
ΑΙhub.org
New framework for cooperative bots aims to mimic high-performing human teams
A Georgia Institute of Technology research group in the School of Interactive Computing has developed a robotics system for collaborative bots that work independently to achieve a shared goal.
The system intelligently increases the information shared among the bots and allows for improved cooperation. The aim is to model high-functioning human teams. It also creates resiliency against bad or unreliable team bots that may hinder the overall programmed goal.
“Intuitively, the idea behind our new framework — InfoPG — is that a robot agent goes back-and-forth on what it thinks it should do with their teammates, and then the teammates will update on what they think is best to do,” said Esmaeil Seraj, Ph.D. student in the CORE Robotics Lab and researcher on the project. “They do this until the decision is deeply rationalized and reasoned about.”
The work focuses on artificial agents on a decentralized team — in simulations or the real world — working in concert toward a specific task. Applications could include surgery, search and rescue, and disaster response, among others.
InfoPG facilitates communication between the artificial agents on an iterative basis and allows for actions and decisions that mimic human teams working at optimal levels.
“This research is in fact inspired by how high-performing human teams act,” said Seraj.
“Humans normally use k-level thinking — such as, ‘what I think you will do, what I think you think I will do, and so on’ — to rationalize their actions in a team,” he said. “The basic thought is that the more you know about your teammate’s strategy, the easier it is for you to take the best action possible.”
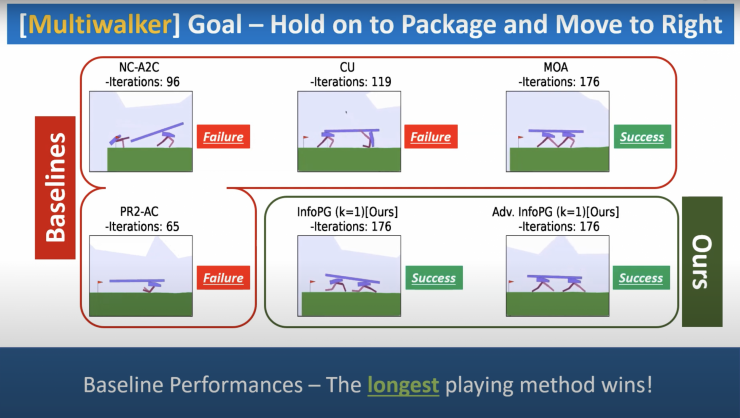
Using this approach, the researchers designed InfoPG to make one bot’s decisions conditional on its teammates. They ran simulations using simple games like Pong, and complex games like StarCraft II.
In the latter — where the goal is for one team of agents to defeat another — the InfoPG architecture showed very advanced strategies. Seraj said agents in one case learned to form a triangle formation, sacrificing the front agent while the two other agents eliminated the enemy. Without InfoPG in play, an agent abandoned its team to save itself.
The new method also limits the disruption a bad bot on the team might cause.
“Coordinating actions with such a fraudulent agent in a collaborative multi-agent setting can be detrimental,” said Matthew Gombolay, assistant professor in the School of Interactive Computing and director of the CORE Robotics Lab. “We need to ensure the integrity of robot teams in real-world applications where bots might be tasked to save lives or help people and organizations extend their capabilities.”
Results of the work show InfoPG’s performance exceeds various baselines in learning cooperative policies for multi-agent reinforcement learning. The researchers plan to move the system from simulation into real robots, such as controlling a swarm of drones to help surveil and fight wildfires.
The research is published in the 2022 Proceedings of the International Conference on Learning Representations. The paper, Iterated Reasoning with Mutual Information in Cooperative and Byzantine Decentralized Teaming is co-authored by computer science major Sachin G. Konan, Esmaeil Seraj, and Matthew Gombolay.
This work was sponsored by the Office of Naval Research under grant N00014-19-1-2076 and the Naval Research Lab (NRL) under the grant N00173-20-1-G009. The researchers’ views and statements are based on their findings and do not necessarily reflect those of the funding agencies.

AUAI is supported by:








