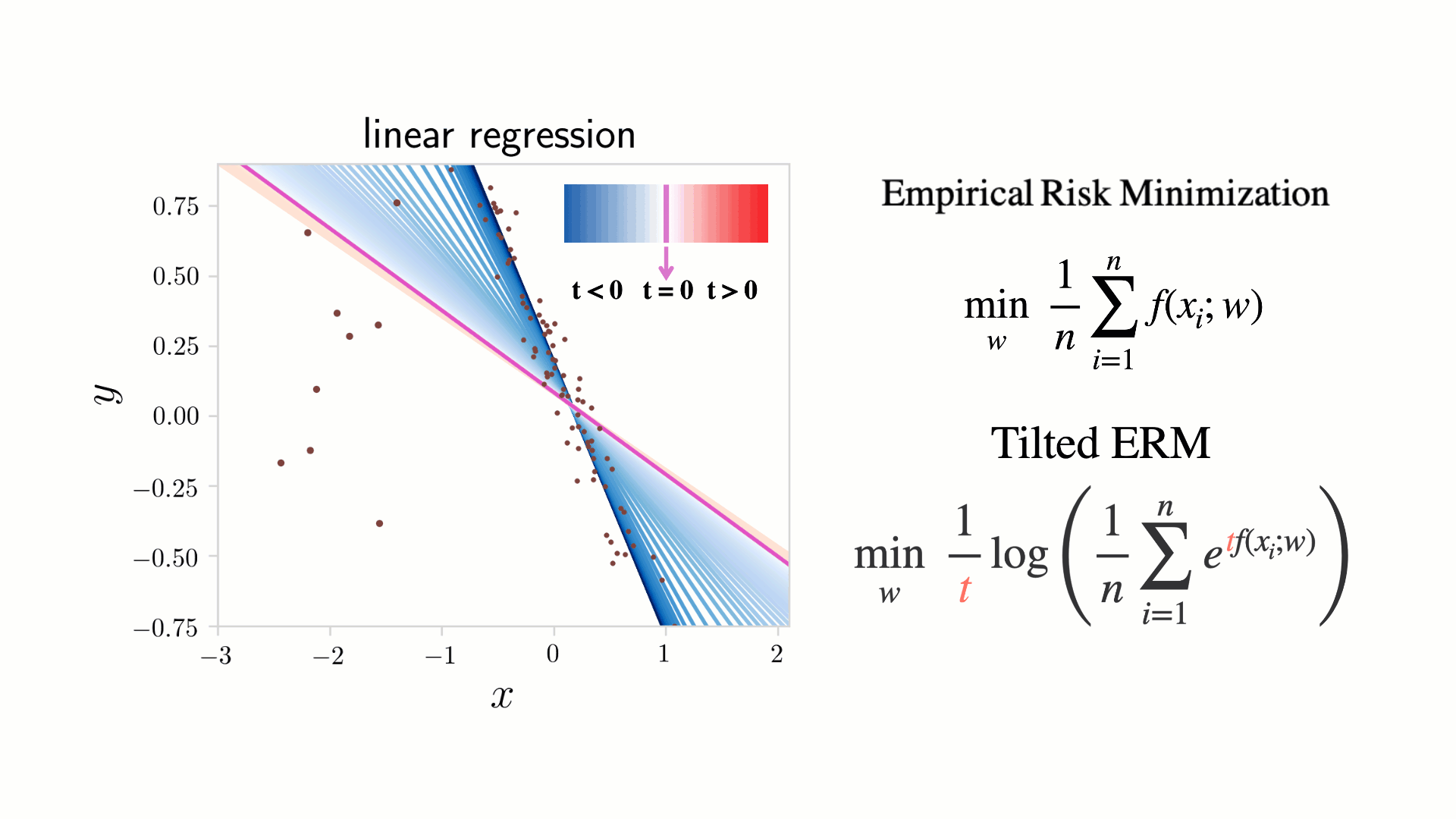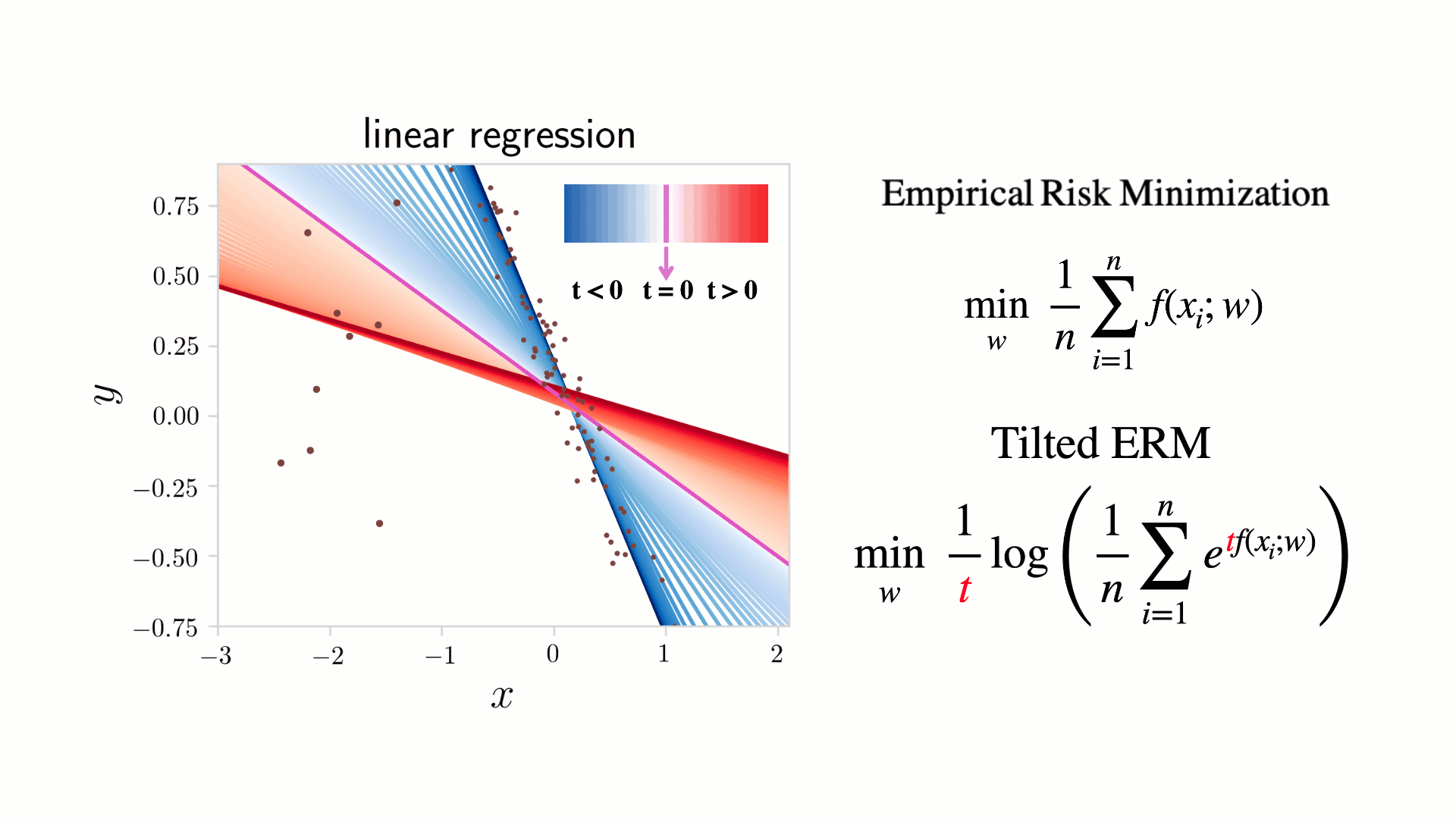
Figure 1. A toy linear regression example illustrating Tilted Empirical Risk Minimization (TERM) as a function of the tilt hyperparameter  . Classical ERM (
. Classical ERM ( ) minimizes the average loss and is shown in pink. As
) minimizes the average loss and is shown in pink. As  (blue), TERM finds a line of best fit while ignoring outliers. In some applications, these ‘outliers’ may correspond to minority samples that should not be ignored. As
(blue), TERM finds a line of best fit while ignoring outliers. In some applications, these ‘outliers’ may correspond to minority samples that should not be ignored. As  (red), TERM recovers the min-max solution, which minimizes the worst loss. This can ensure the model is a reasonable fit for all samples, reducing unfairness related to representation disparity.
(red), TERM recovers the min-max solution, which minimizes the worst loss. This can ensure the model is a reasonable fit for all samples, reducing unfairness related to representation disparity.
In machine learning, models are commonly estimated via empirical risk minimization (ERM), a principle that considers minimizing the average empirical loss on observed data. Unfortunately, minimizing the average loss alone in ERM has known drawbacks—potentially resulting in models that are susceptible to outliers, unfair to subgroups in the data, or brittle to shifts in distribution. Previous works have thus proposed numerous bespoke solutions for these specific problems.
In contrast, in this post, we describe our work in tilted empirical risk minimization (TERM), which provides a unified view on the deficiencies of ERM (Figure 1). TERM considers a modification to ERM that can be used for diverse applications such as enforcing fairness between subgroups, mitigating the effect of outliers, and addressing class imbalance—all in one unified framework.
What is Tilted ERM (TERM)?
Empirical risk minimization is a popular technique for statistical estimation where the model,  , is estimated by minimizing the average empirical loss over data,
, is estimated by minimizing the average empirical loss over data,  :
:
![\[\overline{R} (\theta) := \frac{1}{N} \sum_{i \in [N]} f(x_i; \theta).\]](https://aihub.org/wp-content/ql-cache/quicklatex.com-85bf7a201c5e2765c0389f4802ca8a14_l3.png "Rendered by QuickLaTeX.com")
Despite its popularity, ERM is known to perform poorly in situations where average performance is not an appropriate surrogate for the problem of interest. In our work (ICLR 2021), we aim to address deficiencies of ERM through a simple, unified framework—tilted empirical risk minimization (TERM). TERM encompasses a family of objectives, parameterized by the hyperparameter :
![\[\widetilde{R} (t; \theta) := \frac{1}{t} \log\left(\frac{1}{N} \sum_{i \in [N]} e^{t f(x_i; \theta)}\right).\]](https://aihub.org/wp-content/ql-cache/quicklatex.com-a0a93d6eee038e3e58d49dbc14fea886_l3.png "Rendered by QuickLaTeX.com")
TERM recovers ERM when  . It also recovers other popular alternatives such as the max-loss (
. It also recovers other popular alternatives such as the max-loss ( ) and min-loss (). While the tilted objective used in TERM is not new and is commonly used in other domains,1 it has not seen widespread use in machine learning.
) and min-loss (). While the tilted objective used in TERM is not new and is commonly used in other domains,1 it has not seen widespread use in machine learning.
In our work, we investigate tilting by: (i) rigorously studying properties of the TERM objective, and (ii) exploring its utility for a number of ML applications. Surprisingly, we find that this simple and general extension to ERM is competitive with state-of-the-art, problem-specific solutions for a wide range of problems in ML.
TERM: Properties and Interpretations
Given the modifications that TERM makes to ERM, the first question we ask is: What happens to the TERM objective when we vary ? Below we explore properties of TERM with varying to better understand the potential benefits of -tilted losses. In particular, we find:

 , and
, and  . ERM will minimize the average of the three losses, while TERM aggregates them via exponential tilting parameterized by a family of ’s. As moves from
. ERM will minimize the average of the three losses, while TERM aggregates them via exponential tilting parameterized by a family of ’s. As moves from  to
to  , -tilted losses smoothly move from min-loss to avg-loss to max-loss. The colored dots are optimal solutions of TERM for
, -tilted losses smoothly move from min-loss to avg-loss to max-loss. The colored dots are optimal solutions of TERM for  . TERM is smooth for all finite and convex for positive .
. TERM is smooth for all finite and convex for positive . - TERM with varying ’s reweights samples to magnify/suppress outliers (as in Figure 1).
- TERM smoothly moves between traditional ERM (pink line), the max-loss (red line), and min-loss (blue line), and can be used to trade-off between these problems.
- TERM approximates a popular family of quantile losses (such as median loss, shown in the orange line) with different tilting parameters. Quantile losses have nice properties but can be hard to directly optimize.
Next, we discuss these properties and interpretations in more detail.
Varying reweights the importance of outlier samples
First, we take a closer look at the gradient of the t-tilted loss, and observe that the gradients of the t-tilted objective  are of the form:
are of the form:
![\[\nabla_{\theta} \widetilde{R}(t; \theta) = \sum_{i \in [N]} w_i(t; \theta) \nabla_{\theta} f(x_i; \theta), \text{where } w_i \propto e^{tf(x_i; \theta)}.\]](https://aihub.org/wp-content/ql-cache/quicklatex.com-fb628115894b690e40577071d8d6f29f_l3.png "Rendered by QuickLaTeX.com")
This indicates that the tilted gradient is a weighted average of the gradients of the original individual losses, and the weights are exponentially proportional to the loss values. As illustrated in Figure 1, for positive values of , TERM will thus magnify outliers (samples with large losses), and for negative t’s, it will suppress outliers by downweighting them.
TERM offers a trade-off between the average loss and min-/max-loss
Another perspective on TERM is that it offers a continuum of solutions between the min and max losses. As goes from 0 to , the average loss will increase, and the max-loss will decrease (going from the pink star to the red star in Figure 2), smoothly trading average-loss for max-loss. Similarly, for  , the solutions achieve a smooth tradeoff between average-loss and min-loss. Additionally, as
, the solutions achieve a smooth tradeoff between average-loss and min-loss. Additionally, as  increases, the empirical variance of the losses across all samples also decreases. In the applications below we will see how these properties can be used in practice.
increases, the empirical variance of the losses across all samples also decreases. In the applications below we will see how these properties can be used in practice.
TERM solutions approximate superquantile methods
Finally, we note a connection to another popular variant on ERM: superquantile methods. The  -th quantile loss is defined as the -th largest individual loss among all samples, which may be useful for many applications. For example, optimizing for the median loss instead of mean may be desirable for applications in robustness, and the max-loss is an extreme of the quantile loss which can be used to enforce fairness. However, minimizing such objectives can be challenging especially in large-scale settings, as they are non-smooth (and generally non-convex). The TERM objective offers an upper bound on the given quantile of the losses, and the solutions of TERM can provide close approximations to the solutions of the quantile loss optimization problem.
-th quantile loss is defined as the -th largest individual loss among all samples, which may be useful for many applications. For example, optimizing for the median loss instead of mean may be desirable for applications in robustness, and the max-loss is an extreme of the quantile loss which can be used to enforce fairness. However, minimizing such objectives can be challenging especially in large-scale settings, as they are non-smooth (and generally non-convex). The TERM objective offers an upper bound on the given quantile of the losses, and the solutions of TERM can provide close approximations to the solutions of the quantile loss optimization problem.
[Note] All discussions above assume that the loss functions belong to generalized linear models. However, we empirically observe competitive performance when applying TERM to broader classes of objectives, including deep neural networks. Please see our paper for full statements and proofs.
TERM Applications
TERM is a general framework applicable to a variety of real-world machine learning problems. Using our understanding of TERM from the previous section, we can consider ‘tilting’ at different hierarchies of the data to adjust to the problem of interest. For instance, one can tilt at the sample level, as in the linear regression toy example. It is also natural to perform tilting at the group level to upweight underrepresented groups. Further, we can tilt at multiple levels to address practical applications requiring multiple objectives. In our work, we consider applying TERM to the following problems:
- [negative ’s]: robust regression, robust classification, mitigating noisy annotators
- [positive ’s]: handling class imbalance, fair PCA, variance reduction for generalization
- [hierarchical tilting with
 ]: jointly addressing robustness and fairness
]: jointly addressing robustness and fairness
For all applications considered, we find that TERM is competitive with or outperforms state-of-the-art, problem-specific tailored baselines. In this post, we discuss three examples on robust classification with , fair PCA with  , and hierarchical tilting.
, and hierarchical tilting.
Robust classification
Crowdsourcing is a popular technique for obtaining data labels from a large crowd of annotators. However, the quality of annotators varies significantly as annotators may be unskilled or even malicious. Thus, handling a large amount of noise is essential for the crowdsourcing setting. Here we consider applying TERM () to the application of mitigating noisy annotators.
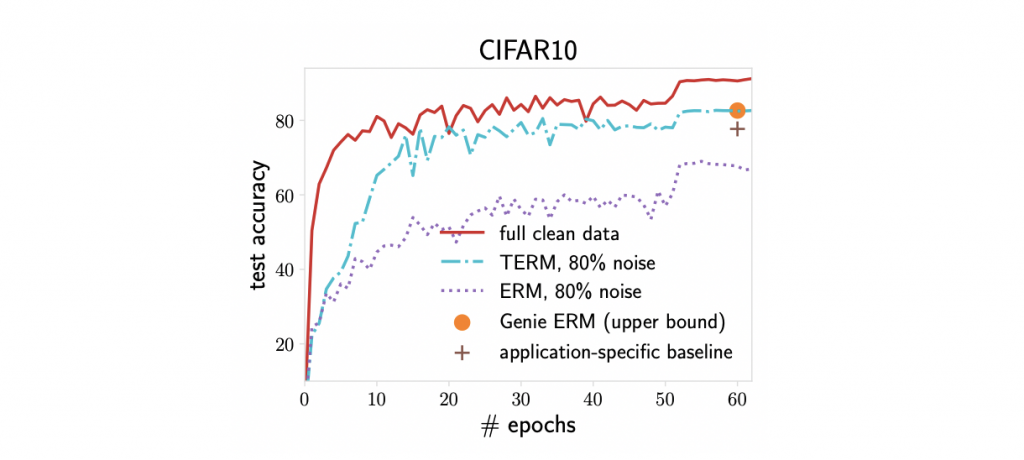
Specifically, we explore a common benchmark—taking the CIFAR10 dataset and simulating 100 annotators where 20 of them are always correct and 80 of them assign labels uniformly at random. We use negative ’s for annotator-level tilting, which is equivalent to assigning annotator-level weights based on the aggregate value of their loss.
Figure 3 demonstrates that our approach performs on par with the oracle method that knows the qualities of annotators in advance. Additionally, we find that the accuracy of TERM alone is 5% higher than that reported by previous approaches which are specifically designed for this problem.
Fair principal component analysis (PCA)
While the previous application explored TERM with , here we consider an application of TERM with positive ’s to fair PCA. PCA is commonly used for dimension reduction while preserving useful information of the original data for downstream tasks. The goal of fair PCA is to learn a projection that achieves similar (or the same) reconstruction errors across subgroups.
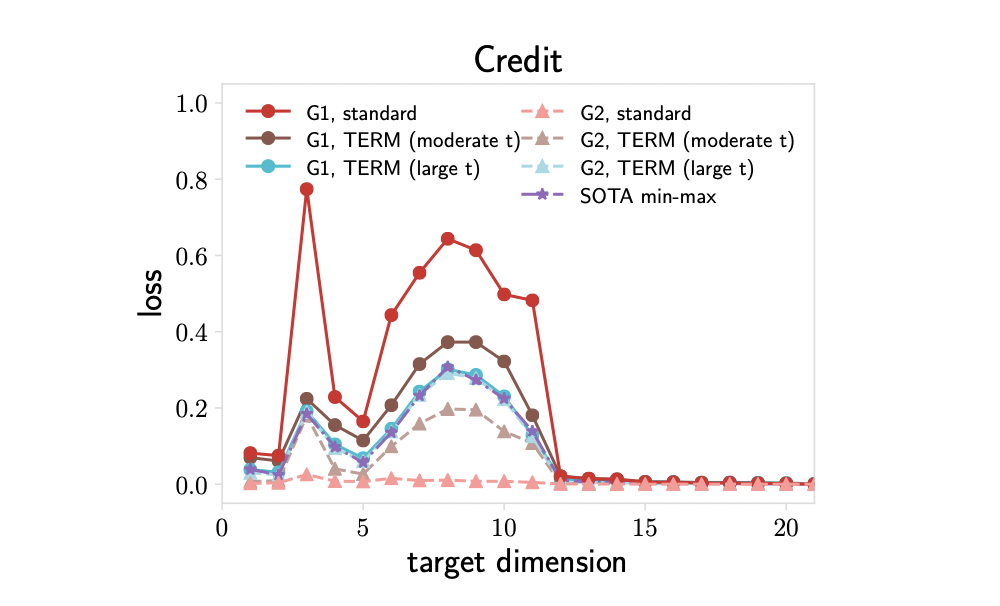
Applying standard PCA can be unfair to underrepresented groups. Figure 4 demonstrates that the classical PCA algorithm results in a large gap in the representation quality between two groups (G1 and G2).
To promote fairness, previous methods have proposed to solve a min-max problem via semidefinite programming, which scales poorly with the problem dimension. We apply TERM to this problem, reweighting the gradients based on the loss on each group. We see that TERM with a large can recover the min-max results where the resulting losses on two groups are almost identical. In addition, with moderate values of , TERM offers more flexible tradeoffs between performance and fairness by reducing the performance gap less aggressively.
Solving compound issues: multi-objective tilting
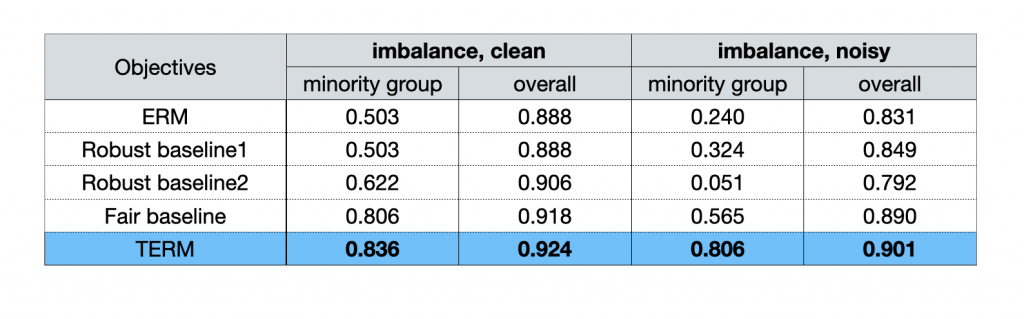
Finally, we note that in practice, multiple issues can co-exist in the data, e.g., we may have issues with both class imbalance and label noise. In these settings we can adopt hierarchical TERM as described previously to address compound issues. Depending on the application, one can choose whether to apply tilting at each level (e.g., possibly more than two levels of hierarchies exist in the data), and at either direction ( or ). For example, we can perform negative tilting at the sample level within each group to mitigate outlier samples, and perform positive tilting across all groups to promote fairness.
We test this protocol on the HIV-1 data with logistic regression. In Table 1 below, we find that TERM is superior to all baselines which perform well in their respective problem settings (only showing a subset here) when considering noisy samples and class imbalance simultaneously.
More broadly, the idea of tilting can be applied to other learning problems, like GAN training, meta-learning, and improving calibration and generalization for deep learning. We encourage interested readers to view our paper, which explores a more comprehensive set of applications.
[Solving TERM] Wondering how to solve TERM? In our work, we discuss the properties of the objective in terms of its smoothness and convexity behavior. Based on that, we develop both batch and (scalable) stochastic solvers for TERM, where the computation cost is within 2 of standard ERM solvers. We describe these algorithms as well as their convergence guarantees in our paper.
of standard ERM solvers. We describe these algorithms as well as their convergence guarantees in our paper.
Discussion
Our work explores tilted empirical risk minimization (TERM), a simple and general alternative to ERM, which is ubiquitous throughout machine learning. Our hope is that the TERM framework will allow machine learning practitioners to easily modify the ERM objective to handle practical concerns such as enforcing fairness amongst subgroups, mitigating the effect of outliers, and ensuring robust performance on new, unseen data. Critical to the success of such a framework is understanding the implications of the modified objective (i.e., the impact of varying ), both theoretically and empirically. Our work rigorously explores these effects—demonstrating the potential benefits of tilted objectives across a wide range of applications in machine learning.
Interested in learning more?
ACKNOWLEDGEMENT
Thanks to Maruan Al-Shedivat, Ahmad Beirami, Virginia Smith, and Ivan Stelmakh for feedback on this blog post.
Footnotes1 For instance, this type of exponential smoothing (when ) is commonly used to approximate the max. Variants of tilting have also appeared in other contexts, including importance sampling, decision making, and large deviation theory.
This article was initially published on the ML@CMU blog and appears here with the authors’ permission.

AUAI is supported by:








