
ΑΙhub.org
Hot papers on arXiv from the past month: October 2021
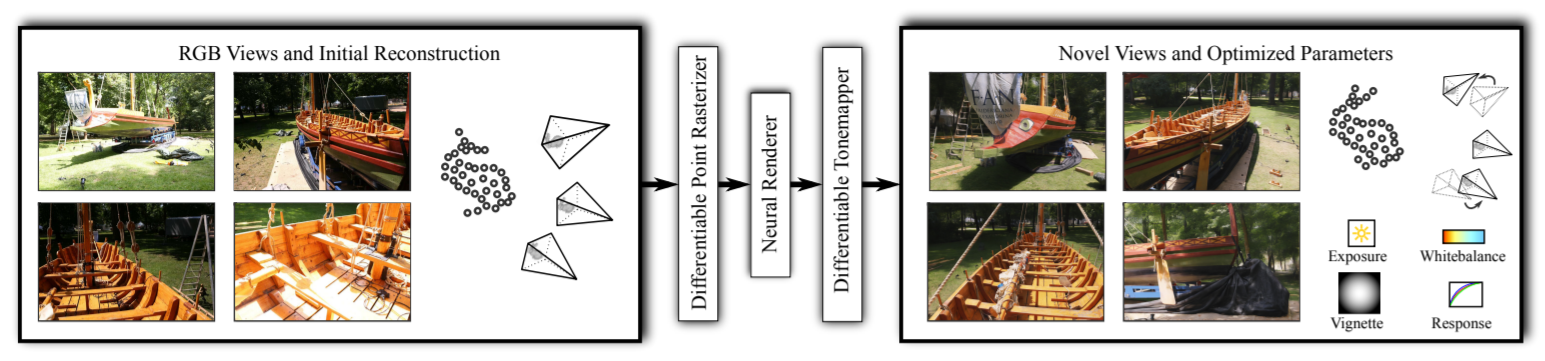
Given a set of RGB images and an initial 3D reconstruction (left), this inverse rendering approach is able to synthesize novel frames and optimize the scene’s parameters (right). From ADOP: Approximate Differentiable One-Pixel Point Rendering. Reproduced under a CC BY 4.0 license.
What’s hot on arXiv? Here are the most tweeted papers that were uploaded onto arXiv during October 2021.
Results are powered by Arxiv Sanity Preserver.
ADOP: Approximate Differentiable One-Pixel Point Rendering
Darius Rückert, Linus Franke, Marc Stamminger
Submitted to arXiv on: 13 October 2021
Abstract: We present a novel point-based, differentiable neural rendering pipeline for scene refinement and novel view synthesis. The input are an initial estimate of the point cloud and the camera parameters. The output are synthesized images from arbitrary camera poses. The point cloud rendering is performed by a differentiable renderer using multi-resolution one-pixel point rasterization. Spatial gradients of the discrete rasterization are approximated by the novel concept of ghost geometry. After rendering, the neural image pyramid is passed through a deep neural network for shading calculations and hole-filling. A differentiable, physically-based tonemapper then converts the intermediate output to the target image. Since all stages of the pipeline are differentiable, we optimize all of the scene’s parameters i.e. camera model, camera pose, point position, point color, environment map, rendering network weights, vignetting, camera response function, per image exposure, and per image white balance. We show that our system is able to synthesize sharper and more consistent novel views than existing approaches because the initial reconstruction is refined during training. The efficient one-pixel point rasterization allows us to use arbitrary camera models and display scenes with well over 100M points in real time.
966 tweets
Delphi: Towards Machine Ethics and Norms
Liwei Jiang, Jena D. Hwang, Chandra Bhagavatula, Ronan Le Bras, Maxwell Forbes, Jon Borchardt, Jenny Liang, Oren Etzioni, Maarten Sap, Yejin Choi
Submitted to arXiv on: 14 October 2021
Abstract: What would it take to teach a machine to behave ethically? While broad ethical rules may seem straightforward to state (“thou shalt not kill”), applying such rules to real-world situations is far more complex. For example, while “helping a friend” is generally a good thing to do, “helping a friend spread fake news” is not. We identify four underlying challenges towards machine ethics and norms: (1) an understanding of moral precepts and social norms; (2) the ability to perceive real-world situations visually or by reading natural language descriptions; (3) commonsense reasoning to anticipate the outcome of alternative actions in different contexts; (4) most importantly, the ability to make ethical judgments given the interplay between competing values and their grounding in different contexts (e.g., the right to freedom of expression vs. preventing the spread of fake news). Our paper begins to address these questions within the deep learning paradigm. Our prototype model, Delphi, demonstrates strong promise of language-based commonsense moral reasoning, with up to 92.1% accuracy vetted by humans. This is in stark contrast to the zero-shot performance of GPT-3 of 52.3%, which suggests that massive scale alone does not endow pre-trained neural language models with human values. Thus, we present Commonsense Norm Bank, a moral textbook customized for machines, which compiles 1.7M examples of people’s ethical judgments on a broad spectrum of everyday situations. In addition to the new resources and baseline performances for future research, our study provides new insights that lead to several important open research questions: differentiating between universal human values and personal values, modeling different moral frameworks, and explainable, consistent approaches to machine ethics.
205 tweets
Multitask Prompted Training Enables Zero-Shot Task Generalization
Victor Sanh, Albert Webson, Colin Raffel, Stephen H. Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Teven Le Scao, Arun Raja, Manan Dey, M Saiful Bari, Canwen Xu, Urmish Thakker, Shanya Sharma Sharma, Eliza Szczechla, Taewoon Kim, Gunjan Chhablani, Nihal Nayak, Debajyoti Datta, Jonathan Chang, Mike Tian-Jian Jiang, Han Wang, Matteo Manica, Sheng Shen, Zheng Xin Yong, Harshit Pandey, Rachel Bawden, Thomas Wang, Trishala Neeraj, Jos Rozen, Abheesht Sharma, Andrea Santilli, Thibault Fevry, Jason Alan Fries, Ryan Teehan, Stella Biderman, Leo Gao, Tali Bers, Thomas Wolf, Alexander M. Rush
Submitted to arXiv on: 15 October 2021
Abstract: Large language models have recently been shown to attain reasonable zero-shot generalization on a diverse set of tasks. It has been hypothesized that this is a consequence of implicit multitask learning in language model training. Can zero-shot generalization instead be directly induced by explicit multitask learning? To test this question at scale, we develop a system for easily mapping general natural language tasks into a human-readable prompted form. We convert a large set of supervised datasets, each with multiple prompts using varying natural language. These prompted datasets allow for benchmarking the ability of a model to perform completely unseen tasks specified in natural language. We fine-tune a pretrained encoder-decoder model on this multitask mixture covering a wide variety of tasks. The model attains strong zero-shot performance on several standard datasets, often outperforming models 16x its size. Further, our approach attains strong performance on a subset of tasks from the BIG-Bench benchmark, outperforming models 6x its size. All prompts and trained models are available at this http URL.
113 tweets
Nonnegative spatial factorization
F. William Townes, Barbara E. Engelhardt
Submitted to arXiv on: 12 October 2021
Abstract: Gaussian processes are widely used for the analysis of spatial data due to their nonparametric flexibility and ability to quantify uncertainty, and recently developed scalable approximations have facilitated application to massive datasets. For multivariate outcomes, linear models of coregionalization combine dimension reduction with spatial correlation. However, their real-valued latent factors and loadings are difficult to interpret because, unlike nonnegative models, they do not recover a parts-based representation. We present nonnegative spatial factorization (NSF), a spatially-aware probabilistic dimension reduction model that naturally encourages sparsity. We compare NSF to real-valued spatial factorizations such as MEFISTO and nonspatial dimension reduction methods using simulations and high-dimensional spatial transcriptomics data. NSF identifies generalizable spatial patterns of gene expression. Since not all patterns of gene expression are spatial, we also propose a hybrid extension of NSF that combines spatial and nonspatial components, enabling quantification of spatial importance for both observations and features. A TensorFlow implementation of NSF is available from this https URL.
82 tweets
StyleAlign: Analysis and Applications of Aligned StyleGAN Models
Zongze Wu, Yotam Nitzan, Eli Shechtman, Dani Lischinski
Submitted to arXiv on: 21 October 2021
Abstract: In this paper, we perform an in-depth study of the properties and applications of aligned generative models. We refer to two models as aligned if they share the same architecture, and one of them (the child) is obtained from the other (the parent) via fine-tuning to another domain, a common practice in transfer learning. Several works already utilize some basic properties of aligned StyleGAN models to perform image-to-image translation. Here, we perform the first detailed exploration of model alignment, also focusing on StyleGAN. First, we empirically analyze aligned models and provide answers to important questions regarding their nature. In particular, we find that the child model’s latent spaces are semantically aligned with those of the parent, inheriting incredibly rich semantics, even for distant data domains such as human faces and churches. Second, equipped with this better understanding, we leverage aligned models to solve a diverse set of tasks. In addition to image translation, we demonstrate fully automatic cross-domain image morphing. We further show that zero-shot vision tasks may be performed in the child domain, while relying exclusively on supervision in the parent domain. We demonstrate qualitatively and quantitatively that our approach yields state-of-the-art results, while requiring only simple fine-tuning and inversion.
73 tweets
Learning in High Dimension Always Amounts to Extrapolation
Randall Balestriero, Jerome Pesenti, Yann LeCun
Submitted to arXiv on: 18 October 2021
Abstract: The notion of interpolation and extrapolation is fundamental in various fields from deep learning to function approximation. Interpolation occurs for a sample x whenever this sample falls inside or on the boundary of the given dataset’s convex hull. Extrapolation occurs when x falls outside of that convex hull. One fundamental (mis)conception is that state-of-the-art algorithms work so well because of their ability to correctly interpolate training data. A second (mis)conception is that interpolation happens throughout tasks and datasets, in fact, many intuitions and theories rely on that assumption. We empirically and theoretically argue against those two points and demonstrate that on any high-dimensional (>100) dataset, interpolation almost surely never happens. Those results challenge the validity of our current interpolation/extrapolation definition as an indicator of generalization performances.
71 tweets
Deep Learning Tools for Audacity: Helping Researchers Expand the Artist’s Toolkit
Hugo Flores Garcia, Aldo Aguilar, Ethan Manilow, Dmitry Vedenko, Bryan Pardo
Submitted to arXiv on: 25 October 2021
Abstract: We present a software framework that integrates neural networks into the popular open-source audio editing software, Audacity, with a minimal amount of developer effort. In this paper, we showcase some example use cases for both end-users and neural network developers. We hope that this work fosters a new level of interactivity between deep learning practitioners and end-users.
68 tweets
ByteTrack: Multi-Object Tracking by Associating Every Detection Box
Yifu Zhang, Peize Sun, Yi Jiang, Dongdong Yu, Zehuan Yuan, Ping Luo, Wenyu Liu, Xinggang Wang
Submitted to arXiv on: 13 October 2021
Abstract: Multi-object tracking (MOT) aims at estimating bounding boxes and identities of objects in videos. Most methods obtain identities by associating detection boxes whose scores are higher than a threshold. The objects with low detection scores, e.g. occluded objects, are simply thrown away, which brings non-negligible true object missing and fragmented trajectories. To solve this problem, we present a simple, effective and generic association method, called BYTE, tracking BY associaTing Every detection box instead of only the high score ones. For the low score detection boxes, we utilize their similarities with tracklets to recover true objects and filter out the background detections. We apply BYTE to 9 different state-of-the-art trackers and achieve consistent improvement on IDF1 score ranging from 1 to 10 points. To put forwards the state-of-the-art performance of MOT, we design a simple and strong tracker, named ByteTrack. For the first time, we achieve 80.3 MOTA, 77.3 IDF1 and 63.1 HOTA on the test set of MOT17 with 30 FPS running speed on a single V100 GPU. The source code, pre-trained models with deploy versions and tutorials of applying to other trackers are released at this https URL.
66 tweets
Exploring the Limits of Large Scale Pre-training
Samira Abnar, Mostafa Dehghani, Behnam Neyshabur, Hanie Sedghi
Submitted to arXiv on: 5 October 2021
Abstract: Recent developments in large-scale machine learning suggest that by scaling up data, model size and training time properly, one might observe that improvements in pre-training would transfer favorably to most downstream tasks. In this work, we systematically study this phenomena and establish that, as we increase the upstream accuracy, the performance of downstream tasks saturates. In particular, we investigate more than 4800 experiments on Vision Transformers, MLP-Mixers and ResNets with number of parameters ranging from ten million to ten billion, trained on the largest scale of available image data (JFT, ImageNet21K) and evaluated on more than 20 downstream image recognition tasks. We propose a model for downstream performance that reflects the saturation phenomena and captures the nonlinear relationship in performance of upstream and downstream tasks. Delving deeper to understand the reasons that give rise to these phenomena, we show that the saturation behavior we observe is closely related to the way that representations evolve through the layers of the models. We showcase an even more extreme scenario where performance on upstream and downstream are at odds with each other. That is, to have a better downstream performance, we need to hurt upstream accuracy.
59 tweets
tags: arXiv

AUAI is supported by:








