
ΑΙhub.org
RLiable: towards reliable evaluation and reporting in reinforcement learning
Rishabh Agarwal, Max Schwarzer, Pablo Samuel Castro, Aaron Courville and Marc G. Bellemare won an outstanding paper award at NeurIPS2021 for their paper Deep Reinforcement Learning at the Edge of the Statistical Precipice. In this blog post, Rishabh Agarwal and Pablo Samuel Castro explain this work.
By Rishabh Agarwal and Pablo Samuel Castro
Reinforcement learning (RL) is an area of machine learning that focuses on learning from experiences to solve decision making tasks. While the field of RL has made great progress, resulting in impressive empirical results on complex tasks, such as playing video games, flying stratospheric balloons and designing hardware chips, it is becoming increasingly apparent that the current standards for empirical evaluation might give a false sense of fast scientific progress while slowing it down.
To that end, in “Deep RL at the Edge of the Statistical Precipice”, given as an oral presentation at NeurIPS 2021, we discuss how statistical uncertainty of results needs to be considered, especially when using only a few training runs, in order for evaluation in deep RL to be reliable. Specifically, the predominant practice of reporting point estimates ignores this uncertainty and hinders reproducibility of results. Related to this, tables with per-task scores, as are commonly reported, can be overwhelming beyond a few tasks and often omit standard deviations. Furthermore, simple performance metrics like the mean can be dominated by a few outlier tasks, while the median score would remain unaffected even if up to half of the tasks had performance scores of zero. Thus, to increase the field’s confidence in reported results with a handful of runs, we propose various statistical tools, including stratified bootstrap confidence intervals, performance profiles, and better metrics, such as interquartile mean and probability of improvement. To help researchers incorporate these tools, we also release an easy-to-use Python library RLiable with a quickstart colab.
Statistical uncertainty in RL evaluation
Empirical research in RL relies on evaluating performance on a diverse suite of tasks, such as Atari 2600 video games, to assess progress. Published results on deep RL benchmarks typically compare point estimates of the mean and median scores aggregated across tasks. These scores are typically relative to some defined baseline and optimal performance (e.g., random agent and “average” human performance on Atari games, respectively) so as to make scores comparable across different tasks.
In most RL experiments, there is randomness in the scores obtained from different training runs, so reporting only point estimates does not reveal whether similar results would be obtained with new independent runs. A small number of training runs, coupled with the high variability in performance of deep RL algorithms, often leads to large statistical uncertainty in such point estimates.
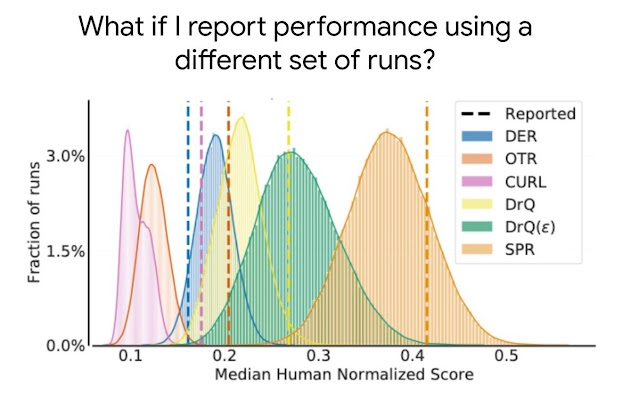 The distribution of median human normalized scores on the Atari 100k benchmark, which contains 26 games, for five recently published algorithms, DER, OTR, CURL, two variants of DrQ, and SPR. The reported point estimates of median scores based on a few runs in publications, as shown by dashed lines, do not provide information about the variability in median scores and typically overestimate (e.g., CURL, SPR, DrQ) or underestimate (e.g., DER) the expected median, which can result in erroneous conclusions.
The distribution of median human normalized scores on the Atari 100k benchmark, which contains 26 games, for five recently published algorithms, DER, OTR, CURL, two variants of DrQ, and SPR. The reported point estimates of median scores based on a few runs in publications, as shown by dashed lines, do not provide information about the variability in median scores and typically overestimate (e.g., CURL, SPR, DrQ) or underestimate (e.g., DER) the expected median, which can result in erroneous conclusions.
As benchmarks become increasingly more complex, evaluating more than a few runs will be increasingly demanding due to the increased compute and data needed to solve such tasks. For example, five runs on 50 Atari games for 200 million frames takes 1000+ GPU days. Thus, evaluating more runs is not a feasible solution for reducing statistical uncertainty on computationally demanding benchmarks. While prior work has recommended statistical significance tests as a solution, such tests are dichotomous in nature (either “significant” or “not significant”), so they often lack the granularity needed to yield meaningful insights and are widely misinterpreted.
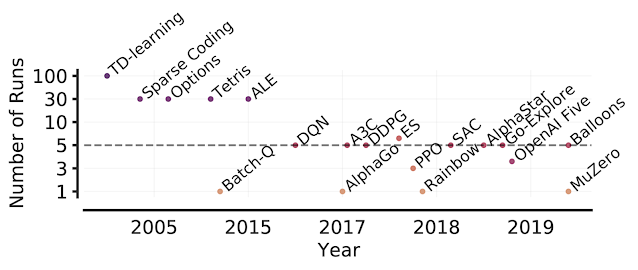 Number of runs in RL papers over the years. Beginning with the Arcade Learning Environment (ALE), the shift toward computationally-demanding benchmarks has led to the practice of evaluating only a handful of runs per task, increasing the statistical uncertainty in point estimates.
Number of runs in RL papers over the years. Beginning with the Arcade Learning Environment (ALE), the shift toward computationally-demanding benchmarks has led to the practice of evaluating only a handful of runs per task, increasing the statistical uncertainty in point estimates.
Tools for reliable evaluation
Any aggregate metric based on a finite number of runs is a random variable, so to take this into account, we advocate for reporting stratified bootstrap confidence intervals (CIs), which predict the likely values of aggregate metrics if the same experiment were repeated with different runs. These CIs allow us to understand the statistical uncertainty and reproducibility of results. Such CIs use the scores on combined runs across tasks. For example, evaluating 3 runs each on Atari 100k, which contains 26 tasks, results in 78 sample scores for uncertainty estimation.
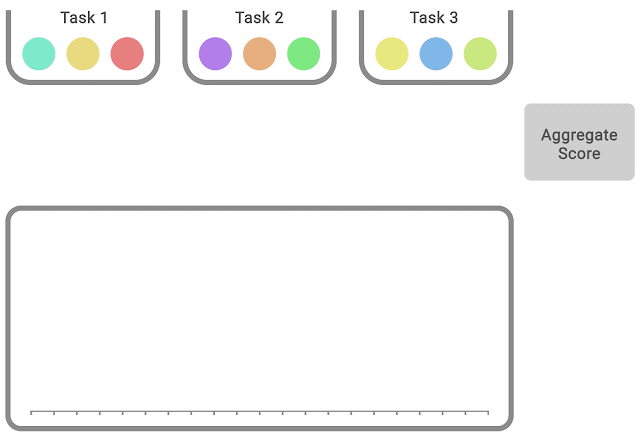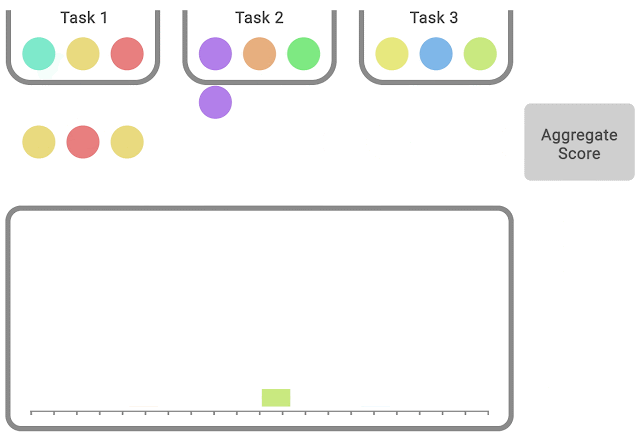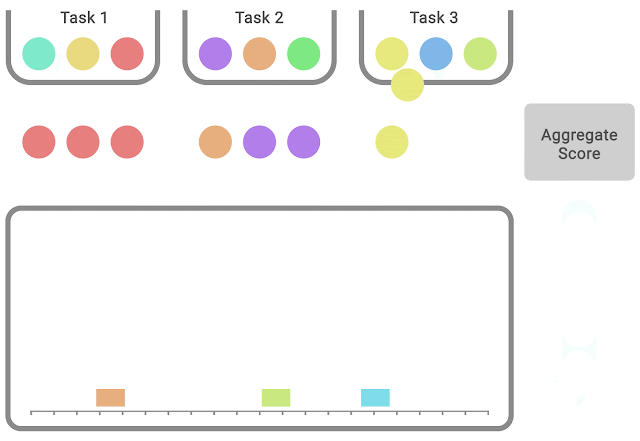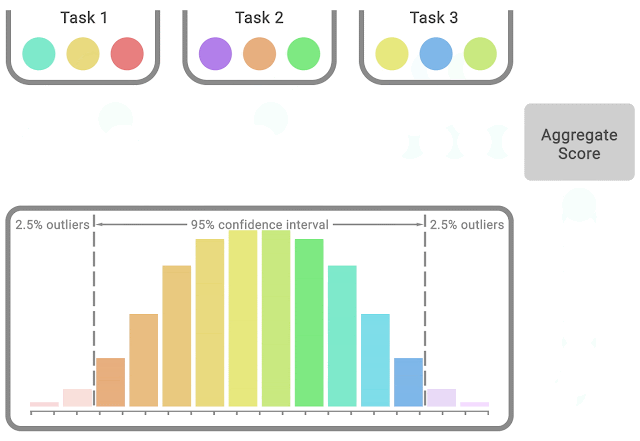 In each task, colored balls denote scores on different runs. To compute statified bootstrap CIs using the percentile method, bootstrap samples are created by randomly sampling scores with replacement proportionately from each task. Then, the distribution of aggregate scores on these samples is the bootstrapping distribution, whose spread around the center gives us the confidence interval.
In each task, colored balls denote scores on different runs. To compute statified bootstrap CIs using the percentile method, bootstrap samples are created by randomly sampling scores with replacement proportionately from each task. Then, the distribution of aggregate scores on these samples is the bootstrapping distribution, whose spread around the center gives us the confidence interval.
Most deep RL algorithms often perform better on some tasks and training runs, but aggregate performance metrics can conceal this variability, as shown below.
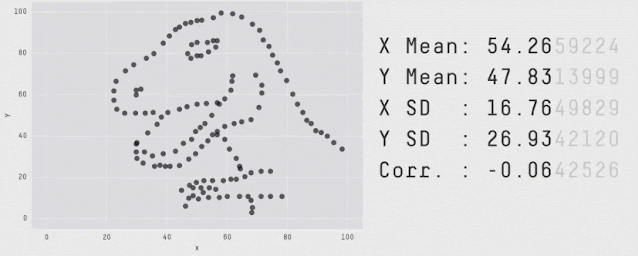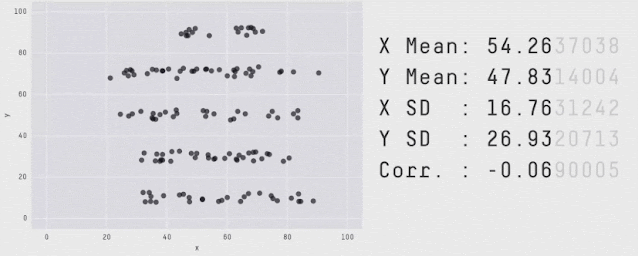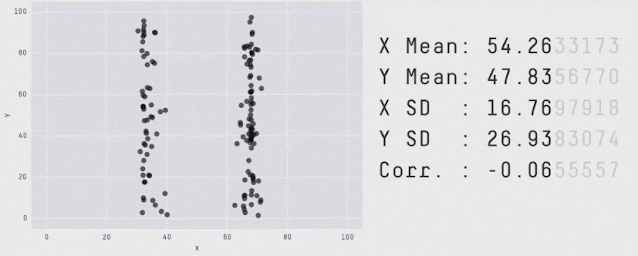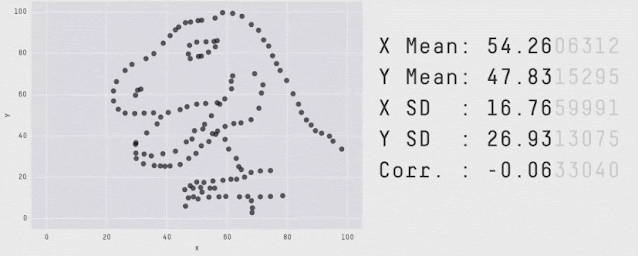 Data with varied appearance but identical aggregate statistics. Source: Same Stats, Different Graphs.
Data with varied appearance but identical aggregate statistics. Source: Same Stats, Different Graphs.
Instead, we recommend performance profiles, which are typically used for comparing solve times of optimization software. These profiles plot the score distribution across all runs and tasks with uncertainty estimates using stratified bootstrap confidence bands. These plots show the total runs across all tasks that obtain a score above a threshold (?) as a function of the threshold.
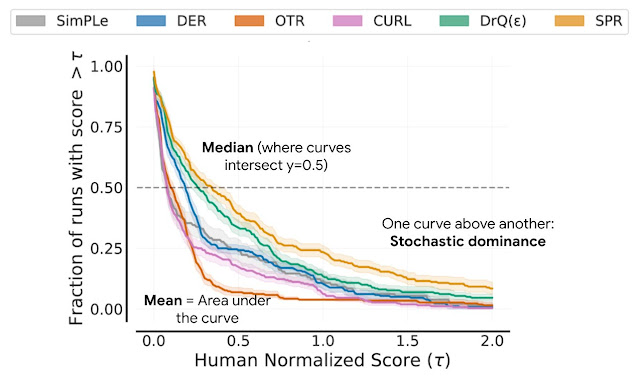 Performance profiles correspond to the empirical tail distribution of scores on runs combined across all tasks. Shaded regions show 95% stratified bootstrap confidence bands.
Performance profiles correspond to the empirical tail distribution of scores on runs combined across all tasks. Shaded regions show 95% stratified bootstrap confidence bands.
Such profiles allow for qualitative comparisons at a glance. For example, the curve for one algorithm above another means that one algorithm is better than the other. We can also read any score percentile, e.g., the profiles intersect y = 0.5 (dotted line above) at the median score. Furthermore, the area under the profile corresponds to the mean score.
While performance profiles are useful for qualitative comparisons, algorithms rarely outperform other algorithms on all tasks and thus their profiles often intersect, so finer quantitative comparisons require aggregate performance metrics. However, existing metrics have limitations: (1) a single high performing task may dominate the task mean score, while (2) the task median is unaffected by zero scores on nearly half of the tasks and requires a large number of training runs for small statistical uncertainty. To address the above limitations, we recommend two alternatives based on robust statistics: the interquartile mean (IQM) and the optimality gap, both of which can be read as areas under the performance profile, below.
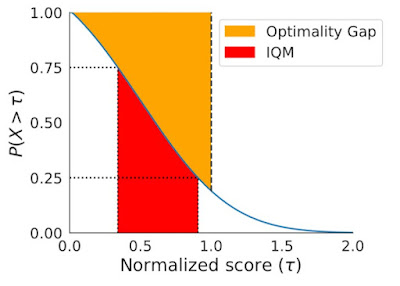 IQM (red) corresponds to the area under the performance profile, shown in blue, between the 25 and 75 percentile scores on the x-axis. Optimality gap (yellow) corresponds to the area between the profile and horizontal line at y = 1 (human performance), for scores less than 1.
IQM (red) corresponds to the area under the performance profile, shown in blue, between the 25 and 75 percentile scores on the x-axis. Optimality gap (yellow) corresponds to the area between the profile and horizontal line at y = 1 (human performance), for scores less than 1.
As an alternative to median and mean, IQM corresponds to the mean score of the middle 50% of the runs combined across all tasks. It is more robust to outliers than mean, a better indicator of overall performance than median, and results in smaller CIs, and so, requires fewer runs to claim improvements. Another alternative to mean, optimality gap measures how far an algorithm is from optimal performance.
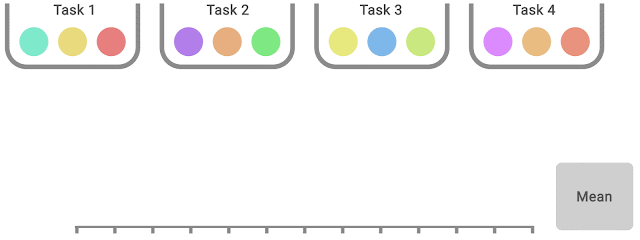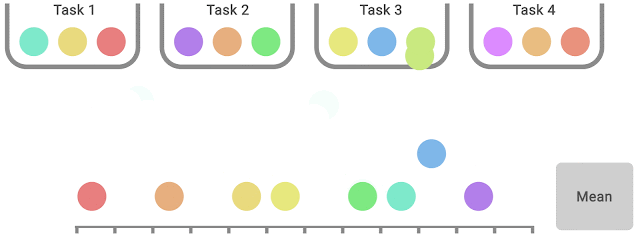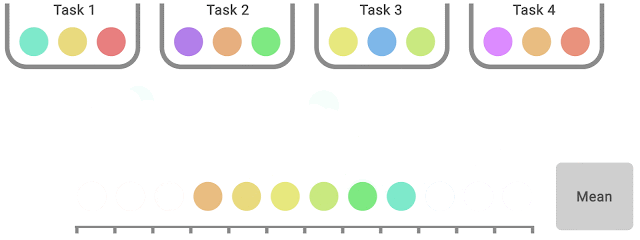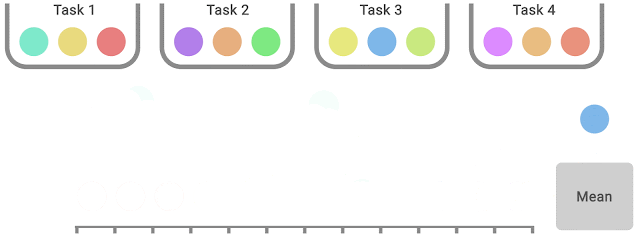 IQM discards the lowest 25% and highest 25% of the combined scores (colored balls) and computes the mean of the remaining 50% scores.
IQM discards the lowest 25% and highest 25% of the combined scores (colored balls) and computes the mean of the remaining 50% scores.
For directly comparing two algorithms, another metric to consider is the average probability of improvement, which describes how likely an improvement over baseline is, regardless of its size. This metric is computed using the Mann-Whitney U-statistic, averaged across tasks.
Re-evaluating evaluation
Using the above tools for evaluation, we revisit performance evaluations of existing algorithms on widely used RL benchmarks, revealing inconsistencies in prior evaluation. For example, in the Arcade Learning Environment (ALE), a widely recognized RL benchmark, the performance ranking of algorithms changes depending on the choice of aggregate metric. Since performance profiles capture the full picture, they often illustrate why such inconsistencies exist.
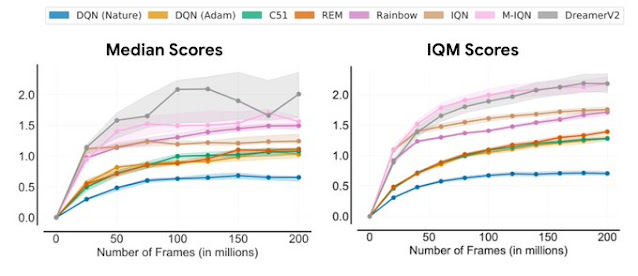 Median (left) and IQM (right) human normalized scores on the ALE as a function of the number of environment frames seen during training. IQM results in significantly smaller CIs than median scores.
Median (left) and IQM (right) human normalized scores on the ALE as a function of the number of environment frames seen during training. IQM results in significantly smaller CIs than median scores.
On DM Control, a popular continuous control benchmark, there are large overlaps in 95% CIs of mean normalized scores for most algorithms.
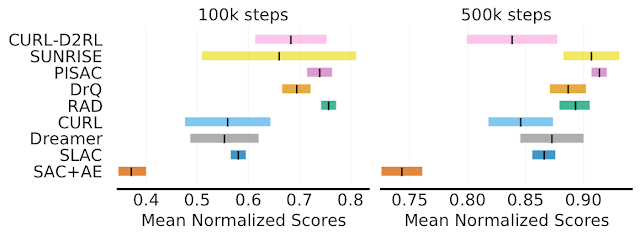 DM Control Suite results, averaged across six tasks, on the 100k and 500k step benchmark. Since scores are normalized using maximum performance, mean scores correspond to one minus the optimality gap. The ordering of the algorithms is based on their claimed relative performance — all algorithms except Dreamer claimed improvement over at least one algorithm placed below them. Shaded regions show 95% CIs.
DM Control Suite results, averaged across six tasks, on the 100k and 500k step benchmark. Since scores are normalized using maximum performance, mean scores correspond to one minus the optimality gap. The ordering of the algorithms is based on their claimed relative performance — all algorithms except Dreamer claimed improvement over at least one algorithm placed below them. Shaded regions show 95% CIs.
Finally, on Procgen, a benchmark for evaluating generalization in RL, the average probability of improvement shows that some claimed improvements are only 50-70% likely, suggesting that some reported improvements could be spurious.
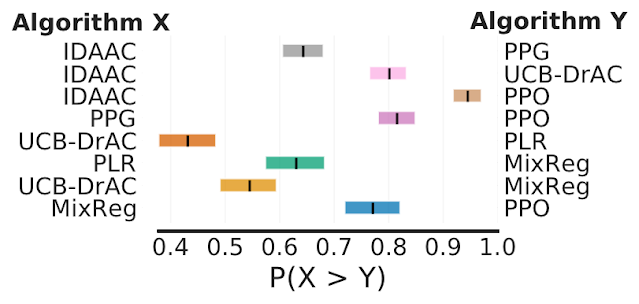 Each row shows the probability that the algorithm X on the left outperforms algorithm Y on the right, given that X was claimed to be better than Y. Shaded region denotes 95% stratified bootstrap CIs.
Each row shows the probability that the algorithm X on the left outperforms algorithm Y on the right, given that X was claimed to be better than Y. Shaded region denotes 95% stratified bootstrap CIs.
Conclusion
Our findings on widely-used deep RL benchmarks show that statistical issues can have a large influence on previously reported results. In this work, we take a fresh look at evaluation to improve the interpretation of reported results and standardize experimental reporting. We’d like to emphasize the importance of published papers providing results for all runs to allow for future statistical analyses. To build confidence in your results, please check out our open-source library RLiable and the quickstart colab.
Acknowledgments
This work was done in collaboration with Max Schwarzer, Aaron Courville and Marc G. Bellemare. We’d like to thank Tom Small for an animated figure used in this post. We are also grateful for feedback by several members of the Google Research, Brain Team and DeepMind.
This article was initially published on the GoogleAI blog, and appears here with the authors’ permission.
tags: NeurIPS, NeurIPS2021
AUAI is supported by:








