
ΑΙhub.org
Interview with Virginie Do – #AAAI2022 outstanding paper award winner

Virginie Do, Sam Corbett-Davies, Jamal Atif and Nicolas Usunier won the AAAI 2022 outstanding paper award for their work Online certification of preference-based fairness for personalized recommender systems. The award was presented at this year’s virtual AAAI Conference on Artificial Intelligence. Here, Virginie Do tells us more about the implications of this research, the methodology, and their main findings.
What is the topic of the research in your paper?
Our paper is about fairness in recommender systems, and more precisely about certifying that recommender systems treat their users fairly.
Could you tell us about the implications of your research and why it is an interesting area for study?
We conducted this research in a context of increased interest in auditing for the fairness of recommender systems. For example, some recent studies observed different delivery rates of ads depending on gender for similar jobs [Imana et al., 2021]. In order to strengthen the conclusions of these audits, it is important to check if differences in recommendations imply a less favorable treatment of some users compared to others, or if they reflect differences in preferences across users. In our work, we propose a fairness criterion that fills this gap by putting user preferences at its core. This criterion, derived from the economic literature on fair resource allocation [Foley, 1967], is called envy-freeness and states that “every user should prefer their recommendations to those of other users”. In other words, this criterion aims to prevent the unfairness of not giving users a better recommendation policy, when one such is given to others.
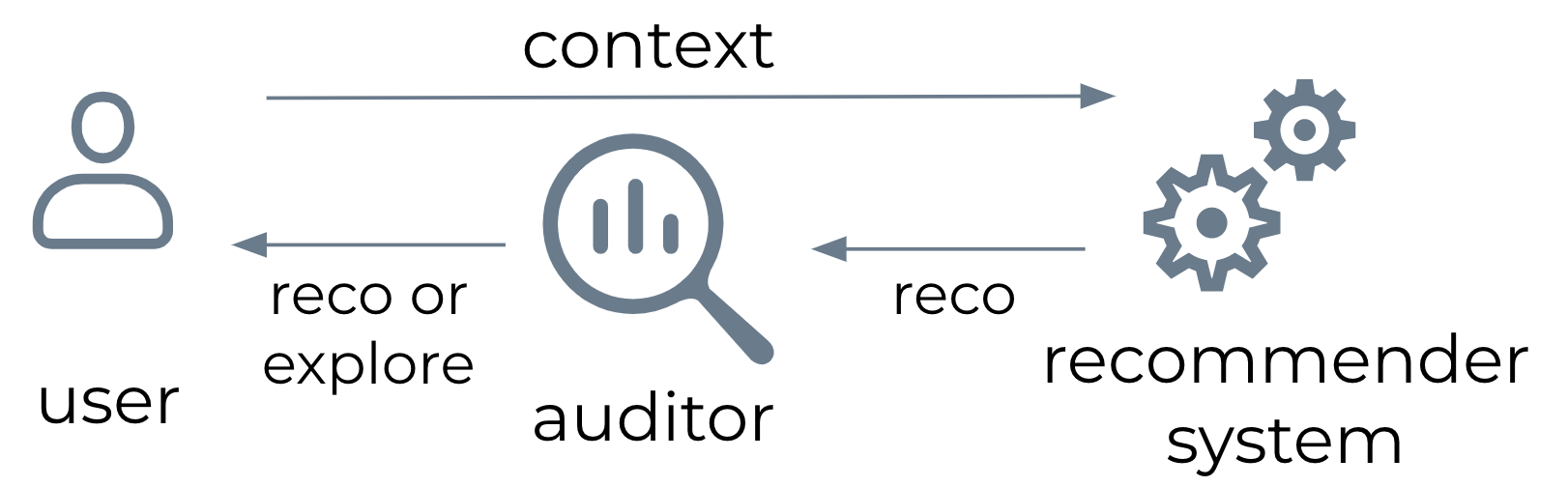 Auditing scenario for recommender systems: at each timestep, the auditor may replace a user’s recommendations with the recommendations that another user would have received in the same context.
Auditing scenario for recommender systems: at each timestep, the auditor may replace a user’s recommendations with the recommendations that another user would have received in the same context.
Could you explain your methodology?
The challenge of auditing for our fairness criterion is that it requires us to answer the counterfactual question “would user A get higher utility from the recommendations of user B than their own?” This kind of question can be reliably answered through active exploration, by swapping the current recommendation policy for a user with another existing recommendation policy, and estimating the preference of the user through noisy feedback such as “likes”, “shares” or ratings. This kind of exploration is typically done with multi-armed bandits algorithms. We design one such new algorithm specifically for the task of certifying fairness, in which we add the constraint that the exploration process should not deteriorate user satisfaction below a performance baseline.
What were your main findings?
There are two main contributions: the first one concerns the properties of our fairness criterion for recommender systems, and the second one is the new auditing algorithm we propose.
Envy-freeness satisfies several desirable properties:
- It is in line with giving users their most preferred recommendations, while other fairness criteria for users require to deviate from optimal recommendations.
- Recommender systems are two-sided markets involving users on one side and content producers on the other side. There is recent interest in designing recommender systems that are also fair towards their content producers, who benefit from the exposure they get on the platform [Singh and Joachims, 2018]. We prove that fairness as envy-freeness for users is compatible with enforcing fairness constraints on the content producer side.
Our other contribution is to design a sample efficient auditing algorithm, in the sense that it requires a reasonable amount of interactions with the user in order to certify envy (or the absence thereof). At the same time, we provide the theoretical guarantee that over the course of the audit, the recommendation performance for the user does not fall too far below a baseline. In practice, our experiments show that when the audited system is unfair to some users, the exploration process of the audit actually improves user satisfaction, instead of deteriorating it.
What further work are you planning in this area?
The auditing method we propose relies on simple modelling assumptions. To improve it, we need to refine our model to account for the dynamics of the recommendation environment, such as complex changes in user behaviour over the course of the audit.
References
- Do, V.; Corbett-Davies, S.; Atif, J.; and Usunier, N. 2022. Online certification of preference-based fairness for personalized recommender systems. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36.
- Foley, D. K. 1967. Resource allocation and the public sector.
- Imana, B.; Korolova, A.; Heidemann, J.; and . 2021. Auditing for Discrimination in Algorithms Delivering Job Ads. In Proceedings of the Web Conference 2021, 3767–3778.
- Singh, A.; and Joachims, T. 2018. Fairness of exposure in rankings. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2219–2228. ACM.
|
|
Virginie Do is a PhD candidate in Computer Science at Université Paris Dauphine–PSL in France, and a resident at Meta AI. Her research is on fairness in machine learning and social choice theory, with a specific focus on ranking and recommender systems, and online algorithms. She holds an MSc and BSc in Applied Mathematics from Ecole Polytechnique, France, and an MSc in Social Data Science from the University of Oxford, UK. |
tags: AAAI, AAAI2022

AIhub is supported by:








