
ΑΙhub.org
Hot papers on arXiv from the past month: July 2021
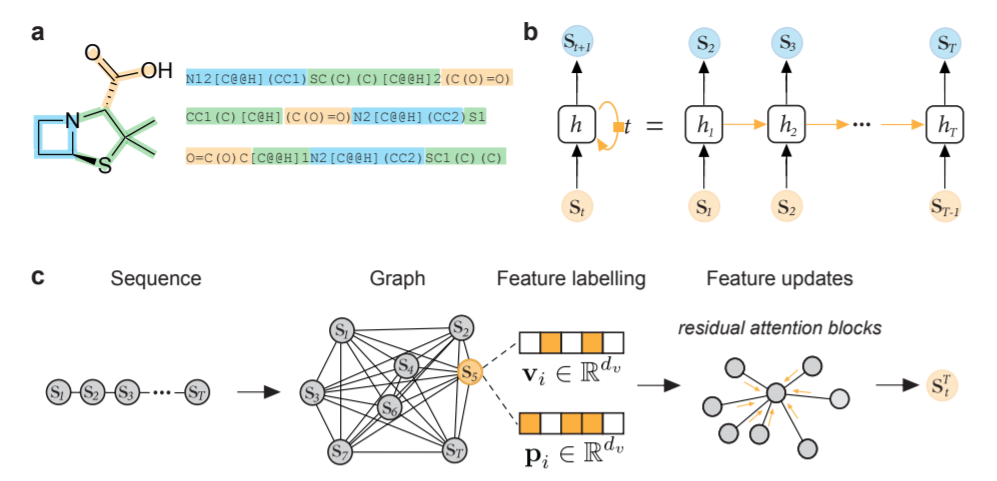
Chemical language modelling. a) SMILES strings, b) recurrent neural network, c) transformer-based language model. Taken from Geometric Deep Learning on Molecular Representations. Reproduced under a CC BY 4.0 license.
What’s hot on arXiv? Here are the most tweeted papers that were uploaded onto arXiv during July 2021.
Results are powered by Arxiv Sanity Preserver.
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, Wojciech Zaremba
Submitted to arXiv on: 7 July 2021
Abstract: We introduce Codex, a GPT language model fine-tuned on publicly available code from GitHub, and study its Python code-writing capabilities. A distinct production version of Codex powers GitHub Copilot. On HumanEval, a new evaluation set we release to measure functional correctness for synthesizing programs from docstrings, our model solves 28.8% of the problems, while GPT-3 solves 0% and GPT-J solves 11.4%. Furthermore, we find that repeated sampling from the model is a surprisingly effective strategy for producing working solutions to difficult prompts. Using this method, we solve 70.2% of our problems with 100 samples per problem. Careful investigation of our model reveals its limitations, including difficulty with docstrings describing long chains of operations and with binding operations to variables. Finally, we discuss the potential broader impacts of deploying powerful code generation technologies, covering safety, security, and economics.
120 tweets
EvilModel: Hiding Malware Inside of Neural Network Models
Zhi Wang, Chaoge Liu, Xiang Cui
Submitted to arXiv on: 19 July 2021
Abstract: Delivering malware covertly and evasively is critical to advanced malware campaigns. In this paper, we present a new method to covertly and evasively deliver malware through a neural network model. Neural network models are poorly explainable and have a good generalization ability. By embedding malware in neurons, the malware can be delivered covertly, with minor or no impact on the performance of neural network. Meanwhile, because the structure of the neural network model remains unchanged, it can pass the security scan of antivirus engines. Experiments show that 36.9MB of malware can be embedded in a 178MB-AlexNet model within 1% accuracy loss, and no suspicion is raised by anti-virus engines in VirusTotal, which verifies the feasibility of this method. With the widespread application of artificial intelligence, utilizing neural networks for attacks becomes a forwarding trend. We hope this work can provide a reference scenario for the defense on neural network-assisted attacks.
118 tweets
Variational Diffusion Models
Diederik P. Kingma, Tim Salimans, Ben Poole, Jonathan Ho
Submitted to arXiv on: 1 July 2021
Abstract: Diffusion-based generative models have demonstrated a capacity for perceptually impressive synthesis, but can they also be great likelihood-based models? We answer this in the affirmative, and introduce a family of diffusion-based generative models that obtain state-of-the-art likelihoods on standard image density estimation benchmarks. Unlike other diffusion-based models, our method allows for efficient optimization of the noise schedule jointly with the rest of the model. We show that the variational lower bound (VLB) simplifies to a remarkably short expression in terms of the signal-to-noise ratio of the diffused data, thereby improving our theoretical understanding of this model class. Using this insight, we prove an equivalence between several models proposed in the literature. In addition, we show that the continuous-time VLB is invariant to the noise schedule, except for the signal-to-noise ratio at its endpoints. This enables us to learn a noise schedule that minimizes the variance of the resulting VLB estimator, leading to faster optimization. Combining these advances with architectural improvements, we obtain state-of-the-art likelihoods on image density estimation benchmarks, outperforming autoregressive models that have dominated these benchmarks for many years, with often significantly faster optimization. In addition, we show how to turn the model into a bits-back compression scheme, and demonstrate lossless compression rates close to the theoretical optimum.
80 tweets
Painting Style-Aware Manga Colorization Based on Generative Adversarial Networks
Yugo Shimizu, Ryosuke Furuta, Delong Ouyang, Yukinobu Taniguchi, Ryota Hinami, Shonosuke Ishiwatari
Submitted to arXiv on: 16 July 2021
Abstract: Japanese comics (called manga) are traditionally created in monochrome format. In recent years, in addition to monochrome comics, full color comics, a more attractive medium, have appeared. Unfortunately, color comics require manual colorization, which incurs high labor costs. Although automatic colorization methods have been recently proposed, most of them are designed for illustrations, not for comics. Unlike illustrations, since comics are composed of many consecutive images, the painting style must be consistent. To realize consistent colorization, we propose here a semi-automatic colorization method based on generative adversarial networks (GAN); the method learns the painting style of a specific comic from small amount of training data. The proposed method takes a pair of a screen tone image and a flat colored image as input, and outputs a colorized image. Experiments show that the proposed method achieves better performance than the existing alternatives.
75 tweets
Real-Time Super-Resolution System of 4K-Video Based on Deep Learning
Yanpeng Cao, Chengcheng Wang, Changjun Song, Yongming Tang, He Li
Submitted to arXiv on: 12 July 2021
Abstract: Video super-resolution (VSR) technology excels in reconstructing low-quality video, avoiding unpleasant blur effect caused by interpolation-based algorithms. However, vast computation complexity and memory occupation hampers the edge of deplorability and the runtime inference in real-life applications, especially for large-scale VSR task. This paper explores the possibility of real-time VSR system and designs an efficient and generic VSR network, termed EGVSR. The proposed EGVSR is based on spatio-temporal adversarial learning for temporal coherence. In order to pursue faster VSR processing ability up to 4K resolution, this paper tries to choose lightweight network structure and efficient upsampling method to reduce the computation required by EGVSR network under the guarantee of high visual quality. Besides, we implement the batch normalization computation fusion, convolutional acceleration algorithm and other neural network acceleration techniques on the actual hardware platform to optimize the inference process of EGVSR network. Finally, our EGVSR achieves the real-time processing capacity of 4K@29.61FPS. Compared with TecoGAN, the most advanced VSR network at present, we achieve 85.04% reduction of computation density and 7.92x performance speedups. In terms of visual quality, the proposed EGVSR tops the list of most metrics (such as LPIPS, tOF, tLP, etc.) on the public test dataset Vid4 and surpasses other state-of-the-art methods in overall performance score. The source code of this project can be found on this https URL.
69 tweets
The Benchmark Lottery
Mostafa Dehghani, Yi Tay, Alexey A. Gritsenko, Zhe Zhao, Neil Houlsby, Fernando Diaz, Donald Metzler, Oriol Vinyals
Submitted to arXiv on: 14 July 2021
Abstract: The world of empirical machine learning (ML) strongly relies on benchmarks in order to determine the relative effectiveness of different algorithms and methods. This paper proposes the notion of “a benchmark lottery” that describes the overall fragility of the ML benchmarking process. The benchmark lottery postulates that many factors, other than fundamental algorithmic superiority, may lead to a method being perceived as superior. On multiple benchmark setups that are prevalent in the ML community, we show that the relative performance of algorithms may be altered significantly simply by choosing different benchmark tasks, highlighting the fragility of the current paradigms and potential fallacious interpretation derived from benchmarking ML methods. Given that every benchmark makes a statement about what it perceives to be important, we argue that this might lead to biased progress in the community. We discuss the implications of the observed phenomena and provide recommendations on mitigating them using multiple machine learning domains and communities as use cases, including natural language processing, computer vision, information retrieval, recommender systems, and reinforcement learning.
66 tweets
Geometric Deep Learning on Molecular Representations
Kenneth Atz, Francesca Grisoni, Gisbert Schneider
Submitted to arXiv on: 26 July 2021
Abstract: Geometric deep learning (GDL), which is based on neural network architectures that incorporate and process symmetry information, has emerged as a recent paradigm in artificial intelligence. GDL bears particular promise in molecular modeling applications, in which various molecular representations with different symmetry properties and levels of abstraction exist. This review provides a structured and harmonized overview of molecular GDL, highlighting its applications in drug discovery, chemical synthesis prediction, and quantum chemistry. Emphasis is placed on the relevance of the learned molecular features and their complementarity to well-established molecular descriptors. This review provides an overview of current challenges and opportunities, and presents a forecast of the future of GDL for molecular sciences.
61 tweets
A Survey on Data Augmentation for Text Classification
Markus Bayer, Marc-André Kaufhold, Christian Reuter
Submitted to arXiv on: 7 July 2021
Abstract: Data augmentation, the artificial creation of training data for machine learning by transformations, is a widely studied research field across machine learning disciplines. While it is useful for increasing the generalization capabilities of a model, it can also address many other challenges and problems, from overcoming a limited amount of training data over regularizing the objective to limiting the amount data used to protect privacy. Based on a precise description of the goals and applications of data augmentation (C1) and a taxonomy for existing works (C2), this survey is concerned with data augmentation methods for textual classification and aims to achieve a concise and comprehensive overview for researchers and practitioners (C3). Derived from the taxonomy, we divided more than 100 methods into 12 different groupings and provide state-of-the-art references expounding which methods are highly promising (C4). Finally, research perspectives that may constitute a building block for future work are given (C5).
59 tweets
YOLOX: Exceeding YOLO Series in 2021
Zheng Ge, Songtao Liu, Feng Wang, Zeming Li, Jian Sun
Submitted to arXiv on: 18 July 2021
Abstract: In this report, we present some experienced improvements to YOLO series, forming a new high-performance detector — YOLOX. We switch the YOLO detector to an anchor-free manner and conduct other advanced detection techniques, i.e., a decoupled head and the leading label assignment strategy SimOTA to achieve state-of-the-art results across a large scale range of models: For YOLO-Nano with only 0.91M parameters and 1.08G FLOPs, we get 25.3% AP on COCO, surpassing NanoDet by 1.8% AP; for YOLOv3, one of the most widely used detectors in industry, we boost it to 47.3% AP on COCO, outperforming the current best practice by 3.0% AP; for YOLOX-L with roughly the same amount of parameters as YOLOv4-CSP, YOLOv5-L, we achieve 50.0% AP on COCO at a speed of 68.9 FPS on Tesla V100, exceeding YOLOv5-L by 1.8% AP. Further, we won the 1st Place on Streaming Perception Challenge (Workshop on Autonomous Driving at CVPR 2021) using a single YOLOX-L model. We hope this report can provide useful experience for developers and researchers in practical scenes, and we also provide deploy versions with ONNX, TensorRT, NCNN, and Openvino supported. Source code is at this https URL.
53 tweets
tags: arXiv

AUAI is supported by:








