
ΑΙhub.org
The unsupervised reinforcement learning benchmark
By Misha Laskin and Denis Yarats
The shortcomings of supervised RL
Reinforcement Learning (RL) is a powerful paradigm for solving many problems of interest in AI, such as controlling autonomous vehicles, digital assistants, and resource allocation to name a few. We’ve seen over the last five years that, when provided with an extrinsic reward function, RL agents can master very complex tasks like playing Go, Starcraft, and dextrous robotic manipulation. While large-scale RL agents can achieve stunning results, even the best RL agents today are narrow. Most RL algorithms today can only solve the single task they were trained on and do not exhibit cross-task or cross-domain generalization capabilities.
A side-effect of the narrowness of today’s RL systems is that today’s RL agents are also very data inefficient. If we were to train AlphaGo-like agents on many tasks each agent would likely require billions of training steps because today’s RL agents don’t have the capabilities to reuse prior knowledge to solve new tasks more efficiently. RL as we know it is supervised – agents overfit to a specific extrinsic reward which limits their ability to generalize.

Unsupervised RL as a path forward
To date, the most promising path toward generalist AI systems in language and vision has been through unsupervised pre-training. Masked casual and bi-directional transformers have emerged as scalable methods for pre-training language models that have shown unprecedented generalization capabilities. Siamese architectures and more recently masked auto-encoders have also become state-of-the-art methods for achieving fast downstream task adaptation in vision.
If we believe that pre-training is a powerful approach towards developing generalist AI agents, then it is natural to ask whether there exist self-supervised objectives that would allow us to pre-train RL agents. Unlike vision and language models which act on static data, RL algorithms actively influence their own data distribution. Like in vision and language, representation learning is an important aspect for RL as well but the unsupervised problem that is unique to RL is how agents can themselves generate interesting and diverse data trough self-supervised objectives. This is the unsupervised RL problem – how do we learn useful behaviors without supervision and then adapt them to solve downstream tasks quickly?
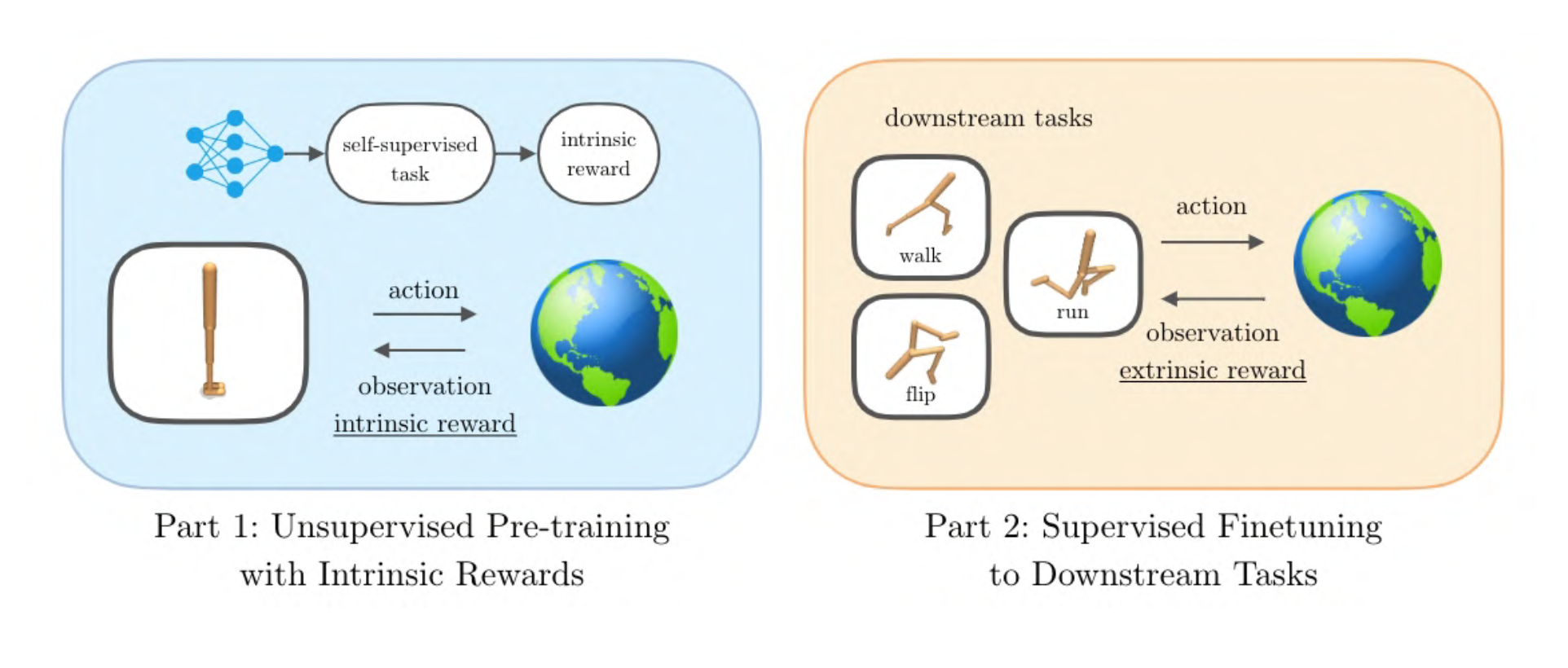
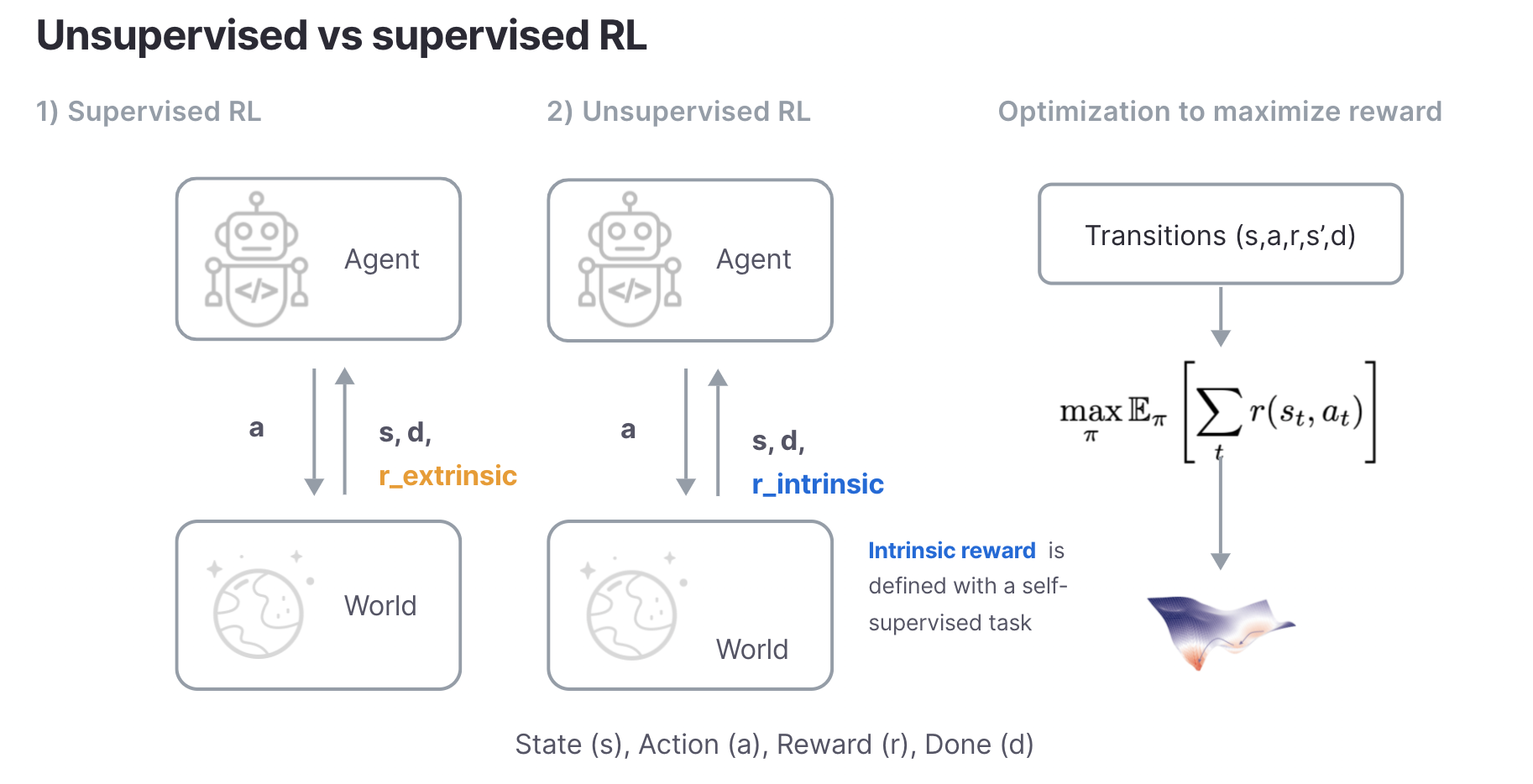
The unsupervised RL framework
Unsupervised RL is very similar to supervised RL. Both assume that the underlying environment is described by a Markov Decision Process (MDP) or a Partially Observed MDP, and both aim to maximize rewards. The main difference is that supervised RL assumes that supervision is provided by the environment through an extrinsic reward while unsupervised RL defines an intrinsic reward through a self-supervised task. Like supervision in NLP and vision, supervised rewards are either engineered or provided as labels by human operators which are hard to scale and limit the generalization of RL algorithms to specific tasks.
At the Robot Learning Lab (RLL), we’ve been taking steps toward making unsupervised RL a plausible approach toward developing RL agents capable of generalization. To this end, we developed and released a benchmark for unsupervised RL with open-sourced PyTorch code for 8 leading or popular baselines.
The unsupervised reinforcement learning benchmark (URLB)
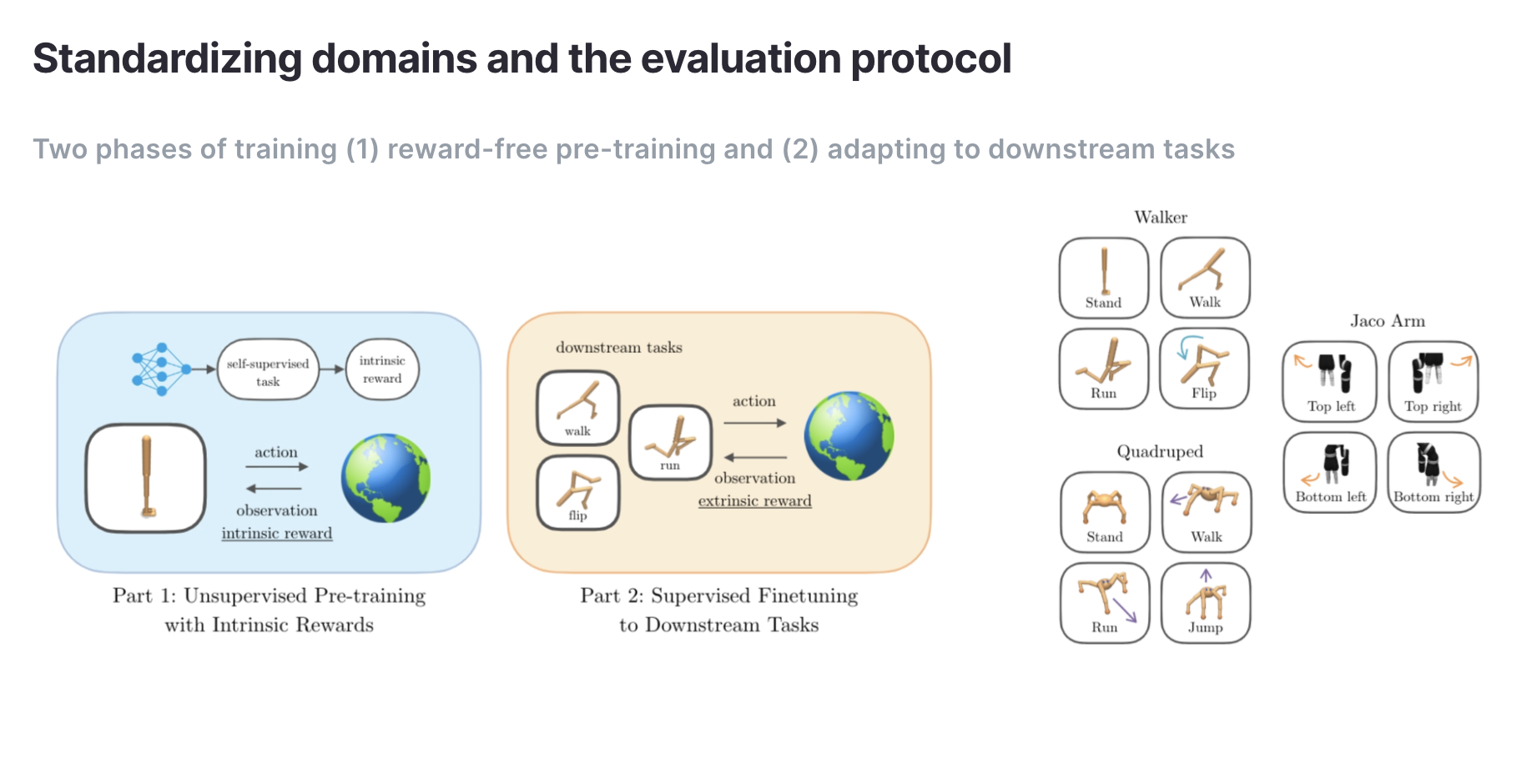
While a variety of unsupervised RL algorithms have been proposed over the last few years, it has been impossible to compare them fairly due to differences in evaluation, environments, and optimization. For this reason, we built URLB which provides standardized evaluation procedures, domains, downstream tasks, and optimization for unsupervised RL algorithms
URLB splits training into two phases – a long unsupervised pre-training phase followed by a short supervised fine-tuning phase. The initial release includes three domains with four tasks each for a total of twelve downstream tasks for evaluation.
Most unsupervised RL algorithms known to date can be classified into three categories – knowledge-based, data-based, and competence-based. Knowledge-based methods maximize the prediction error or uncertainty of a predictive model (e.g. Curiosity, Disagreement, RND), data-based methods maximize the diversity of observed data (e.g. APT, ProtoRL), competence-based methods maximize the mutual information between states and some latent vector often referred to as the “skill” or “task” vector (e.g. DIAYN, SMM, APS).
Previously these algorithms were implemented using different optimization algorithms (Rainbow DQN, DDPG, PPO, SAC, etc). As a result, unsupervised RL algorithms have been hard to compare. In our implementations we standardize the optimization algorithm such that the only difference between various baselines is the self-supervised objective.
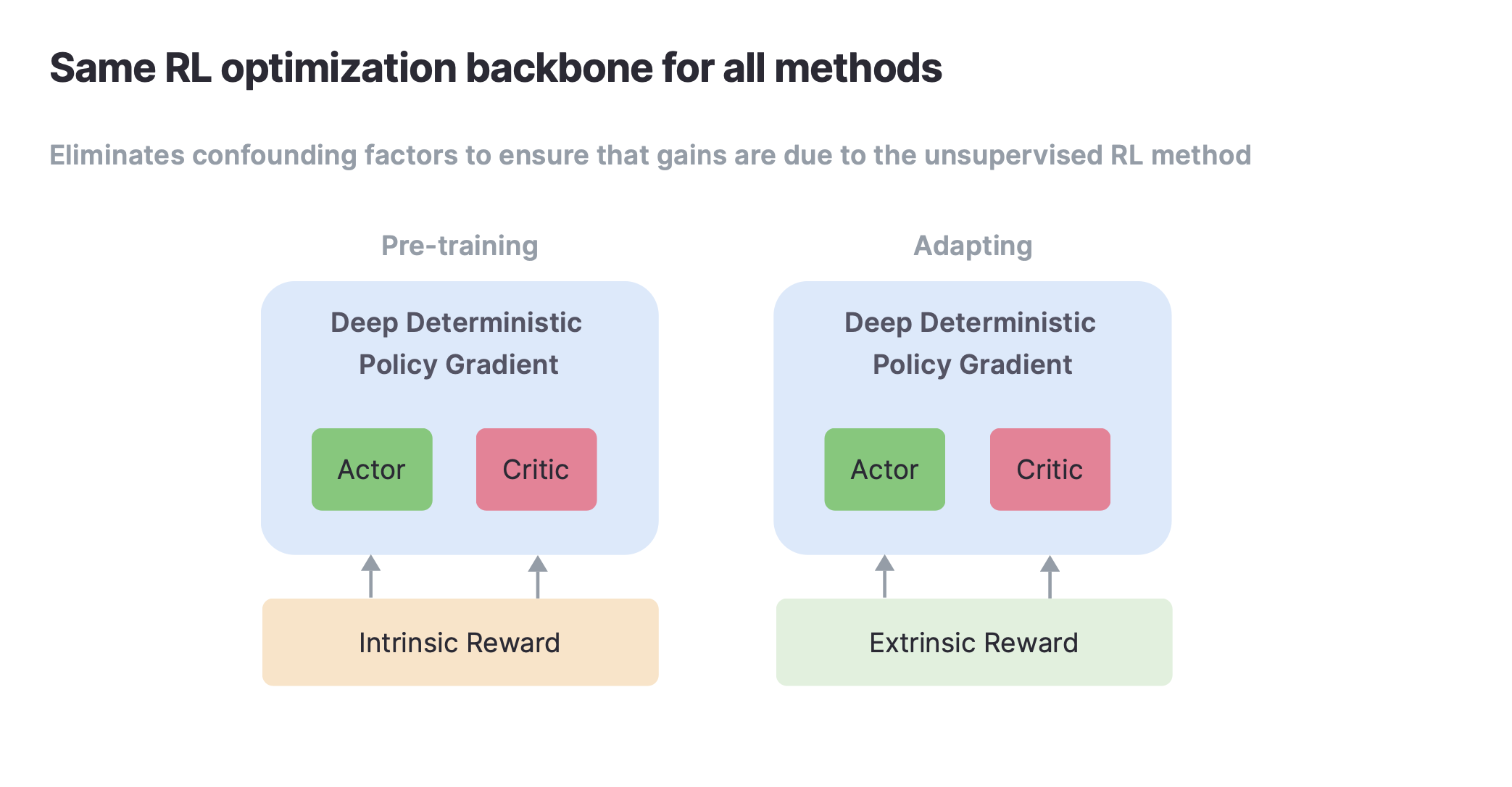
We implemented and released code for eight leading algorithms supporting both state and pixel-based observations on domains based on the DeepMind Control Suite.

By standardizing domains, evaluation, and optimization across all implemented baselines in URLB, the result is a first direct and fair comparison between these three different types of algorithms.
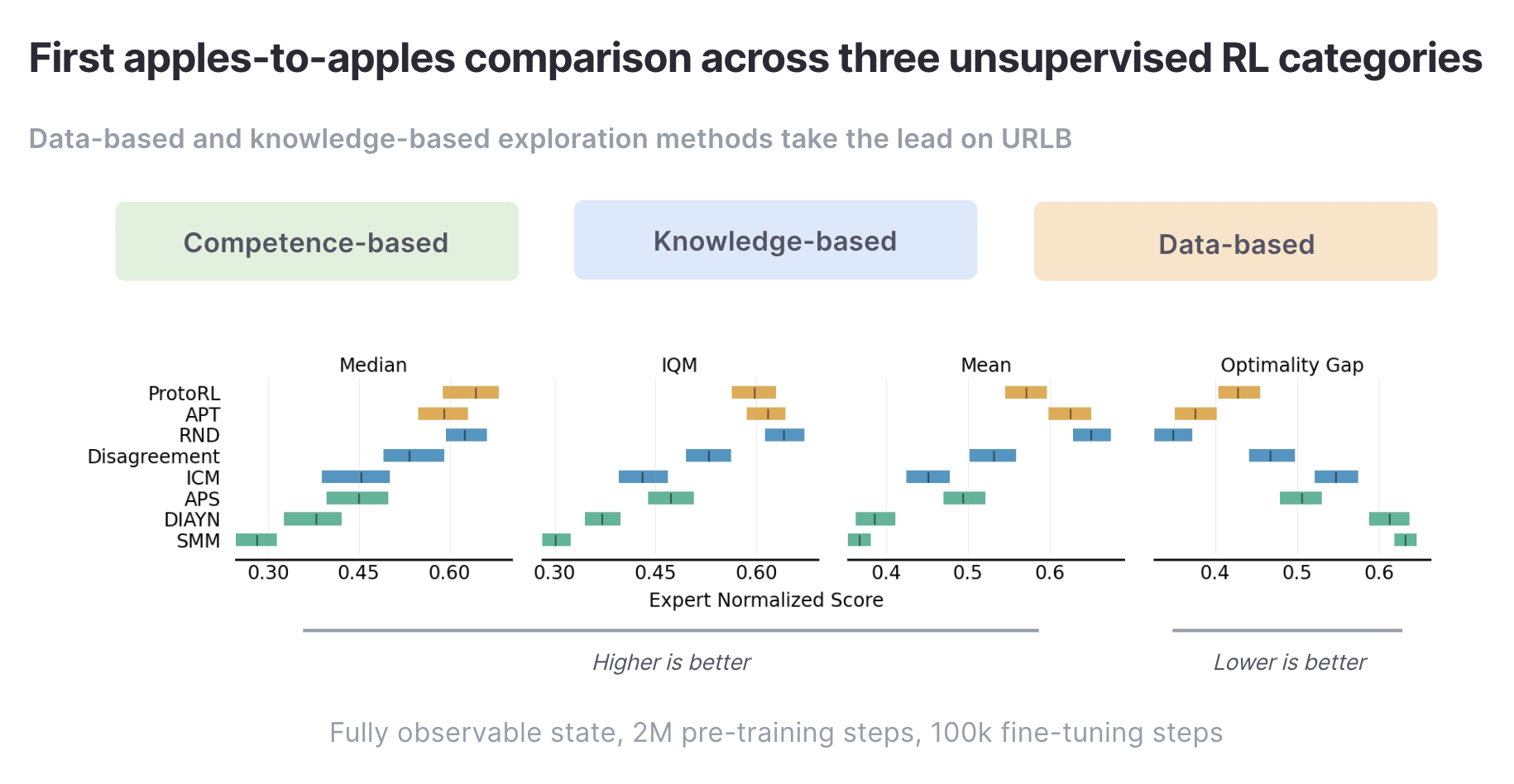
Above, we show aggregate statistics of fine-tuning runs across all 12 downstream tasks with 10 seeds each after pre-training on the target domain for 2M steps. We find that currently data-based methods (APT, ProtoRL) and RND are the leading approaches on URLB.
We’ve also identified a number of promising directions for future research based on benchmarking existing methods. For example, competence-based exploration as a whole underperforms data and knowledge-based exploration. Understanding why this is the case is an interesting line for further research. For additional insights and directions for future research in unsupervised RL, we refer the reader to the URLB paper.
Conclusion
Unsupervised RL is a promising path toward developing generalist RL agents. We’ve introduced a benchmark (URLB) for evaluating the performance of such agents. We’ve open-sourced code for both URLB and hope this enables other researchers to quickly prototype and evaluate unsupervised RL algorithms.
Links
Paper: URLB: Unsupervised Reinforcement Learning Benchmark
Michael Laskin*, Denis Yarats*, Hao Liu, Kimin Lee, Albert Zhan, Kevin Lu, Catherine Cang, Lerrel Pinto, Pieter Abbeel, NeurIPS, 2021, these authors contributed equally
Code: https://github.com/rll-research/url_benchmark
This article was initially published on the BAIR blog, and appears here with the authors’ permission.
tags: deep dive

AUAI is supported by:








