
ΑΙhub.org
Bootstrapped meta-learning – an interview with Sebastian Flennerhag
 Bootstrapped meta-gradients.
Bootstrapped meta-gradients.
Sebastian Flennerhag, Yannick Schroecker, Tom Zahavy, Hado van Hasselt, David Silver, and Satinder Singh won an ICLR 2022 outstanding paper award for their work Bootstrapped meta-learning. We spoke to Sebastian about how the team approached the problem of meta-learning, how their algorithm performs, and plans for future work.
Could you start by giving us an explanation of what meta-learning is?
Meta-learning, generally, is the problem of learning to learn. So what is meant by that is that when you specify a machine learning problem, you need some algorithm that does that learning. However, it’s not clear which algorithm is actually the most efficient one for the specific problem that you have in mind. Meta-learning is the machine learning variant of deciding which algorithm to run. So, you treat the machine learning problem as a learning problem in its own right and construct a meta problem where the goal is to learn the algorithm that is most effective for that underlying machine learning problem.
There’s two ways you can do that. One is to do that online; you have a problem that you’re trying to solve, and while you’re solving it, you’re simultaneously improving the algorithm that you’re using. That’s usually called single lifetime, or single task meta-learning. But, you can also have a class of tasks, that could be all the machine learning problems you could come up with in the space of natural languages, or something like that, and then you try to find the best algorithm to use for learning natural language tasks. In that case you can learn an algorithm on some tasks (so that’s your meta-training set) and then you hope that that algorithm will generalise when you apply it to learn other tasks that it hasn’t seen yet.
Could you talk about some of the challenges that need to be overcome to achieve efficient meta-learning?
One key aspect is to improve meta-optimisation, for which there are two main challenges, I would say. There are different ways you can do meta-learning, but the most prominent one is that you apply the algorithm you are trying to learn, then you evaluate its performance after some number of updates to see if it got better or worse. Based on that, you change the algorithm to make it more effective. The problem with that paradigm is that you often need to do a credit assignment process – basically you need to work out which of the updates were the ones that really mattered. This leads to a problem of curvature, which is made challenging because small changes early in training can end up having very large effects over a long learning period (imagine what can happen if you increase the learning rate).
The other challenge is that current meta-algorithms truncate the learning process. For example, to improve the algorithm, the meta-update would use, say, 1% of the entire learning process. But an improvement over that 1% can make the algorithm worse in the long run. This problem is called myopia – optimising for a learning period that’s much shorter than what you actually care about.
The way that previous research has tackled the curvature problem is to use some sort of curvature correction method that can be an optimiser like Adam, to try to stabilise the meta-optimization problem, or more sophisticated methods such as implicit differentiation.
For myopia, there are currently no algorithms that tackle this in a scalable manner. Our current best option is to try to apply the algorithm for more updates, making the meta-optimization and computations costlier, in the hope that myopia becomes less severe.
In our paper we try to tackle these two problems by coming up with a reformulation of the problem that naturally makes the problems less severe than what they currently are.
Could you talk about this reformulation and how your work approaches the meta-learning problem?
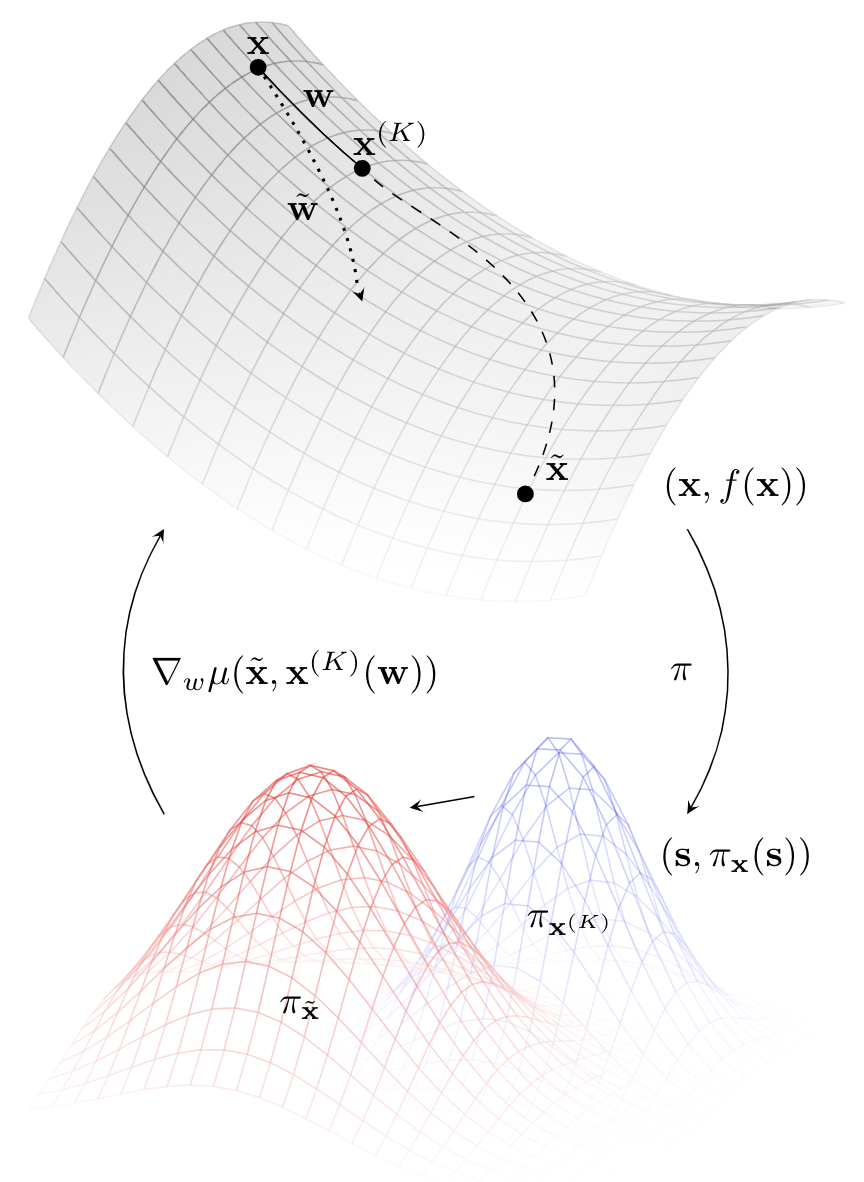
Our framework isn’t constrained to gradient-based meta-optmization but, for the sake of explanation, it’s easier if focus on that setting. In gradient-based meta-optimisation, the algorithm is meta-learned by applying it for some number of updates, before evaluating it under a meta-objective. To update the algorithm, we backpropagate through the meta-objective and all the updates to get a meta-gradient that signals how to improve the algorithm.
Our reformulation keeps this backpropagation mechanism. But, rather than evaluating the immediate performance after some number of updates we asked the question “if we had trained for longer (i.e. applied more updates) and assuming that that would have made us better, how should we change the meta-parameters so we get there faster?” Let’s look at an analogy. Say you do one year of schooling, your meta-objective would say “OK, but if you’d done two more years you would’ve learned all this other stuff. How should I change the curriculum so that you could learn all that in one year?” That’s the meta-optimisation problem that we’re building in the paper.
That mitigates myopia because it is forward-looking. It is bootstrapping into the future of learning and asking, what would’ve happened if we had trained for longer. Doing this expands the meta-optimisation horizon–the number of updates over which we are meta-optimising. A nice bonus of this formulation is that we can choose the space in which to match this future-looking target (i.e. how to measure closeness). One option is to measure the distance to the target in parameter space. Or, we can exploit an intrinsic geometry, such as the induced behaviour of an agent given. Because we can choose that matching space, we can make it correct for curvature. That will typically yield a much smoother optimisation landscape that takes away a lot of the challenges we see in meta-optimisation.
Could you talk a bit about bootstrapping and how you use that in this work?
The bootstrapping term specifically refers to using the algorithm we are meta-learning to construct a target. That is, given a computational budget, how should we change the algorithm so that it accelerates along its trajectory and reaches a future iterate faster? For that, we need a target, and that target is essentially telling the meta-learner what it should have done within its budget.
Bootstrapping is asking what would have happened if we’d kept training for longer with the current algorithm. However, this is not entirely safe, because if the algorithm is currently making things worse, bootstrapping naively from the algorithm would encourage the meta-learner to make the algorithm worse faster. In the paper, we found a simple heuristic that prevents this from happening. After bootstrapping for some number of updates, we apply a grounded algorithm that we know is an improvement step, such as gradient descent. That last grounded step nudges the target in a direction that improves performance, and so tells the meta-learner not only to accelerate its current trajectory, but also to nudge it in a direction that improves performance. With that said, there is still plenty we don’t yet know about this type of meta-learning and there are some really exciting research questions ahead of us.
In terms of testing your algorithm, how did you do that?
The first experiment we ran was a controlled experiment where we imagine we have an agent living in a simple world that contains two objects. At any point in time you want the agent to go and get one of them while avoiding the other. For example, at one point in time apples are good for you and carrots are bad for you and you want to go get apples, without taking any carrots on the way. And then suddenly it switches when you wake up one day and it’s the opposite, and so all of a sudden carrots are good and apples are bad. Now if you have memory you can just memorise a heuristic and you try one of each and then you take one that’s good for you. But, if you don’t have memory, like the agents in our experiment, every time there’s a switch they have to relearn.
The way the agent should behave is to have maximum exploration just after a switch (when it doesn’t know which one is good and which one is bad), and then, as it starts getting evidence of which one is better than the other, exploration should vanish quite rapidly so that the agent can converge on the optimal behaviour. We can meta-learn that kind of behaviour with our approach.
We compared the standard way of doing meta-learning, which would be to run the current algorithm for a bit and see what kind of performance it got, with our version, which has the bootstrapping mechanism. We found that the bootstrapping mechanism provided a significant improvement and gave rise to qualitatively different learning dynamics. We found that bootstrapping was important – the more we bootstrapped, the better the performance was. Even in simple situations like this, the problem of myopia is a real bottleneck. Bootstrapping into the future provides one way to mitigate this issue.
We then looked at Atari, which is a mainstream benchmark in reinforcement learning. There are essentially two types of reinforcement learning agents: model-based and model-free. The difference is whether they are trying to model the underlying environment or not. We were looking at model-free agents, which learn how to map an observation to an action directly. Such algorithms are relatively complex and have a multitude of hyper-parameters. Setting these correctly is crucial for them to work as expected, but more importantly, optimal performance typically requires changing the hyper-parameters during training. That’s where meta-learning comes in, as it can adapt the algorithm (i.e. its hyper-parameters) online while training.
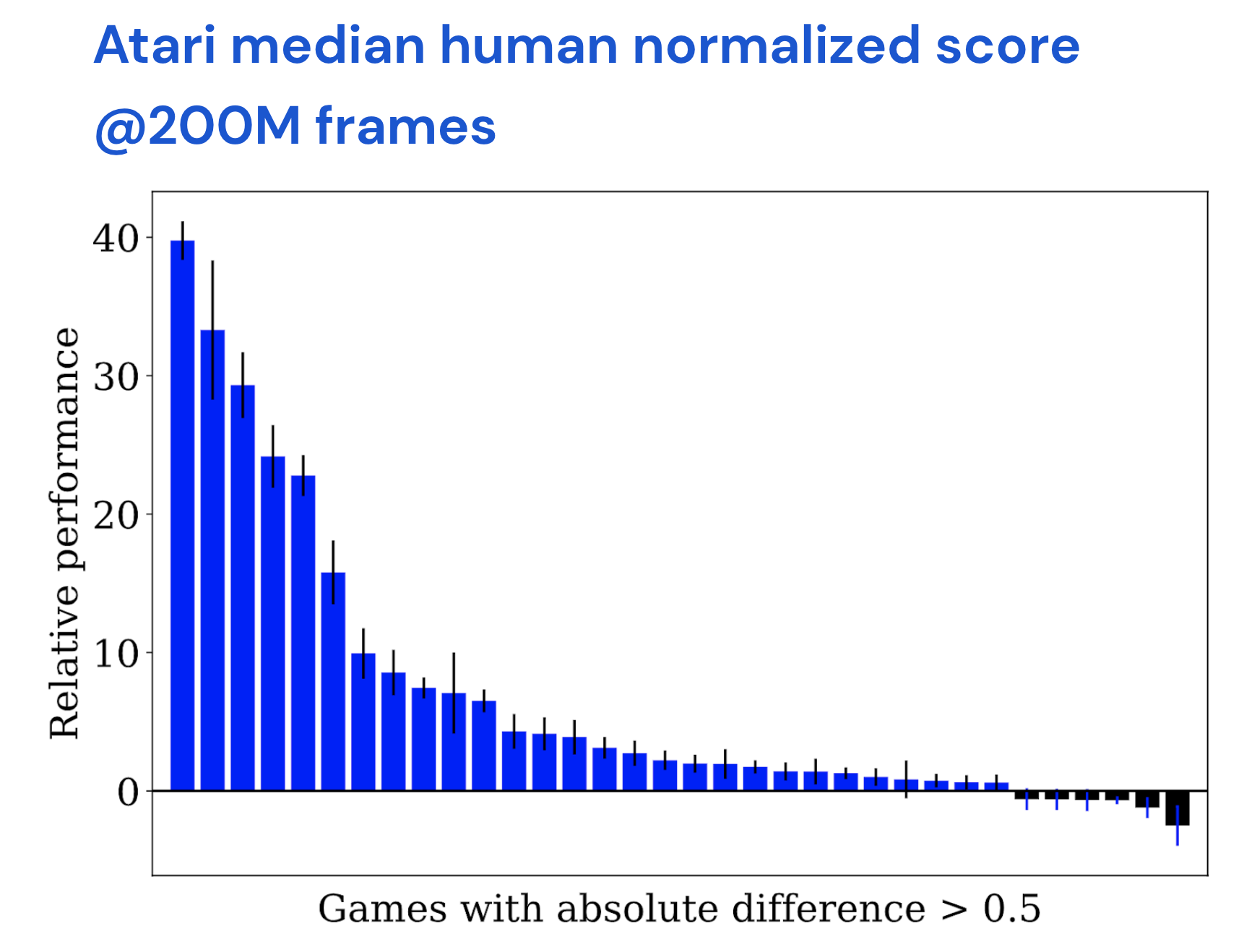 Human-normalized score across the 57 games in Atari ALE. Per-game difference in score between Bootstrapped Meta-Gradient (BMG) and the authors’ implementation of STACX∗ at 200M frames.
Human-normalized score across the 57 games in Atari ALE. Per-game difference in score between Bootstrapped Meta-Gradient (BMG) and the authors’ implementation of STACX∗ at 200M frames.
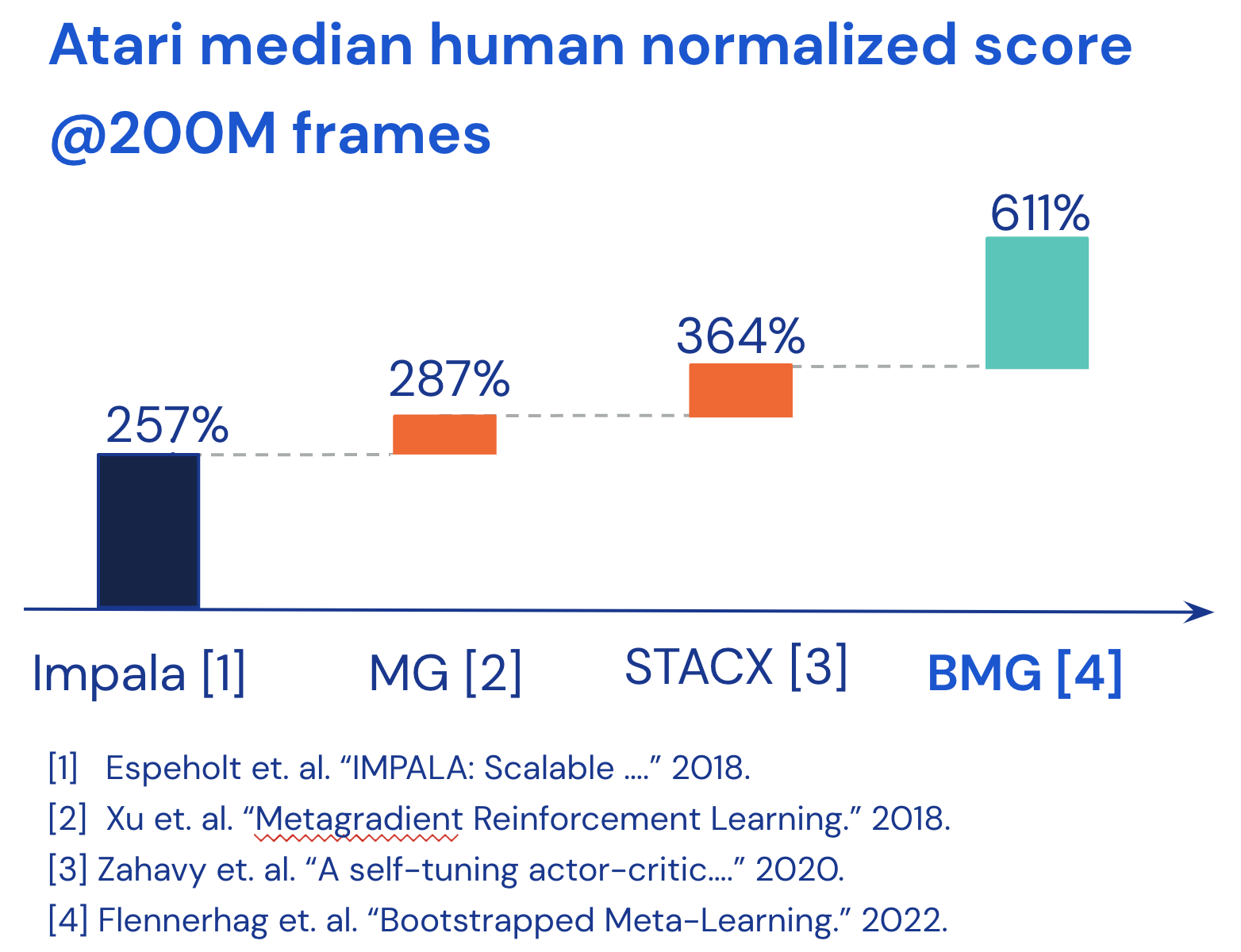
We compared the previous state-of-the-art for model free agents (which is also a meta-learning agent) with an agent that uses bootstrapped meta-learning. For fair comparison against the previous state-of-the-art agent, we quite literally just swapped the meta-objective for the meta-learner. We kept everything else constant. It turned out to have a very surprisingly large impact. A common metric to measure performance is the median human normalized score across all the games – that is, the score obtained by the agent minus that of the average human, aggregated across all games. If the score is larger than 100%, the agent is better than a human. The previous state-of-the-art (model free) agent achieves around 350% human normalized score (3.5 times the human normalised score). By changing the meta-objective to allow bootstrapped meta-learning, we obtained a human normalized score of 610%. To understand why we saw such large gains, we deconstructed our objective to isolate where the gains were coming from. We found that about half of the gains are due to correcting for curvature in meta-optimisation. High curvature means that the meta-loss landscape is extremely complex, making meta-optimisation difficult. By changing the space in which we match the target, and by correcting for curvature in the targets themselves, our method can yield a much smoother meta-loss surface that facilitates meta-optimisation. That was about 60% of the gains. The other 40% of the gains came from the bootstrapping mechanism, that is, by having a target that is future looking. So both myopia and curvature are significant bottlenecks in meta-learning and our algorithm can help mitigate both of them.
What are your future plans regarding this work?
There are three main directions to head in. One that we’ve been looking at recently is trying to understand on a more theoretical basis what the algorithm is actually doing. The target bootstraps we used in the paper are heuristics, so we’re trying to understand what the targets are actually doing, and see if we can always guarantee improvement and stability. The hope would be to design a meta-learner that works so well there’s no reason for practitioners in general not to use it. Something like how practitioners default to Adam because it works so well, just add it to whatever you are trying to learn and it will make it better. For that to happen, we need the bootstrapping mechanism to be stable which means we need to understand the fundamental principles that bootstrapping relies on.
Another direction is to meta-learn non-differentiable parts of an algorithm. In the paper, we showed that our method can meta-learn such meta-parameters because we do not need to backpropagate through the target. But that was mostly a proof of concept, much more can be done in this space. For instance, one can imagine meta-learning the architecture itself. While the method can be applied to such meta-parameters, we need to push the research a bit further to understand the best way in which we can deal with non-differentiable meta-parameters in a general way.
And finally, try it on more types of meta-learning. There are many kinds of meta-learning scenarios that we didn’t consider in the paper. Some of these could see equally large gains that we observed from bootstrapping. Hopefully we can help people who aren’t necessarily working on meta-learning by introducing some new tools to the toolbox.
About Sebastian

|
Sebastian Flennerhag is a research scientist at DeepMind. His research has focused on meta-learning, with applications in reinforcement learning and supervised learning. He is also actively pursuing research in open-ended learning and continual learning. Sebastian holds a Ph.D. from the University of Manchester, where his thesis focused on large-scale meta-learning. Prior to his research career, Sebastian studied Economics at the Stockholm School of Economics. |
Read the paper in full
Bootstrapped Meta-Learning, Sebastian Flennerhag, Yannick Schroecker, Tom Zahavy, Hado van Hasselt, David Silver, Satinder Singh.
tags: deep dive, ICLR2022

AIhub is supported by:








