
ΑΙhub.org
Cost-effective speech-to-text with weakly- and semi-supervised training

The cost behind speech-to-text technology
Voice assistants equipped with speech-to-text technology have seen a major boost in performance and usage, thanks to the new powerful machine learning methods based on deep neural networks. These methods follow a supervised learning approach, requiring large amounts of paired speech-text data to train the best performing speech-to-text transcription models. After collecting large amounts of relevant and diverse spoken utterances, the complex and intensive task of annotating and labelling of the collected speech data awaits.
To get a feel for a typical scenario, let’s look at some estimates. On average a typical user query, for example “Do you have the Christmas edition with Santa?”, would last for about 3 seconds. A more interactive conversation between the user and the voice assistant might take about eight turns. This results in an average of about 24 seconds of data collected for each interactive conversation. In order to collect about 10 hours of unlabelled speech data, this implies that one would require about 3600s * 10h / 24s = 1500 diverse interactions. Human transcription of these spoken utterances can be achieved through crowdsourcing. A high-quality crowdsourcing job carried out through a subcontractor would cost in the order of one to several hundred US dollars per hour of speech data. Carrying out the job without a subcontractor, directly through a crowdsourcing platform, might be cheaper but would involve multiple procedures. For instance, one set of workers for transcribing the speech, another set of workers for verifying the transcriptions and finally a set of workers to choose between the first two.
Moreover, the audio data collection and transcription process needs to be repeated for every different language as well as when the domain of the application changes. The involved costs and efforts are often too high for small and medium sized enterprises willing to develop new voice services. This is also one of the major reasons behind the voice assistant market being dominated by a few big corporations.
Learning speech-to-text models with lesser human efforts
In favour of cost effectiveness, semi-supervised training of machine learning and neural network models has gained increased attention. Semi-supervised training of speech-to-text models involves automatically generating transcripts for a collection of unlabelled speech data with the help of seed models trained on small amounts of labelled speech data. However, the effectiveness of the semi-supervised training depends on the quality of the automatic transcripts obtained from the seed models. Moreover, domain mismatches between the existing data collection and the limited amount of realistic unlabelled speech data, a typical situation when building a new voice assistant app, will limit the performance of the semi-supervised training methods.
Weakly-supervised training methods try to exploit existing weak labels which are inexpensive and easier to obtain. The weak labels can be error patterns (e.g., chances of two phonemes/words being confused), high level labels (e.g., intent or dialogue act or dialogue state of an utterance in a dialogue), and/or additional information (e.g., entities allowed in a particular query). Weak labels such as these can be used to guide and improve the training of speech-to-text models. Moreover, such weak supervision can be used on top of semi-supervised training methods to achieve additional performance improvements.
Our approach in COMPRISE
In COMPRISE we have demonstrated the effectiveness of semi-supervised, as well as weakly-supervised training of both ‘acoustic and language’ models used by speech-to-text. We propose a new error detection driven semi-supervised training method, which uses an explicit error detection model to tag reliable word sequences among different alternative hypotheses obtained on the unlabelled speech data. This enables the semi-supervised training method to benefit from the automatic transcriptions in non-error regions and fall back to a background or unknown phoneme sequence in error regions, ultimately leading to better performing models. It should be noted that the error detection model itself is trained on a part of the small validation data, which would anyway be available for tuning the performance of speech-to-text models. The approach is depicted in the figure below.
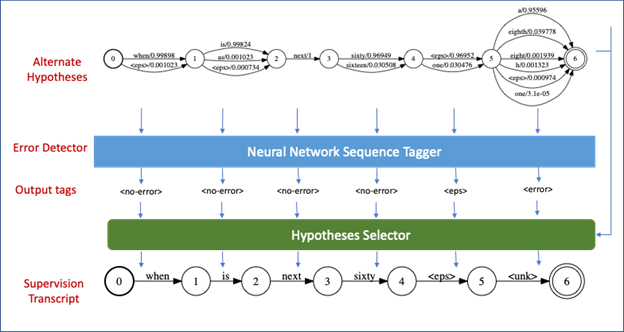
In addition to the error detection based semi-supervised training, COMPRISE also provides a weakly-supervised training method which can make use of additional information available from the voice assistant. The voice assistant dialogue models maintain the history and state of the dialogue to manage the flow of the conversation. A sample voice assistant dialogue and the possible dialogue states maintained internally by its dialogue system are shown below.
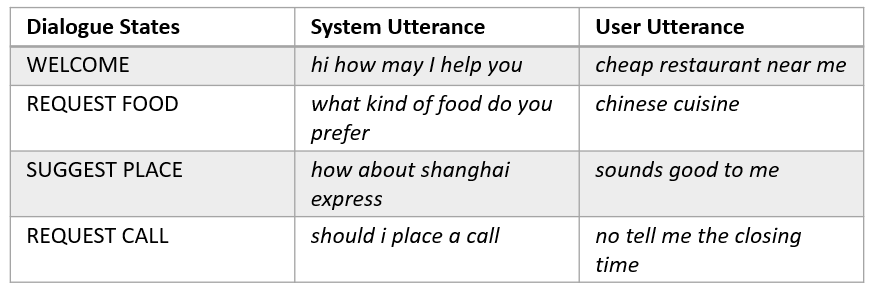
The actual transcription of the user utterance may not be available for training of the speech-to-text models. However, the corresponding dialogue states may be available, from the dialogue system or through inference on the non-reliable automatic transcriptions. These dialogue states can be used as weak labels to derive a more reliable automatic transcription of the user utterance. In practise we build multiple language models, each adapted to a specific dialogue state, which indeed result in better automatic transcriptions of the unlabelled speech.
The Word Error Rate (WER) graph below presents a quick evaluation of our proposed approaches for training speech-to-text conversion ‘acoustic and language’ models. The proposed error detection based semi-supervised training approach achieves a WER equivalent to that obtained with ~10.4 hours of labelled training data, whereas it actually only uses 4 hours. This implies a 39% relative cost reduction (considering an additional validation set is included in both cases). The state-of-the-art semi-supervised LF-MMI training method achieves a WER performance equivalent to that obtained with ~9.6 hours of labelled training data, which implies 36% relative cost reduction. When combining our dialogue state based weak supervision with our error detection driven semi-supervised training we achieve a WER performance equivalent to that obtained with ~11.4 hours of labelled training data. This implies 43% relative cost reductions.
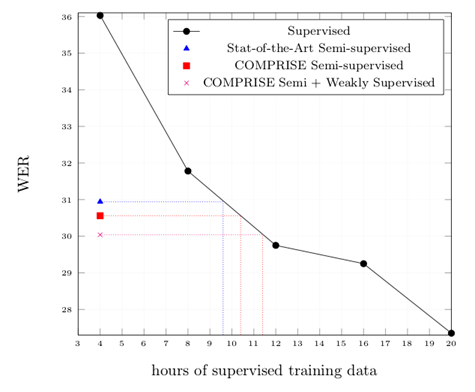
While our proposed methods have resulted in significant WER improvements and cost reductions, we continue to work on stronger training methods which can learn even better. We intend to do this by modelling the noise and uncertainty in the automatic speech-to-text transcriptions obtained on the unlabelled speech data.
About COMPRISE
COMPRISE (cost-effective, multilingual, privacy-driven voice-enabled services) is a European-funded Horizon 2020 project looking into the next generation of voice interaction services. The project aims to implement a fully private-by-design methodology and tools that will reduce the cost and increase the inclusiveness of voice interaction technology.
AUAI is supported by:








