
ΑΙhub.org
Hot papers on arXiv from the past month: August 2021
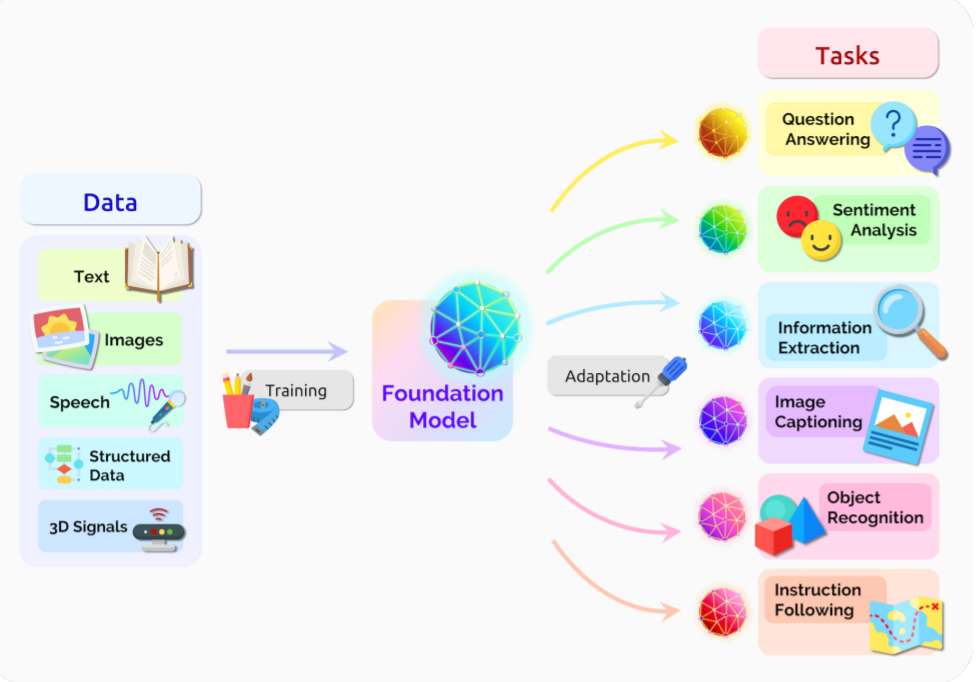
Foundation model schematic. From On the opportunities and risks of foundation models. Reproduced under a CC BY 4.0 license.
What’s hot on arXiv? Here are the most tweeted papers that were uploaded onto arXiv during August 2021.
Results are powered by Arxiv Sanity Preserver.
How to avoid machine learning pitfalls: a guide for academic researchers
Michael A. Lones
Submitted to arXiv on: 5 August 2021
Abstract: This document gives a concise outline of some of the common mistakes that occur when using machine learning techniques, and what can be done to avoid them. It is intended primarily as a guide for research students, and focuses on issues that are of particular concern within academic research, such as the need to do rigorous comparisons and reach valid conclusions. It covers five stages of the machine learning process: what to do before model building, how to reliably build models, how to robustly evaluate models, how to compare models fairly, and how to report results.
886 tweets
Do vision transformers see like convolutional neural networks?
Maithra Raghu, Thomas Unterthiner, Simon Kornblith, Chiyuan Zhang, Alexey Dosovitskiy
Submitted to arXiv on: 19 August 2021
Abstract: Convolutional neural networks (CNNs) have so far been the de-facto model for visual data. Recent work has shown that (Vision) Transformer models (ViT) can achieve comparable or even superior performance on image classification tasks. This raises a central question: how are Vision Transformers solving these tasks? Are they acting like convolutional networks, or learning entirely different visual representations? Analyzing the internal representation structure of ViTs and CNNs on image classification benchmarks, we find striking differences between the two architectures, such as ViT having more uniform representations across all layers. We explore how these differences arise, finding crucial roles played by self-attention, which enables early aggregation of global information, and ViT residual connections, which strongly propagate features from lower to higher layers. We study the ramifications for spatial localization, demonstrating ViTs successfully preserve input spatial information, with noticeable effects from different classification methods. Finally, we study the effect of (pretraining) dataset scale on intermediate features and transfer learning, and conclude with a discussion on connections to new architectures such as the MLP-Mixer.
286 tweets
Program synthesis with large language models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, Charles Sutton
Submitted to arXiv on: 16 August 2021
Abstract: This paper explores the limits of the current generation of large language models for program synthesis in general purpose programming languages. We evaluate a collection of such models (with between 244M and 137B parameters) on two new benchmarks, MBPP and MathQA-Python, in both the few-shot and fine-tuning regimes. Our benchmarks are designed to measure the ability of these models to synthesize short Python programs from natural language descriptions. The Mostly Basic Programming Problems (MBPP) dataset contains 974 programming tasks, designed to be solvable by entry-level programmers. The MathQA-Python dataset, a Python version of the MathQA benchmark, contains 23914 problems that evaluate the ability of the models to synthesize code from more complex text. On both datasets, we find that synthesis performance scales log-linearly with model size. Our largest models, even without finetuning on a code dataset, can synthesize solutions to 59.6 percent of the problems from MBPP using few-shot learning with a well-designed prompt. Fine-tuning on a held-out portion of the dataset improves performance by about 10 percentage points across most model sizes. On the MathQA-Python dataset, the largest fine-tuned model achieves 83.8 percent accuracy. Going further, we study the model’s ability to engage in dialog about code, incorporating human feedback to improve its solutions. We find that natural language feedback from a human halves the error rate compared to the model’s initial prediction. Additionally, we conduct an error analysis to shed light on where these models fall short and what types of programs are most difficult to generate. Finally, we explore the semantic grounding of these models by fine-tuning them to predict the results of program execution. We find that even our best models are generally unable to predict the output of a program given a specific input.
198 tweets
Isaac Gym: high performance GPU-based physics simulation for robot learning
Viktor Makoviychuk, Lukasz Wawrzyniak, Yunrong Guo, Michelle Lu, Kier Storey, Miles Macklin, David Hoeller, Nikita Rudin, Arthur Allshire, Ankur Handa, Gavriel State
Submitted to arXiv on: 24 August 2021
Abstract: Isaac Gym offers a high performance learning platform to train policies for wide variety of robotics tasks directly on GPU. Both physics simulation and the neural network policy training reside on GPU and communicate by directly passing data from physics buffers to PyTorch tensors without ever going through any CPU bottlenecks. This leads to blazing fast training times for complex robotics tasks on a single GPU with 2-3 orders of magnitude improvements compared to conventional RL training that uses a CPU based simulator and GPU for neural networks. We host the results and videos at this https URL and isaac gym can be downloaded at this https URL.
140 tweets
On the opportunities and risks of foundation models
Rishi Bommasani, Drew A. Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S. Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, Erik Brynjolfsson, Shyamal Buch, Dallas Card, Rodrigo Castellon, Niladri Chatterji, Annie Chen, Kathleen Creel, Jared Quincy Davis, Dora Demszky, Chris Donahue, Moussa Doumbouya, Esin Durmus, Stefano Ermon, John Etchemendy, Kawin Ethayarajh, Li Fei-Fei, Chelsea Finn, Trevor Gale, Lauren Gillespie, Karan Goel, Noah Goodman, Shelby Grossman, Neel Guha, Tatsunori Hashimoto, Peter Henderson, John Hewitt, Daniel E. Ho, Jenny Hong, Kyle Hsu, Jing Huang, Thomas Icard, Saahil Jain, Dan Jurafsky, Pratyusha Kalluri, Siddharth Karamcheti, Geoff Keeling, Fereshte Khani, Omar Khattab, Pang Wei Kohd, Mark Krass, Ranjay Krishna, Rohith Kuditipudi, Ananya Kumar, Faisal Ladhak, Mina Lee, Tony Lee, Jure Leskovec, Isabelle Levent, Xiang Lisa Li, Xuechen Li, Tengyu Ma, Ali Malik, Christopher D. Manning, Suvir Mirchandani, Eric Mitchell, Zanele Munyikwa, Suraj Nair, Avanika Narayan, Deepak Narayanan, Ben Newman, Allen Nie, Juan Carlos Niebles, Hamed Nilforoshan, Julian Nyarko, Giray Ogut, Laurel Orr, Isabel Papadimitriou, Joon Sung Park, Chris Piech, Eva Portelance, Christopher Potts, Aditi Raghunathan, Rob Reich, Hongyu Ren, Frieda Rong, Yusuf Roohani, Camilo Ruiz, Jack Ryan, Christopher Ré, Dorsa Sadigh, Shiori Sagawa, Keshav Santhanam, Andy Shih, Krishnan Srinivasan, Alex Tamkin, Rohan Taori, Armin W. Thomas, Florian Tramèr, Rose E. Wang, William Wang , Bohan Wu, Jiajun Wu, Yuhuai Wu, Sang Michael Xie, Michihiro Yasunaga, Jiaxuan You, Matei Zaharia, Michael Zhang, Tianyi Zhang, Xikun Zhang, Yuhui Zhang, Lucia Zheng, Kaitlyn Zhou, Percy Liang
Submitted to arXiv on: 16 August 2021
Abstract: AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities, and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
137 tweets
AMMUS : a survey of transformer-based pretrained models in natural language processing
Katikapalli Subramanyam Kalyan, Ajit Rajasekharan, Sivanesan Sangeetha
Submitted to arXiv on: 12 August 2021
Abstract: Transformer-based pretrained language models (T-PTLMs) have achieved great success in almost every NLP task. The evolution of these models started with GPT and BERT. These models are built on the top of transformers, self-supervised learning and transfer learning. Transformed-based PTLMs learn universal language representations from large volumes of text data using self-supervised learning and transfer this knowledge to downstream tasks. These models provide good background knowledge to downstream tasks which avoids training of downstream models from scratch. In this comprehensive survey paper, we initially give a brief overview of self-supervised learning. Next, we explain various core concepts like pretraining, pretraining methods, pretraining tasks, embeddings and downstream adaptation methods. Next, we present a new taxonomy of T-PTLMs and then give brief overview of various benchmarks including both intrinsic and extrinsic. We present a summary of various useful libraries to work with T-PTLMs. Finally, we highlight some of the future research directions which will further improve these models. We strongly believe that this comprehensive survey paper will serve as a good reference to learn the core concepts as well as to stay updated with the recent happenings in T-PTLMs.
129 tweets
m-RevNet: deep reversible neural networks with momentum
Duo Li, Shang-Hua Gao
Submitted to arXiv on: 12 August 2021
Abstract: In recent years, the connections between deep residual networks and first-order Ordinary Differential Equations (ODEs) have been disclosed. In this work, we further bridge the deep neural architecture design with the second-order ODEs and propose a novel reversible neural network, termed as m-RevNet, that is characterized by inserting momentum update to residual blocks. The reversible property allows us to perform backward pass without access to activation values of the forward pass, greatly relieving the storage burden during training. Furthermore, the theoretical foundation based on second-order ODEs grants m-RevNet with stronger representational power than vanilla residual networks, which potentially explains its performance gains. For certain learning scenarios, we analytically and empirically reveal that our m-RevNet succeeds while standard ResNet fails. Comprehensive experiments on various image classification and semantic segmentation benchmarks demonstrate the superiority of our m-RevNet over ResNet, concerning both memory efficiency and recognition performance.
118 tweets
An empirical cybersecurity evaluation of GitHub copilot’s code contributions
Hammond Pearce, Baleegh Ahmad, Benjamin Tan, Brendan Dolan-Gavitt, Ramesh Karri
Submitted to arXiv on: 20 August 2021
Abstract: There is burgeoning interest in designing AI-based systems to assist humans in designing computing systems, including tools that automatically generate computer code. The most notable of these comes in the form of the first self-described `AI pair programmer’, GitHub Copilot, a language model trained over open-source GitHub code. However, code often contains bugs – and so, given the vast quantity of unvetted code that Copilot has processed, it is certain that the language model will have learned from exploitable, buggy code. This raises concerns on the security of Copilot’s code contributions. In this work, we systematically investigate the prevalence and conditions that can cause GitHub Copilot to recommend insecure code. To perform this analysis we prompt Copilot to generate code in scenarios relevant to high-risk CWEs (e.g. those from MITRE’s “Top 25” list). We explore Copilot’s performance on three distinct code generation axes — examining how it performs given diversity of weaknesses, diversity of prompts, and diversity of domains. In total, we produce 89 different scenarios for Copilot to complete, producing 1,692 programs. Of these, we found approximately 40% to be vulnerable.
48 tweets
Reassessing the limitations of CNN methods for camera pose regression
Tony Ng, Adrian Lopez-Rodriguez, Vassileios Balntas, Krystian Mikolajczyk
Submitted to arXiv on: 16 August 2021
Abstract: In this paper, we address the problem of camera pose estimation in outdoor and indoor scenarios. In comparison to the currently top-performing methods that rely on 2D to 3D matching, we propose a model that can directly regress the camera pose from images with significantly higher accuracy than existing methods of the same class. We first analyse why regression methods are still behind the state-of-the-art, and we bridge the performance gap with our new approach. Specifically, we propose a way to overcome the biased training data by a novel training technique, which generates poses guided by a probability distribution from the training set for synthesising new training views. Lastly, we evaluate our approach on two widely used benchmarks and show that it achieves significantly improved performance compared to prior regression-based methods, retrieval techniques as well as 3D pipelines with local feature matching.
44 tweets
Fastformer: additive attention can be all you need
Chuhan Wu, Fangzhao Wu, Tao Qi, Yongfeng Huang, Xing Xie
Submitted to arXiv on: 20 August 2021
Abstract: Transformer is a powerful model for text understanding. However, it is inefficient due to its quadratic complexity to input sequence length. Although there are many methods on Transformer acceleration, they are still either inefficient on long sequences or not effective enough. In this paper, we propose Fastformer, which is an efficient Transformer model based on additive attention. In Fastformer, instead of modeling the pair-wise interactions between tokens, we first use additive attention mechanism to model global contexts, and then further transform each token representation based on its interaction with global context representations. In this way, Fastformer can achieve effective context modeling with linear complexity. Extensive experiments on five datasets show that Fastformer is much more efficient than many existing Transformer models and can meanwhile achieve comparable or even better long text modeling performance.
43 tweets
tags: arXiv

AUAI is supported by:








