
ΑΙhub.org
Assessing generalization of SGD via disagreement
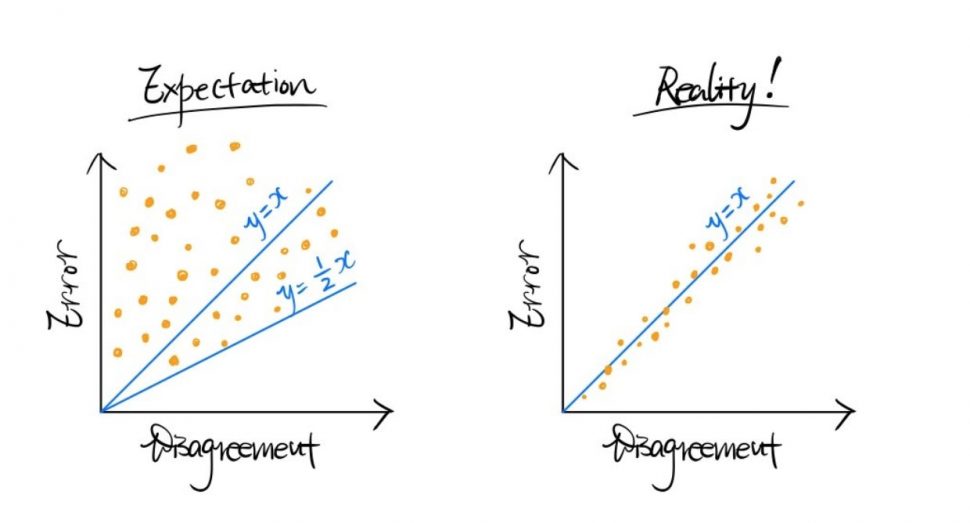
Imagine training a deep network twice with two different random seeds on the same data, and then measuring the rate at which they disagree on unlabeled test points. Naively, they can disagree with one another with probability anywhere between zero and twice the error rate. But surprisingly, in practice, we observe that the disagreement and test error of deep neural network are remarkably close to each other. The variable  refers to the average generalization error of the two models and the variable
refers to the average generalization error of the two models and the variable  refers to the disagreement of the two models.
refers to the disagreement of the two models.
By Yiding Jiang and Christina Baek
Estimating the generalization error of a model — how well the model performs on unseen data — is a fundamental component in any machine learning system. Generalization performance is traditionally estimated in a supervised manner, by dividing the labeled data into a training set and test set. However, high-quality labels are usually costly and, ideally, we would like to use all of them to train the model. On the other hand, in many real-world settings, a large amount of unlabeled data is readily available. How can we tap into the rich information in these unlabeled data and leverage them to assess a model’s performance without labels?
In this work (full paper), we demonstrate that a simple procedure can accurately estimate the generalization error with only unlabeled data. This result reveals a surprising fact about how neural networks make mistakes and their connection to calibration through an identity we call Generalization Disagreement Equality (GDE).
A surprising observation
Stochastic gradient descent (SGD) is perhaps the most popular optimization algorithm for deep neural networks. Due to the non-convex nature of the deep neural network’s optimization landscape, different runs of SGD will find different solutions. As a result, if the solutions are not perfect, they will disagree with each other on some of the unseen data. This disagreement can be harnessed to estimate generalization error without labels:
- Given a model, run SGD with the same hyperparameters but different random seeds on the training data to get two different solutions.
- Measure how often the networks’ predictions disagree on a new unlabeled test dataset.
We find that the disagreement rate is approximately equal to the average test error over the two models. Our observation builds on the phenomenon reported by Nakkiran and Bansal (2020) [1]: given two networks of the same architecture trained to zero training error on two independently drawn datasets of the same size, the disagreement rate of the pair on the test dataset is nearly equal to the average test error. Our observation generalizes prior work by showing that the same phenomenon holds for small changes in hyperparameters and, more importantly, the same dataset, which makes the procedure relevant for practical applications.
This procedure estimates the test error with unlabeled data, but the mechanisms behind it are not immediately obvious. Let  be the prediction of classifier and be the true label. By the triangle inequality, the disagreement rate can be anywhere between 0 and 2 times the test error:
be the prediction of classifier and be the true label. By the triangle inequality, the disagreement rate can be anywhere between 0 and 2 times the test error: ![0 \leq \mathbb{E}[h(x) \ne h'(x)] \leq \mathbb{E}[h(x) \ne y] + \mathbb{E}[h'(x) \ne y]](https://aihub.org/wp-content/ql-cache/quicklatex.com-3f8db590ca5aed56b83fe3e83f3c0bfa_l3.png "Rendered by QuickLaTeX.com") . Given that the models observe the same data, we may expect the models to extract similar knowledge from the data and consequently make similar errors, which would make the disagreement rate lower than the test error. Yet, we find that in practice, the disagreement rate approximates the test error without any proportionality constant. Why is this the case?
. Given that the models observe the same data, we may expect the models to extract similar knowledge from the data and consequently make similar errors, which would make the disagreement rate lower than the test error. Yet, we find that in practice, the disagreement rate approximates the test error without any proportionality constant. Why is this the case?
The final parameters found by SGD depend on many sources of randomness: 1) random initialization, 2) random ordering of a fixed training dataset, and/or 3) random sampling of training data. To understand this phenomenon, we analyze what kind of randomness is responsible for this peculiar property. It is possible to have other sources of randomness, such as dropout, which are not studied in this work.
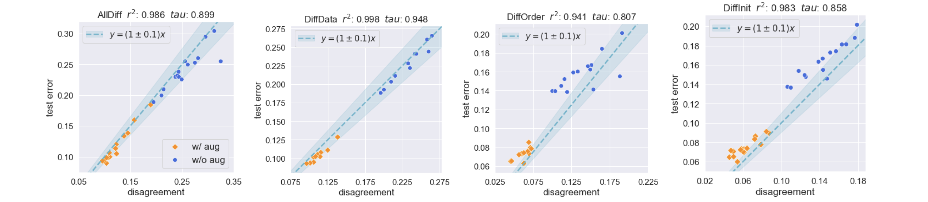
We study the phenomenon by observing how the behavior of disagreement changes when the different sources of randomness are isolated. For example, when examining the effect of different initializations we fix the dataset and the order in which the dataset is presented to the model and only change the random initialization. We observe that across different types of randomness, disagreement remains consistently close to the test error. This approach is particularly useful because we can use the same training data to train the two copies of the model. In addition, we empirically observe the phenomenon across a wide range of model architectures (ResNet, VGG, and fully-connected networks) and several popular image recognition benchmarks (MNIST, SVHN, Cifar10, and Cifar100).
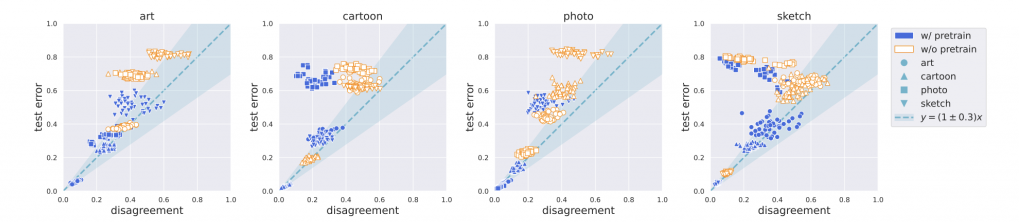
Furthermore, estimating generalization error is especially important when the test distribution is different from the training distribution. On that note, we see some promising observations in the PACS data [2]. This dataset consists of 4 different environments (Photo, Art, Cartoon, Sketch) of different objects. For each environment, we trained two ResNet18 models on that environment with different initialization and order of the data and measured their disagreement rate on the remaining environments. We observe that similar phenomena hold across many (but not all) pairs of environments, suggesting that the technique might be adaptable for estimating generalization error under distribution shift.
Generalization-Disagreement Equality
We will now theoretically investigate the sufficient condition under which the disagreement rate equals generalization error.
In the deep learning literature, it is well-known that ensembles of SGD-trained deep networks are well-calibrated over the training distribution [3]. An ensemble is well-calibrated if the confidence ![\tilde{h}_k(x) = \mathbb{E}_{h_k \sim H_A}[h(x)]](https://aihub.org/wp-content/ql-cache/quicklatex.com-fc4fdfea2f1cee64d7a483f86ba72ac8_l3.png "Rendered by QuickLaTeX.com") it outputs for class
it outputs for class  matches the expected accuracy i.e.
matches the expected accuracy i.e.  . There exist various formalisms for calibration. In this paper, we show that if an ensemble satisfies class-wise calibration for a distribution D (a more general form of calibration is discussed in the paper), then
. There exist various formalisms for calibration. In this paper, we show that if an ensemble satisfies class-wise calibration for a distribution D (a more general form of calibration is discussed in the paper), then ![\mathbb{E}_{h, h'}[\mathbb{E}_D[h(x) \neq h'(x)]] = \mathbb{E}_h[\mathbb{E}_D[h(x) \neq y]]](https://aihub.org/wp-content/ql-cache/quicklatex.com-e9fb1b692b6167909954ee2b378b69d7_l3.png "Rendered by QuickLaTeX.com") with strict equality. We refer to this equality as the Generalization Disagreement Equality (GDE).
with strict equality. We refer to this equality as the Generalization Disagreement Equality (GDE).

Proof Sketch
The proof sketch we show here focuses on a special case, where class-wise calibration holds. Consider binary classification. Say that we have a distribution over the hypotheses  given SGD algorithm
given SGD algorithm  and we sample two hypotheses
and we sample two hypotheses  from this distribution. Now given some test data
from this distribution. Now given some test data  , we partition it by the confidence output by the ensemble i.e.
, we partition it by the confidence output by the ensemble i.e.  . For any fixed in the support of
. For any fixed in the support of  , the disagreement rate in expectation over is
, the disagreement rate in expectation over is
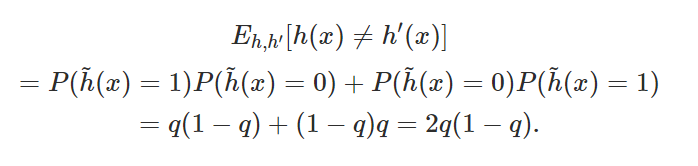
Additionally, note that for any  , the expected error equals
, the expected error equals  . Since the ensemble is also class-wise calibrated, for any
. Since the ensemble is also class-wise calibrated, for any  the expected error over
the expected error over  is
is
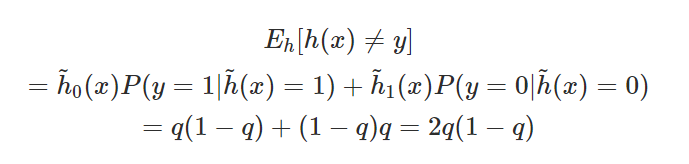
We proved that for each calibration level set, GDE holds. Since the disagreement rate 2q(1-q) equals the expected error 2q(1-q), we conclude that the expected error equals the disagreement rate. Since the disagreement rate 2q(1-q) equals the expected error 2q(1-q), we conclude that the expected error equals the disagreement rate. So in expectation over D, GDE holds.
Note the theorem only shows that the test error and expected disagreement are equal in expectation over all the models learned by SGD, but does not necessarily explain why the equality seems to hold for as few as a single pair of training runs. It captures the observation’s essence, but explaining why a single pair of models is sufficient is still an open problem. Intuitively, this can be true if the distribution of disagreement has an unusually small variance. In our experiments, we do observe very small variance for disagreement, but a rigorous theoretical discussion of why the variance is small remains unsettled.
Further, in practice, no models are perfectly calibrated, but we could still characterize how the deviation from calibration affects the GDE. We show that calibration error upper bounds the absolute difference between the expected disagreement and the expected calibration error. This inequality generalizes the GDE and implies that as long as the ensemble is reasonably calibrated, we can expect a good estimation of generalization error from disagreement. Finally, we empirically validate that this assumption often holds in practice by training 100 copies of the same model to produce an ensemble that is faithful to the true ensemble and measure their calibration error. The results show that these ensembles are indeed well-calibrated.
Conclusion
We have presented a method for estimating the generalization error of black-box deep neural networks with only unlabeled data, as well as some theoretical motivation for why the method works. Specifically, we showed that if the ensembles of the models trained by SGD are well-calibrated, the expected disagreement is equal to the expected test error. However, in practice, merely a single pair of models is sufficient for accurately estimating the generalization error. In the broader picture, this result marks a departure from the more traditional approaches of studying generalization and points to the tantalizing possibility of leveraging unlabeled data to estimate the generalization error. We are excited about the results we presented in the paper, but we are even more excited about the questions that we did not answer in the paper. We hope this work will encourage future work to investigate more unconventional ways of understanding generalization in deep learning.
Reference
[1] Nakkiran and Bansal. Distributional Generalization: A New Kind of Generalization. 2020.
[2] Li et al. Deeper, Broader and Artier Domain Generalization. IEEE Intl. Conf. on Computer Vision (ICCV), 2017.
[3] Lakshminarayanan et al. Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles. Conference on Neural Information Processing Systems (NeurIPS), 2017.
This article was initially published on the ML@CMU blog and appears here with the authors’ permission.
tags: deep dive

AUAI is supported by:








