
ΑΙhub.org
#ICLR2022 invited talk round-up 2: Beyond interpretability

In the second of our round-ups of the invited talks at the International Conference on Learning Representations (ICLR) we focus on the presentation by Been Kim.
Beyond interpretability: developing a language to shape our relationships with AI
Been Kim
Been Kim’s research focusses on interpretability and explanability of AI models. In this presentation she talked about work towards developing a language to communicate with AI systems. The ultimate goal is that we would be able to query an algorithm as to why a particular decision was made, and it would be able to provide us with an explanation. To illustrate this point, Been used the example of AlphaGo, and the famous match against world champion Lee Sedol. At move 37 in one of the games, AlphaGo produced what commentators described as a “very strange move” that turned the course of the game. It would be nice to know how AlphaGo reached the conclusion to play this move, and that we could query the system in some way to find out.
Been talked about the representational space of humans and machines. Although there is likely to be some overlap, what machines and humans can do is very different. There are many things for which only humans, or only machines have a representation. Move 37 lies in the region that only machines have a representation for. Ideally the two representation spaces would overlap as much as possible. The goal of human-AI language is to increase this overlap.
 Screenshot from Been Kim’s talk.
Screenshot from Been Kim’s talk.
This language would probably not look like any human language, and we would likely need many different languages depending on the nature of the task in question. For example, construction tasks would require a completely different language to writing tasks. Been noted that, although we don’t yet know what these human-AI languages would look like they should: 1) reflect the nature of the machines (as human languages reflect human nature) and 2) they should expand what we know (just like move 37 expanded the knowledge of Go players). She gave examples of work that she and her colleagues have been carrying out related to both of these aspects.
One piece of work concerns the Gestalt phenomena, whereby humans fill in missing information, for example, by seeing a full triangle when only the three corner parts of the shape are there. Been and colleagues found that machines can also “fill in” the missing information to “see” a triangle, but only after they’ve been trained to generalise.
Another study looked at how humans interact with explanations given by machines. In this case they investigated what happens when the explanations given are not perfect (“noisy”). In an experiment, human participants were playing a computer game in which they had to work as a chef in a busy kitchen, with the goal of preparing meals as quickly as possible. They got varying levels of advice from a machine, sometimes anchored to a high-level goal (for example: “chop tomatoes for the pasta sauce”), sometimes just an instruction (for example: chop tomatoes), sometimes no advice at all. Sometimes they received “noisy” advice. The goal for the team was to work out the impact of noisy explanations. They found that if the explanations were anchored to a higher-level goal, then, even if the advice was noisy, it still helped the human players. However, if the explanation was not anchored, then there was more degradation in performance when the noise was added. What was surprising was that, if used during the training period (not during deployment), noisy, anchored explanations were as good as anchored perfect explanations. This suggests that, even if explanations aren’t perfect, they can still significantly help humans.
Been talked about TCAV (Testing with Concept Activation Vectors), a general tool which provides an interpretation of a neural network’s internal state in terms of human-friendly concepts. The tool aims to find an alignment between a vector in human representational space and a vector in machine representational space. This is done by collecting examples of a concept (for example, “striped”) from humans, and passing these to a machine that is trained to look at images to get its representation of these striped images. This gives a vector that means something to humans represented in the machine space. This can be used to query the machine – for example: is the machine prediction of zebras sensitive to this striped concept?
This TCAV method can be used to help humans expand what we know. One interesting example concerns AlphaZero – the self-trained chess playing model from DeepMind. Been and her team collaborated with a World Chess champion to take a detailed look at AlphaZero and how it works. As the machine was self-trained, it learnt chess by playing against itself, and never saw a human play. This is interesting, because if we can prove that it shares some aspects of learning with humans, it could give us the potential to expand what we know. The research shows that human knowledge is acquired by the AlphaZero neural network as it trains. The team also looked at a broad range of human chess concepts (such as whether to capture the queen, putting an opponent in check), and showed when and where these concepts are represented in the AlphaZero network.
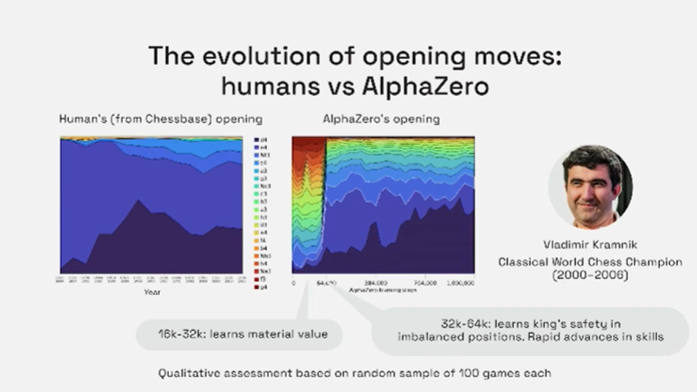 Screenshot from Been Kim’s talk.
Screenshot from Been Kim’s talk.
Another area of study concerned the opening moves of chess. In the figure above, you can see the evolution of human opening moves (from the many years that chess games have been recorded) versus the opening moves of AlphaZero as it trained. It is interesting to note that AlphaZero uses more diverse range of opening moves than humans. You can check out this interactive visualisation tool from Been and colleagues, that describes concepts from AlphaZero’s representational space. By studying how and what AlphaZero learns we could expand our own chess playing knowledge.
You can read Been’s blog post about her talk here. It includes links to published work on this topic.
tags: ICLR2022

AUAI is supported by:








