
ΑΙhub.org
Interview with Chien Lu: analyzing text documents with sophisticated covariates

Chien Lu received a runner up award for best student paper at ACML 2021. In this interview, he tells us about the implications of this research, the methodology, and plans for future work.
What is the topic of the research in your paper?
Our paper is entitled “Cross-structural factor-topic model: document analysis with sophisticated covariates.” This paper proposes a novel topic model to analyze text documents with sophisticated covariates.
Could you tell us about the implications of your research and why it is an interesting area for study?
Text data are usually accompanied by various numerical covariates in many real-world situations. For example, a questionnaire for a survey may contain open-ended questions (text) and Likert scale questions (numerical covariates). Another example can be online game reviews, where each piece of review text is linked to the player’s profile. There are many variables in the player’s profile, e.g., how many games the player owns, how much time the play has spent on the game, etc. Those variables, again, can be considered as numerical covariates.
In data analysis, if we want to better capitalize on this kind of data, it is necessary to take both the text and numerical variables into account. Besides, it is essential to “let the data speak”, which means to learn interpretable representations from the data, both covariates and text. And we found that, although there have been quite a lot of different topic models that have been proposed, this kind of effort is still missing in topic models.
Could you explain your methodology?
The Cross-structural Factor-topic Model (CFTM) is proposed, which learns the structure from the text and the covariates. In brief, CFTM learns a set of “factors” from the covariates and a set of “topics” from the text. Besides, the interactions between the factors and topics are also modeled (e.g., how do factors affect the topic prevalence of a document? Or, how does a factor emphasize or downplay a specific term in a topic). The major novelty is incorporating the factorization structure into a topic model. Compared to treating each covariate individually, the factorization structure which captures the latent relationships between covariates can achieve better model interpretability and enhance predictive performance when handling high-dimensional data.
A set of tailored algorithms for CFTM, which leverages Gaussian Process Regression and parallel computing is developed. With the Gaussian Process Regression framework, not just a point estimate of parameters, but the full posterior distributions can be obtained, which is important when it comes to modeling the uncertainty. On the other hand, the parallel computation can strongly improve computational efficiency.
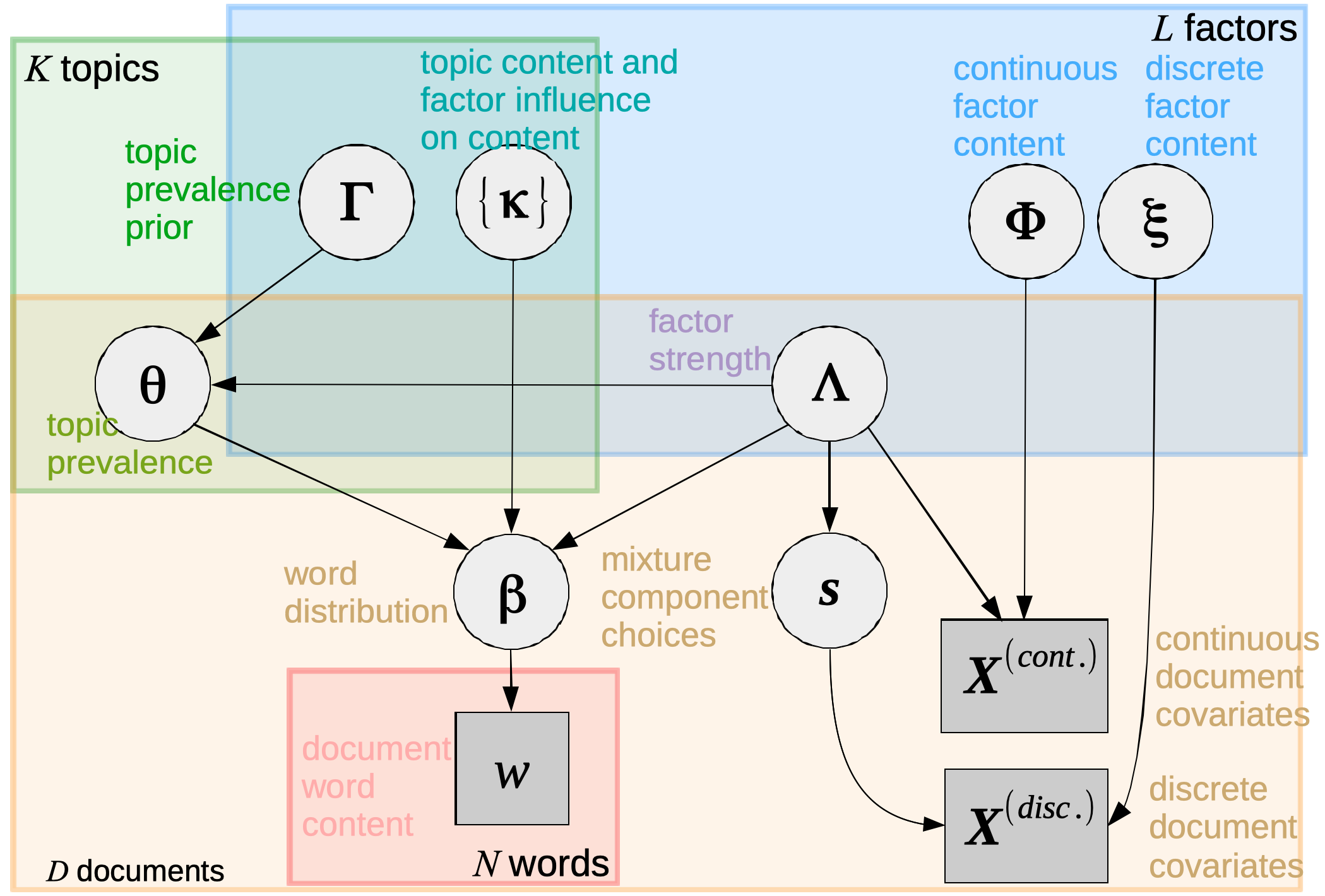 A plate representation graph, from Cross-structural factor-topic model: document analysis with sophisticated covariates.
A plate representation graph, from Cross-structural factor-topic model: document analysis with sophisticated covariates.
What were your main findings?
In our experiments, the CFTM can achieve better predictive performance than other state-of-the-art models. Moreover, it is suitable for pragmatic data analysis tasks. In the first case study focusing on a dataset related to a Finnish parliamentary election, CFTM discovers interpretable latent factors such as euro-sceptic, or pro-global, etc, that reflect different positions on the political spectrum. Another case study focuses on a collection of game reviews with corresponding player profiles. CFTM discovers different player types such as game-collector and entertainer, etc. CFTM can also outline how they influence the written content. For example, the euro-sceptic factor puts more emphasis on terms such as “consumption”, “victim”, etc, which can imply anxiety.
What further work are you planning in this area?
One direction is to promote CFTM to practical research projects. In this paper, we have demonstrated that our model can contribute to political science and game studies. I am looking forward to other possibilities/opportunities.
On the other hand, just like this work, I am interested in developing more text analytics tools with model interpretability, and I will continue my research on this route.

|
Chien Lu is a doctoral researcher at Tampere University in Finland, under the supervision of Dr Jaakko Peltonen and Dr Timo Nummenmaa. He is a member of CoE GameCult and SMiLE research group. His research interests focus on probabilistic representation learning and its applications in game studies. You can find his personal webpage here. |

AUAI is supported by:








