
ΑΙhub.org
The life of a dataset in machine learning research – interview with Bernard Koch
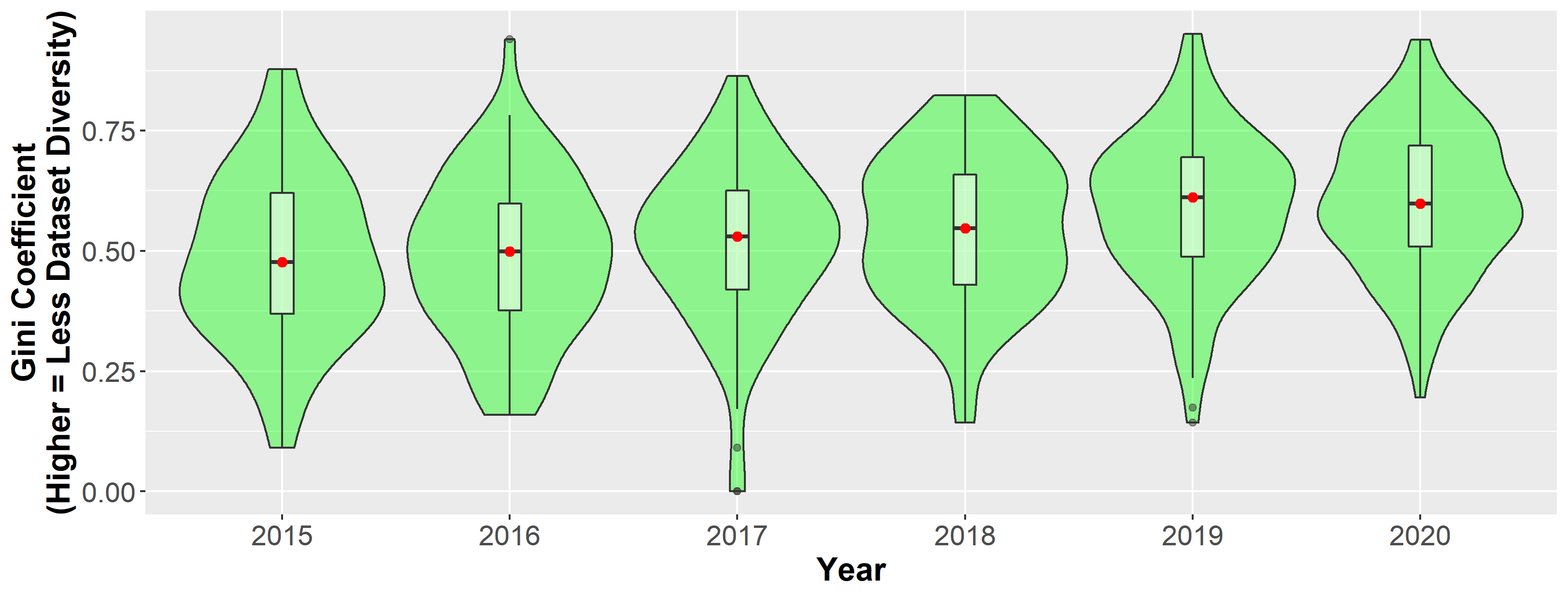 Gini plots showing distribution of the concentration on datasets across task communities over time. From Reduced, Reused and Recycled: The Life of a Dataset in Machine Learning Research.
Gini plots showing distribution of the concentration on datasets across task communities over time. From Reduced, Reused and Recycled: The Life of a Dataset in Machine Learning Research.
Bernard Koch, Emily Denton, Alex Hanna and Jacob Foster won a best paper award, for Reduced, Reused and Recycled: The Life of a Dataset in Machine Learning Research, in the datasets and benchmarks track at NeurIPS 2021. Here, Bernard tells us about the advantages and disadvantages of benchmarking, the findings of their paper, and plans for future work.
Perhaps you could start by giving an introduction to benchmarking, and why this is so important in machine learning research?
Machine learning is a rather unusual science, partly because it straddles the space between science and engineering. The main way that progress is evaluated is through state-of-the-art benchmarking. The scientific community agrees on a shared problem, they pick a dataset which they think is representative of the data that you might see when you try to solve that problem in the real world, then they compare their algorithms on a score for that dataset. If you achieve a state-of-the-art score that adds some credibility to your contribution.
What are some of the advantages and disadvantages of benchmarking?
Benchmarking has a lot of advantages. It provides a very clear measure of progress for many different types of people with varying degrees of involvement in research. There might be, depending on the task, say, five graduate students who can actually read a paper, look at the code, and evaluate the contribution in a very detailed way. But benchmarking makes it very clear what the contribution of that paper is, and where we are at as a community. It’s a great way to coordinate scientists around shared problems.
I also think part of machine learning’s rapid growth and success in the past ten years has been the ability to use benchmarking to relax other scientific institutions. The move towards posting stuff on arXiv, so you can get research out there, means there’s been a relaxation of peer-review in machine learning. Building theoretical consensus is also a slow process. Relying on benchmarking rather than peer review or theoretical significance to measure progress has allowed the pace of research in ML to move very quickly.
However, there are also a lot of disadvantages to benchmarking, and I’ll particularly focus on those that are dataset related. Firstly, there are concerns about overfitting. Supervised learning datasets are expensive to create, so our intuition before looking at the data was that a limited number might be used, risking “overfitting.” Overfitting, in general, is an over-utilization of datasets – it’s this idea that, if our data is not representative of the larger sample we expect to see in the real world, then our algorithm will generalize poorly. So, if you’re using the same dataset over and over for different problems, it’s going to be a very narrow slice of the real data distribution. In that sense you might have a distorted understanding of how much progress you’re actually making. This can waste time and money in both industry and academia.
Given the high cost of dataset creation, there’s also a concern around task communities borrowing datasets heavily from other tasks. There’s a possibility that the data that was generated for task A is not going to be representative data for task B. That’s another way that might have distorted the understanding of scientific progress.
There are also ethical concerns about dataset over-utilization. A classic case study in the ethics literature is about facial recognition algorithms, where datasets that are based on primarily white and Asian faces generalize very poorly to Black and brown people. When these are deployed in the context of a police department they mis-identify people at crime scenes or from CCTV footage because they are deployed disproportionately on a minority population. So, there are real risks for societal harm – it’s not just scientific problems, it’s potentially an ethical problem too.
So, this is the motivation for the paper. I want to stress that we’re not really assessing whether these types of problems are occurring, but we’re trying to gauge the extent of the risks posed by the way we use benchmarks.
Could you give us a brief overview of what the paper is about?
The paper is particularly about dataset usage in this benchmarking context. We looked at how datasets were used across different task communities in machine learning.
In particular, we studied three problems, or research questions:
- How many datasets are being used within task communities?
- How extensive is borrowing of datasets?
- Who is introducing the benchmark datasets?
Could you tell us about your findings for the first research question, concerning the number and concentration of datasets?
The first research question is looking at how concentrated task communities in machine learning are on specific benchmark datasets. To study this problem, we used the website called Papers with Code (PWC). It’s a systematic repository of papers, code and datasets in machine learning, run by Facebook AI Research. We were particularly interested in the datasets that were used for benchmarking, and we looked at approximately 130 task communities, and the tens of thousands of papers that are using those datasets within these task communities.
We found that a lot of task communities tend to concentrate on a few datasets, and that the level of concentration has been increasing since 2015. So, basically over time communities are using fewer and fewer benchmark datasets to do their research.
What were your findings for the second research question, with regards to the borrowing of datasets?
We were looking at borrowing and creation of datasets. To study this, we calculated two ratios.
The first (the creation ratio) looked at the raw datasets that are used: how many datasets were created specifically for a task versus how many were imported from a different task.
The second ratio looks at papers using those dataset. What percentage of papers are adopting datasets from outside of the task community versus using a homegrown dataset? In general, what we find there is that task communities are creating their own datasets but even though that’s the case, they prefer to import datasets from other tasks.
One finding that we found interesting is that the natural language processing community creates datasets at higher rates than the other communities we studied (e.g., computer vision) and adopts datasets from outside at a lower rate. Because none of the authors are NLP researchers, we were hesitant to interpret this finding but it’s an interesting direction for future research.
When it comes to the third research question, who is creating the datasets?
For the third research question we looked at what institutions were creating these datasets. We looked at the number of usages per dataset-creating institution. So, Stanford might create 20 datasets and we look at the usages of all those datasets and we sum them up to get the number of usages for Stanford. We looked at this across something like 400 institutions. What we found is there are about 12 institutions that have created datasets accounting for 50% or more of the dataset usage in machine learning.
What are the implications of your findings?
To recap, our findings in the first analysis show that there are very few datasets used. When you look at that in concert with the second research question, it’s not just that there are few datasets used, many datasets were actually made for a different task. There’s a risk of overutilization there because datasets might not actually be representative of the causal structure or true data distribution of the task that they’re being used for. There are many reasons why this might be the case (e.g., the expense of dataset creation). One not so obvious reason is social. Maybe you know that there’s a dataset that’s more appropriate for your task (or maybe you don’t know because nobody is using it), but in order for you to have legitimacy for your paper, you need to use something that’s widely recognized, even if it wasn’t originally created for this problem. So, there is kind of a social reinforcement going on, where the most widely used datasets probably have to get used.
The other thing that is very interesting is that there are very few institutions that have created these datasets. This is obviously highly correlated with the fact that there are very few datasets used. It’s not like each of these institutions are creating 20 datasets, they’re mostly getting their usages from one or two datasets. I think this is important because, to the extent that datasets are supposed to represent the types of data that we see for these problems, it’s like a very subtle way that elite institutions shape the research questions that get asked in the field.
There’s lots of reasons why there are few datasets in circulation and they are created by elite institutions. As I mentioned earlier, datasets are very expensive to create, particularly for supervised learning, and there are very few institutions (whether they’re corporate or academic) that even have the quantity of data needed by the community for the task. For example, if you’re doing a self-driving car problem, there aren’t that many places you can get self-driving car data.
I think the takeaway here is that we can’t say from our analyses that the risks of over-concentration on datasets that I listed at the beginning (i.e., distorting scientific progress, ethical harms, wasting money) are happening; that is not something this paper looks at. But the heavy use of borrowing, the high concentration on a few datasets, and the inequality of who is introducing these widely used datasets suggests that some of these things could be happening.
The finding about inequality in who is introducing datasets is especially interesting to me. The creation of widely-used research datasets primarily occurs at elite institutions concentrated in North America. Corporate institutions and American academic institutions are inclined to produce research on problems that are relevant to them. It’s not true of science that all possible research trajectories get pursued equally. People are interested in different problems and so it might be the case that if there were other institutions in other parts of the world that were creating the datasets that were used, different problems would get considered, or we might find out different things.
What would be your recommendations to improve the current situation that we have now with dataset benchmarking?
I’d like to stress that things like the NeurIPS dataset and benchmark track is a great intervention. I was talking to someone else at NeurIPS and they said that these types of venues already exist in natural language processing, so that’s great. I think in general the creation of high-status platforms to give visibility to high quality datasets, that’s something that is important, and I think should be lauded as a good future direction.
However, in our second analysis we see that people are creating datasets, but they’re just not getting used. To address that, I think we need investment in dataset creation. We’ve just got to put the money down. There need to be grants from governments and corporations. Creating really good datasets can cost millions of dollars, and so distributing those grants to non-elite institutions or non-American institutions is an important way to diversify both the datasets and the voices in ML research.
There are other kinds of interventions. The NeurIPS ethics checklist has been a great reform that forces authors to consider the social implications of their research. I don’t know if we need to have seven different checklists that authors need to talk about, but I think it would be helpful if authors could talk about why their dataset is appropriate for the task at hand.
Could you tell us a bit about what work you’re planning next?
This paper resonated strongly with people, and I think this is because most machine learning researchers already intuited it to be true. Our findings are not particularly revolutionary or even surprising, but I think there is some appeal of having quantitative evidence behind this idea.
I talked about some of the risks of over-utilizing the benchmarks and distorting scientific progress. One very obvious direction would be to try and look at whether those risks are actualized. Is there real distortion of scientific progress? There’s a little bit of work already in this area, whether over-utilizing benchmarks is actually a bad thing, but I think there’s room for more work in that space.

|
Bernard Koch is a computational social scientist and PhD candidate in Sociology at UCLA. His work focuses on organizational issues in scientific fields and their ethical and epistemic repercussions. Bernard is generally interested in how MLR differs from other sciences (e.g., by measuring progress through benchmarking, publishing through conferences, history of |
cyclical funding booms/busts), and how these distinctive features have shaped present challenges in AI. His non-ML research explores how psychologists have struggled with pseudoscience correlating race and IQ, comparing their cautious responses to the enthusiastic reception these publications receive by white supremacists online. Lastly, Bernard has methodological interests in Bayesian modeling and the intersections of deep learning, causal inference, and network science. His work has appeared in NeurIPS, WWW, Sociological Methodology, and Science, among other venues.
tags: NeurIPS, NeurIPS2021

AUAI is supported by:








