
ΑΙhub.org
Hot papers on arXiv from the past month: January 2022
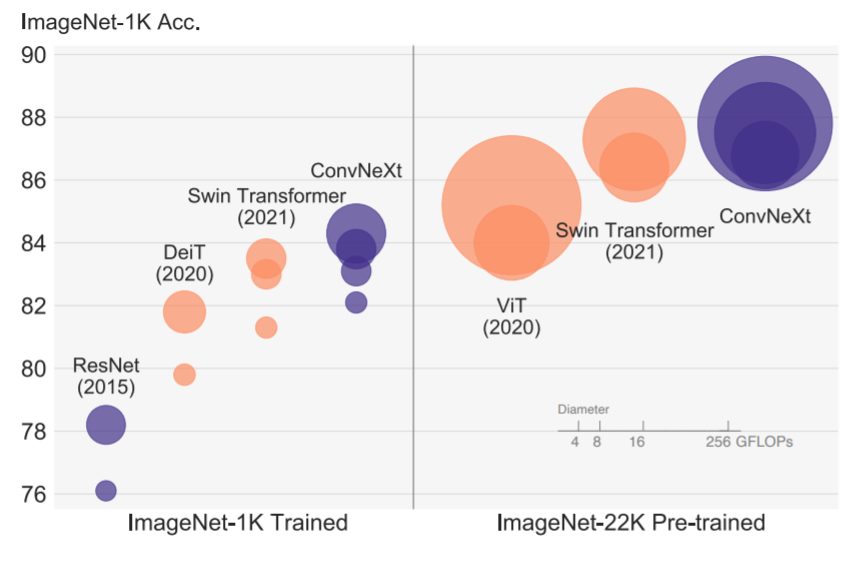
. ImageNet-1K classification results for • ConvNets and ◦ vision Transformers. From A ConvNet for the 2020s. Reproduced under a CC BY 4.0 license.
What’s hot on arXiv? Here are the most tweeted papers that were uploaded onto arXiv during January 2022.
Results are powered by Arxiv Sanity Preserver.
A ConvNet for the 2020s
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie
Submitted to arXiv on: 10 January 2022
Abstract: The “Roaring 20s” of visual recognition began with the introduction of Vision Transformers (ViTs), which quickly superseded ConvNets as the state-of-the-art image classification model. A vanilla ViT, on the other hand, faces difficulties when applied to general computer vision tasks such as object detection and semantic segmentation. It is the hierarchical Transformers (e.g., Swin Transformers) that reintroduced several ConvNet priors, making Transformers practically viable as a generic vision backbone and demonstrating remarkable performance on a wide variety of vision tasks. However, the effectiveness of such hybrid approaches is still largely credited to the intrinsic superiority of Transformers, rather than the inherent inductive biases of convolutions. In this work, we reexamine the design spaces and test the limits of what a pure ConvNet can achieve. We gradually “modernize” a standard ResNet toward the design of a vision Transformer, and discover several key components that contribute to the performance difference along the way. The outcome of this exploration is a family of pure ConvNet models dubbed ConvNeXt. Constructed entirely from standard ConvNet modules, ConvNeXts compete favorably with Transformers in terms of accuracy and scalability, achieving 87.8% ImageNet top-1 accuracy and outperforming Swin Transformers on COCO detection and ADE20K segmentation, while maintaining the simplicity and efficiency of standard ConvNets.
195 tweets
Deep Symbolic Regression for Recurrent Sequences
Stéphane d’Ascoli, Pierre-Alexandre Kamienny, Guillaume Lample, François Charton
Submitted to arXiv on: 12 January 2022
Abstract: Symbolic regression, i.e. predicting a function from the observation of its values, is well-known to be a challenging task. In this paper, we train Transformers to infer the function or recurrence relation underlying sequences of integers or floats, a typical task in human IQ tests which has hardly been tackled in the machine learning literature. We evaluate our integer model on a subset of OEIS sequences, and show that it outperforms built-in Mathematica functions for recurrence prediction. We also demonstrate that our float model is able to yield informative approximations of out-of-vocabulary functions and constants, e.g. bessel0(x)≈(sin(x)+cos(x))/√πx and 1.644934≈π2/6. An interactive demonstration of our models is provided at this https URL.
185 tweets
LaMDA: Language Models for Dialog Applications
Romal Thoppilan, Daniel De Freitas, Jamie Hall, Noam Shazeer, Apoorv Kulshreshtha, Heng-Tze Cheng, Alicia Jin, Taylor Bos, Leslie Baker, Yu Du, YaGuang Li, Hongrae Lee, Huaixiu Steven Zheng, Amin Ghafouri, Marcelo Menegali, Yanping Huang, Maxim Krikun, Dmitry Lepikhin, James Qin, Dehao Chen, Yuanzhong Xu, Zhifeng Chen, Adam Roberts, Maarten Bosma, Yanqi Zhou, Chung-Ching Chang, Igor Krivokon, Will Rusch, Marc Pickett, Kathleen Meier-Hellstern, Meredith Ringel Morris, Tulsee Doshi, Renelito Delos Santos, Toju Duke, Johnny Soraker, Ben Zevenbergen, Vinodkumar Prabhakaran, Mark Diaz, Ben Hutchinson, Kristen Olson, Alejandra Molina, Erin Hoffman-John, Josh Lee, Lora Aroyo, Ravi Rajakumar, Alena Butryna, Matthew Lamm, Viktoriya Kuzmina, Joe Fenton, Aaron Cohen, Rachel Bernstein, Ray Kurzweil, Blaise Aguera-Arcas, Claire Cui, Marian Croak, Ed Chi, Quoc Le
Submitted to arXiv on: 20 January 2022
Abstract: We present LaMDA: Language Models for Dialog Applications. LaMDA is a family of Transformer-based neural language models specialized for dialog, which have up to 137B parameters and are pre-trained on 1.56T words of public dialog data and web text. While model scaling alone can improve quality, it shows less improvements on safety and factual grounding. We demonstrate that fine-tuning with annotated data and enabling the model to consult external knowledge sources can lead to significant improvements towards the two key challenges of safety and factual grounding. The first challenge, safety, involves ensuring that the model’s responses are consistent with a set of human values, such as preventing harmful suggestions and unfair bias. We quantify safety using a metric based on an illustrative set of human values, and we find that filtering candidate responses using a LaMDA classifier fine-tuned with a small amount of crowdworker-annotated data offers a promising approach to improving model safety. The second challenge, factual grounding, involves enabling the model to consult external knowledge sources, such as an information retrieval system, a language translator, and a calculator. We quantify factuality using a groundedness metric, and we find that our approach enables the model to generate responses grounded in known sources, rather than responses that merely sound plausible. Finally, we explore the use of LaMDA in the domains of education and content recommendations, and analyze their helpfulness and role consistency.
94 tweets
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, Vedant Misra
Submitted to arXiv on: 6 January 2022
Abstract: In this paper we propose to study generalization of neural networks on small algorithmically generated datasets. In this setting, questions about data efficiency, memorization, generalization, and speed of learning can be studied in great detail. In some situations we show that neural networks learn through a process of “grokking” a pattern in the data, improving generalization performance from random chance level to perfect generalization, and that this improvement in generalization can happen well past the point of overfitting. We also study generalization as a function of dataset size and find that smaller datasets require increasing amounts of optimization for generalization. We argue that these datasets provide a fertile ground for studying a poorly understood aspect of deep learning: generalization of overparametrized neural networks beyond memorization of the finite training dataset.
82 tweets
NeROIC: Neural Rendering of Objects from Online Image Collections
Zhengfei Kuang, Kyle Olszewski, Menglei Chai, Zeng Huang, Panos Achlioptas, Sergey Tulyakov
Submitted to arXiv on: 7 January 2022
Abstract: We present a novel method to acquire object representations from online image collections, capturing high-quality geometry and material properties of arbitrary objects from photographs with varying cameras, illumination, and backgrounds. This enables various object-centric rendering applications such as novel-view synthesis, relighting, and harmonized background composition from challenging in-the-wild input. Using a multi-stage approach extending neural radiance fields, we first infer the surface geometry and refine the coarsely estimated initial camera parameters, while leveraging coarse foreground object masks to improve the training efficiency and geometry quality. We also introduce a robust normal estimation technique which eliminates the effect of geometric noise while retaining crucial details. Lastly, we extract surface material properties and ambient illumination, represented in spherical harmonics with extensions that handle transient elements, e.g. sharp shadows. The union of these components results in a highly modular and efficient object acquisition framework. Extensive evaluations and comparisons demonstrate the advantages of our approach in capturing high-quality geometry and appearance properties useful for rendering applications.
64 tweets
In Defense of the Unitary Scalarization for Deep Multi-Task Learning
Vitaly Kurin, Alessandro De Palma, Ilya Kostrikov, Shimon Whiteson, M. Pawan Kumar
Submitted to arXiv on: 11 January 2022
Abstract: Recent multi-task learning research argues against unitary scalarization, where training simply minimizes the sum of the task losses. Several ad-hoc multi-task optimization algorithms have instead been proposed, inspired by various hypotheses about what makes multi-task settings difficult. The majority of these optimizers require per-task gradients, and introduce significant memory, runtime, and implementation overhead. We present a theoretical analysis suggesting that many specialized multi-task optimizers can be interpreted as forms of regularization. Moreover, we show that, when coupled with standard regularization and stabilization techniques from single-task learning, unitary scalarization matches or improves upon the performance of complex multi-task optimizers in both supervised and reinforcement learning settings. We believe our results call for a critical reevaluation of recent research in the area.
54 tweets
RePaint: Inpainting using Denoising Diffusion Probabilistic Models
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, Luc Van Gool
Submitted to arXiv on: 24 January 2022
Abstract: Free-form inpainting is the task of adding new content to an image in the regions specified by an arbitrary binary mask. Most existing approaches train for a certain distribution of masks, which limits their generalization capabilities to unseen mask types. Furthermore, training with pixel-wise and perceptual losses often leads to simple textural extensions towards the missing areas instead of semantically meaningful generation. In this work, we propose RePaint: A Denoising Diffusion Probabilistic Model (DDPM) based inpainting approach that is applicable to even extreme masks. We employ a pretrained unconditional DDPM as the generative prior. To condition the generation process, we only alter the reverse diffusion iterations by sampling the unmasked regions using the given image information. Since this technique does not modify or condition the original DDPM network itself, the model produces high-quality and diverse output images for any inpainting form. We validate our method for both faces and general-purpose image inpainting using standard and extreme masks. RePaint outperforms state-of-the-art Autoregressive, and GAN approaches for at least five out of six mask distributions. Github Repository: this http URL.
50 tweets
From data to functa: Your data point is a function and you should treat it like one
Emilien Dupont, Hyunjik Kim, S. M. Ali Eslami, Danilo Rezende, Dan Rosenbaum
Submitted to arXiv on: 28 January 2022
Abstract: It is common practice in deep learning to represent a measurement of the world on a discrete grid, e.g. a 2D grid of pixels. However, the underlying signal represented by these measurements is often continuous, e.g. the scene depicted in an image. A powerful continuous alternative is then to represent these measurements using an implicit neural representation, a neural function trained to output the appropriate measurement value for any input spatial location. In this paper, we take this idea to its next level: what would it take to perform deep learning on these functions instead, treating them as data? In this context we refer to the data as functa, and propose a framework for deep learning on functa. This view presents a number of challenges around efficient conversion from data to functa, compact representation of functa, and effectively solving downstream tasks on functa. We outline a recipe to overcome these challenges and apply it to a wide range of data modalities including images, 3D shapes, neural radiance fields (NeRF) and data on manifolds. We demonstrate that this approach has various compelling properties across data modalities, in particular on the canonical tasks of generative modeling, data imputation, novel view synthesis and classification.
49 tweets
FIGARO: Generating Symbolic Music with Fine-Grained Artistic Control
Dimitri von Rütte, Luca Biggio, Yannic Kilcher, Thomas Hoffman
Submitted to arXiv on: 26 January 2022
Abstract: Generating music with deep neural networks has been an area of active research in recent years. While the quality of generated samples has been steadily increasing, most methods are only able to exert minimal control over the generated sequence, if any. We propose the self-supervised \emph{description-to-sequence} task, which allows for fine-grained controllable generation on a global level by extracting high-level features about the target sequence and learning the conditional distribution of sequences given the corresponding high-level description in a sequence-to-sequence modelling setup. We train FIGARO (FIne-grained music Generation via Attention-based, RObust control) by applying description-to-sequence modelling to symbolic music. By combining learned high level features with domain knowledge, which acts as a strong inductive bias, the model achieves state-of-the-art results in controllable symbolic music generation and generalizes well beyond the training distribution.
40 tweets
tags: arXiv

AUAI is supported by:








