
ΑΙhub.org
Pretrained transformers as universal computation engines
By Kevin Lu, Aditya Grover, Pieter Abbeel, and Igor Mordatch
Transformers have been successfully applied to a wide variety of modalities: natural language, vision, protein modeling, music, robotics, and more. A common trend with using large models is to train a transformer on a large amount of training data, and then finetune it on a downstream task. This enables the models to utilize generalizable high-level embeddings trained on a large dataset to avoid overfitting to a small task-relevant dataset.
We investigate a new setting where instead of transferring the high-level embeddings, we instead transfer the intermediate computation modules – instead of pretraining on a large image dataset and finetuning on a small image dataset, we might instead pretrain on a large language dataset and finetune on a small image dataset. Unlike conventional ideas that suggest the attention mechanism is specific to the training modality, we find that the self-attention layers can generalize to other modalities without finetuning.
To illustrate this, we take a pretrained transformer language model and finetune it on various classification tasks: numerical computation, vision, and protein fold prediction. Then, we freeze all the self-attention blocks except for the layer norm parameters. Finally, we add a new linear input layer to read in the new type of input, and reinitialize a linear output layer to perform classification on the new task. We refer to this as “Frozen Pretrained Transformer”.
Across the tasks, a token fed to the model represents a small amount of information: for example, it could be a single bit, or a 4×4 image patch. In particular, the tokens can only communicate with each other via the self-attention mechanism, which is not being trained at all on the downstream task. We investigate if these mechanisms – learned exclusively from natural language data – can be used for another modality in zero shot.
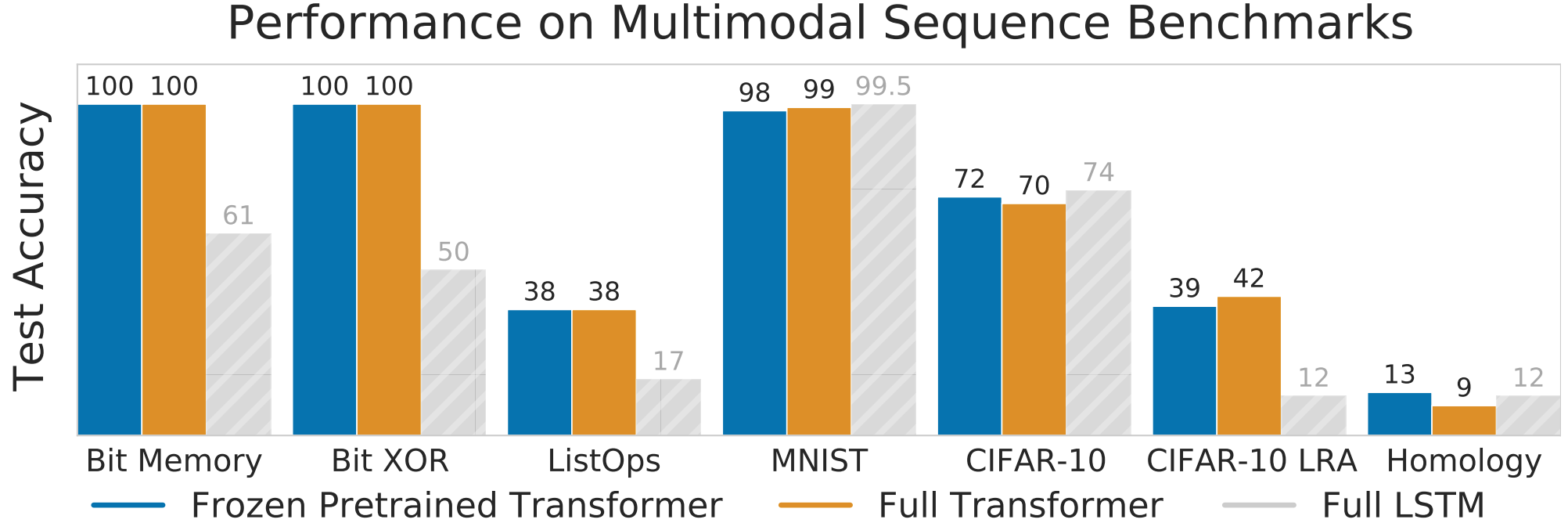
We show test accuracies for a variety of tasks below. We FPT can match or improve the performance of training a transformer fully from scratch! This indicates that, somehow, the attention mechanisms are general enough that we can feed in relatively arbitrary inputs and still generate useful embeddings for downstream classification.
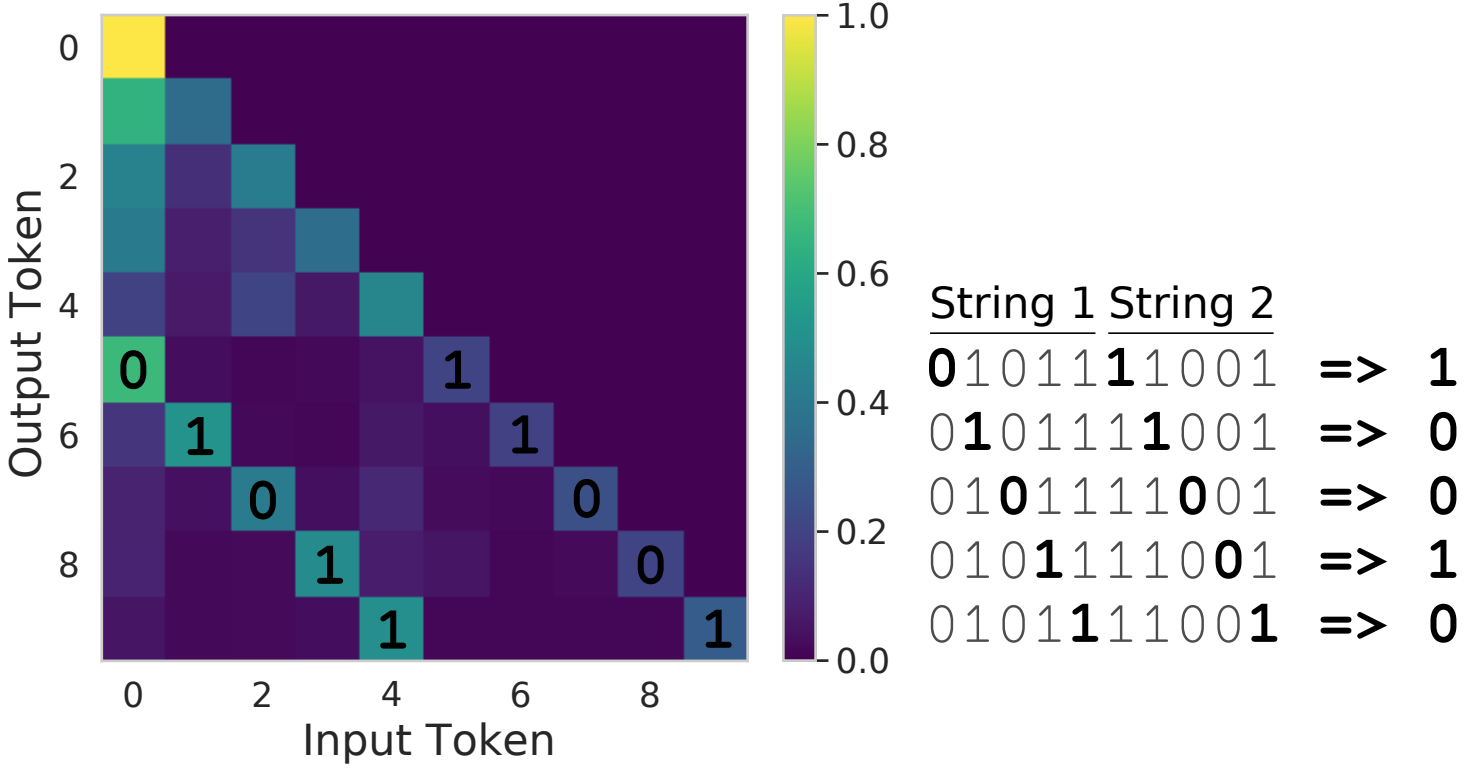
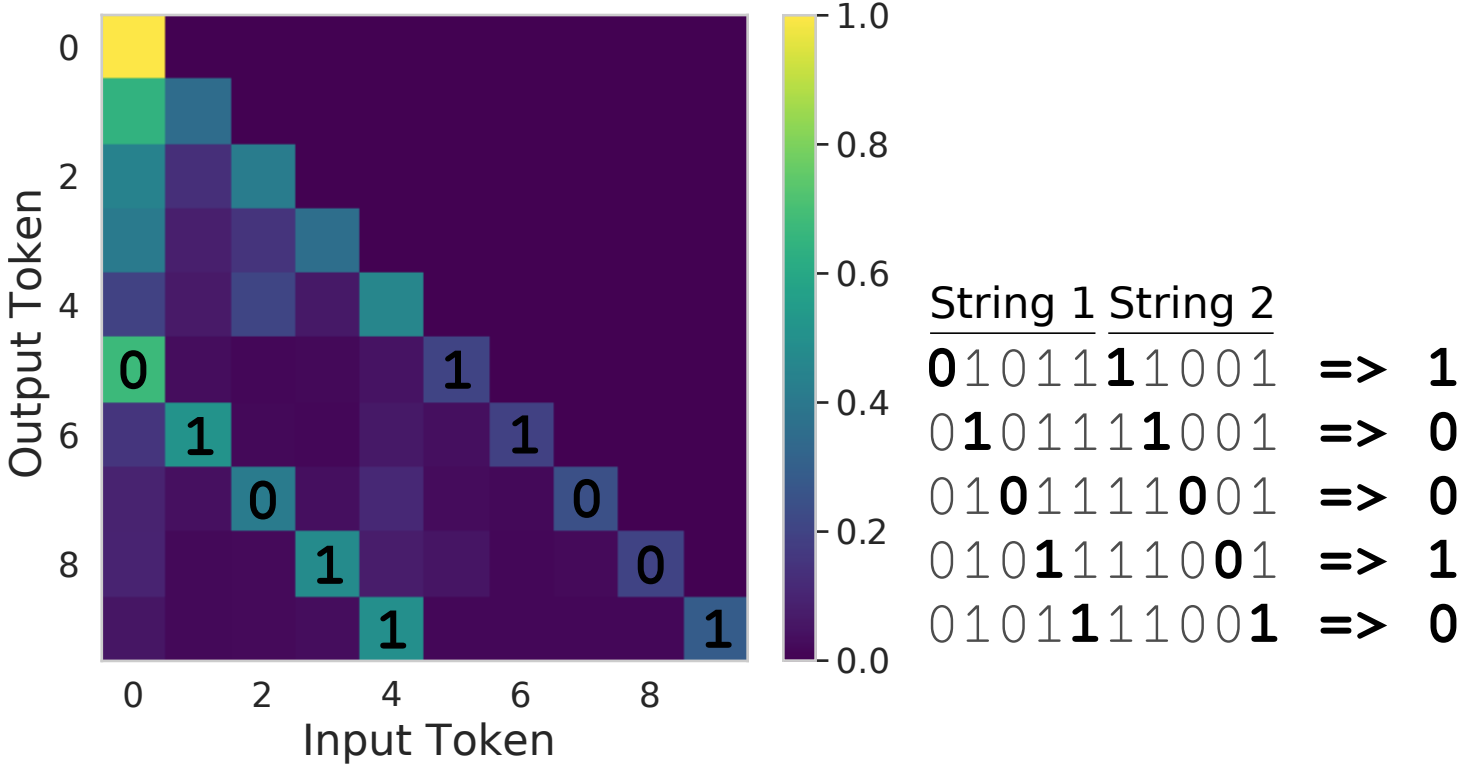
We also find that, when computing the elementwise XOR of two bitstrings, despite the self-attention parameters being frozen, by learning input embeddings to feed into the attention layer it is possible to force the self-attention to attend to the relevant bits for strings of length up to 256 (length of 5 shown below):
An open question is then what the benefit of pretraining on language is. Instead of initializing the transformer parameters from a pretrained model, we could instead initialize them randomly or by pretraining on the Bit Memory task, which ablate against no supervision or weak memory supervision, instead. Our results indicate that all three methods of initialization can work well, but language still performs the best, somehow providing an interesting set of pretrained layers: for example, on CIFAR-10, the base FPT model achieves an accuracy of 68%, versus 63% from Bit Memory pretraining or 62% from random initialization. Furthermore, we find the language-pretrained frozen transformers converge faster than the randomly initialized frozen transformers, typically by a factor of 1-4x, indicating that language might be a good starting point for other tasks.
We also find the transformer architecture itself to be very important. If we compare a randomly initialized frozen transformer to a randomly initialized frozen LSTM, the transformer significantly outperforms the LSTM: for example, 62% vs 34% on CIFAR-10. Thus, we think attention may already be a naturally good prior for multimodal generalization; we could think of self-attention as applying data-dependent filters.
We’re very interested in a better understanding of the capability of language models or hybrid-modality transformers for the goal of a universal computation engine. We think there are a lot of open questions to be explored in this space, and are excited to see new work in multimodal training.
This post is based on the following paper:
- Pretrained Transformers as Universal Computation Engines
Kevin Lu, Aditya Grover, Pieter Abbeel, and Igor Mordatch.
This article was initially published on the BAIR blog, and appears here with the authors’ permission.

AIhub is supported by:








