
ΑΙhub.org
Evaluating cross-lingual transfer: Interview with Dan Malkin
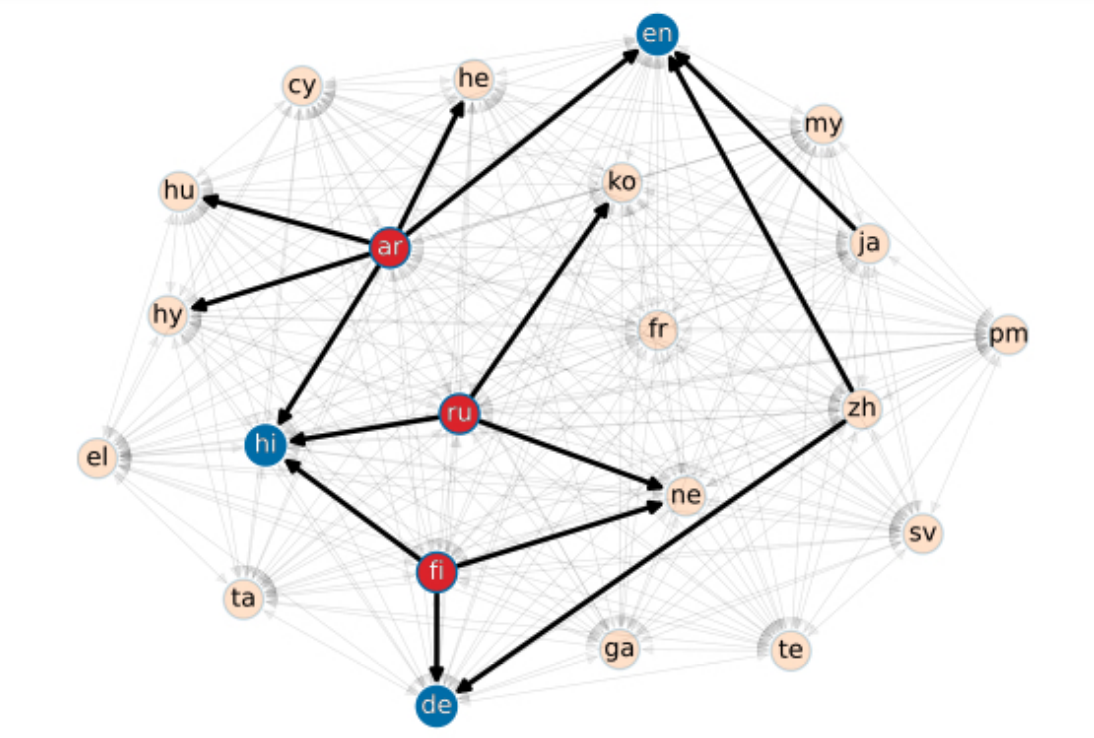 Bilingual training graph, showing examples of donating (red) and recipient (blue) languages. Image credit: Dan Malkin, Tomasz Limisiewicz, Gabriel Stanovsky.
Bilingual training graph, showing examples of donating (red) and recipient (blue) languages. Image credit: Dan Malkin, Tomasz Limisiewicz, Gabriel Stanovsky.
Dan Malkin, Tomasz Limisiewicz, Gabriel Stanovsky received an outstanding new method paper award at NAACL 2022 for their work A balanced data approach for evaluating cross-lingual transfer: mapping the linguistic blood bank. We spoke to Dan, who told us about multilingual models, the cross-lingual transfer phenomenon, and how the choice of pretraining languages affects downstream cross-lingual transfer.
Could you give us an overview of the topic of your research?
The topic of this research is multilingual models. Multilingual models are interesting because of the cross-lingual transfer phenomenon, in which a multilingual model pre-trained on many languages is able to transfer knowledge about a downstream particular task from one language to another. So, if you train a big model on various languages and then test it on a task, for example question-answering, in a different language, it can perform in a non-trivial manner. That is to say, it doesn’t perform in a state-of-the-art manner, but it isn’t random. You can get 70% F1 scores on various tasks.
What is the explanation for this phenomenon?
During pre-training, the model sees mutual linguistic knowledge across many languages, and this gives it neutral knowledge which is enough for it to transfer this general linguistic knowledge to a given task afterwards. So, pretraining gives multilingual knowledge and downstream tasks give task-specific knowledge which is not language-specific.
What is the current state of the field and are there any limitations to the present methodology?
Many of the multilingual models used are trained on unbalanced data, in terms of the different languages used (e.g., English comprises more of the training data than Thai). Usually, when you take off-the-shelf multilingual models you see highly unbalanced pre-training. This means that research done using these models could be influenced by the imbalance in pre-training data. However, there are often good reasons for this data imbalance. In many cases you can’t balance the low-resource data to match the high-resource data because of the large difference in available data between certain languages. It would lead to under-fitting on high-resource languages and over-fitting on low-resource languages.
We believe that you should try to analyze models trained in a more balanced way. We all know that more data means better performance, so we wanted to try to equalise the amount of data used in pre-training for each language to separate linguistic properties from data abundance. We tried to ask ourselves, is this bag of languages approach, which is done by taking all languages together and pre-training them, the best approach? Maybe we can dive a little bit deeper into that and try to see how certain languages help each other out.
There are many questions to be asked. We can ask whether there are specific linguistic features that are responsible for this cross-lingual transfer. We can ask whether there are similarities that are not based on linguistic features.
Could you explain your methodology?
What we did was to define a pre-training graph where we took 22 diverse languages and we trained models for all possible bilingual pairs of these 22 languages. To look at an example for one language pair, we take Arabic and French and we train in both directions: we take a French model and we fine-tune it on Arabic, and we take an Arabic model and fine-tune it on French. This is to capture the question: how well does a priori knowledge in a given language help me in the second language? We repeated this for all 22 languages.
If we take French as the example again, what we did was fine-tune on the other 21 languages, which gave us a row-vector. This shows the influence of French on the other languages. If you sum over this row vector you get a score, which we call the donation score. This score tries to capture how well French transfers its linguistic knowledge to other languages. In other words, how beneficial is French knowledge to other languages. We can also ask the reverse question; how do other languages benefit from French? We get a column vector for French and we can sum over that and get a recipient score. This measures how easily French is influenced by other languages.
Of course, this is not unique to French and we repeated it with all the other language combinations. We then have this plot which shows, for each language, how good a donor and how good a recipient it is.
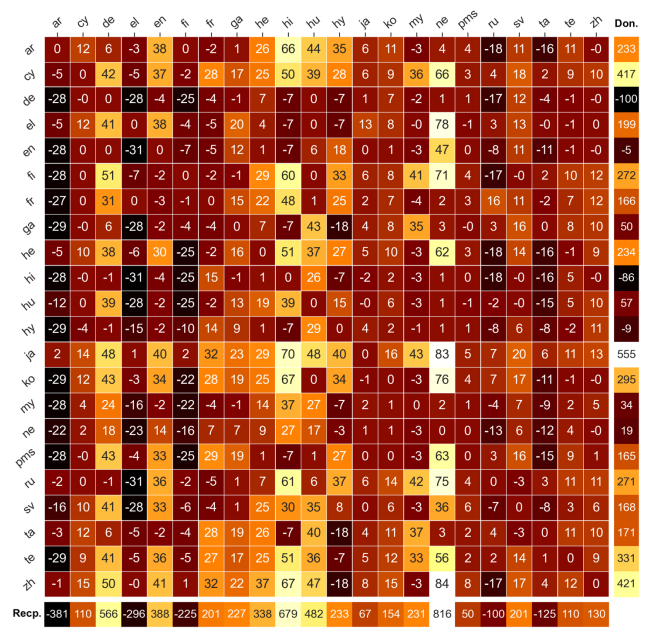 Bilingual finetune scores between language pairs in the authors’ balanced corpus. Image credit: Dan Malkin, Tomasz Limisiewicz, Gabriel Stanovsky.
Bilingual finetune scores between language pairs in the authors’ balanced corpus. Image credit: Dan Malkin, Tomasz Limisiewicz, Gabriel Stanovsky.
Was there a methodology for choosing the 22 languages?
Yes, we wanted to pick a set that was diverse. We tried to span many linguistic features and also genera. We also covered different scripts, and languages that use different subject and object orders. We really tried to span as much as possible in terms of linguistic features, so we could see broad effects and not effects which are specific to a subset of languages. We consulted some researchers from the linguistics department in our university and we chose pairs of languages that are similar with regards to certain linguistic features and different in others. We also cross-checked with various benchmarks, to see which languages we could measure performance for, because we wanted to evaluate our results.
What were your main findings?
One finding was that there are some languages that are strictly donating languages and they are bad recipients. There are other languages that are strictly recipients.
We wanted to ask how this influences the cross-lingual transfer phenomenon. We asked whether this donation and recipient score could be useful for big sets of languages. Let’s say we want a multilingual model, rather than a bilingual model. What we did was define four sets: the most-donating set, the least-donating set, and two control sets. Both sets were added to six languages (that we wanted to evaluate downstream) in pre-training. In the control group we did the same, but we didn’t add any languages. Instead, we added the same amount of data divided by the six languages that we would have added with the extra four in the other training group. For a downstream task, for example part-of-speech tagging, we can see that the most-donating set exhibits better than average zero-shot performance. However, if you take the least-donating set, the performance is worse than the control. This tells us that there is value in investigating what pre-training configurations your multilingual model will have.
Did any of the results you got surprise you?
Yes. Initially we constructed this graph to try and investigate linguistic features, and I hoped that features like language family would play a role, but this was actually very marginal or didn’t play a role at all. Things like shared vocabulary, or diverse vocabulary were more important than your language family. I was surprised that I couldn’t see any linguistic features playing an important role, like subject, verb, object order for example. But, because our models were small I wouldn’t say it’s a general conclusion, and maybe those properties would be apparent in bigger models.
What are your plans for future work?
One of the major motivations for this research is related to the fact that, in many ways, multilingual research is driven by computational capabilities. The larger corporations can just utilise huge amounts of data, train huge models, and see interesting phenomena. It is a bit frustrating. The rationale behind this work is that maybe you can work on a small-scale and achieve better results. Maybe if you choose the multilingual sets wisely you can achieve even better results than the huge models. I believe we can train multilingual models in a smarter way, perhaps doing it in subsets.
This also connects to low-resource languages, which are usually left behind. If we focus on inter-language influence and less on overall performance, and dive a little bit deeper, maybe we can utilise data for those languages.
Another point is green AI, and using less energy. Huge models contain all this multilingual knowledge and we don’t need to retrain all the time. Maybe we can utilise them to train smaller, more task-specific multilingual models.
Those are some of the things I am interested in for future work. This paper is the first step; the goal was to show that there is some sense in diving deeper into more specific language sets.
About the authors

|
Dan Malkin is a natural language (NLP) developer and a Master’s student at the Hebrew University of Jerusalem, advised by Professor Gabriel Stanovsky. He is interested in multilingual language models, NLP applications for education, and multi-modality. |

|
Tomasz Limisiewicz is a Computational Linguistics Ph.D. student at Charles University, Prague. He is interested in going into the inner workings of neural networks, multilingualism, and fairer NLP. |

|
Gabriel Stanovsky is interested in developing natural language processing models which deal with real-world texts and help answer multi-disciplinary research questions, e.g., in archeology, law, medicine, and more. He did his postdoc with Professor Luke Zettlemoyer at the University of Washington and with Professor Noah Smith at the Allen Institute for Artificial Intelligence (AI2), his PhD at Bar-Ilan University’s NLP lab, with Professor Ido Dagan, and his MSc thesis with Professor Michael Elhadad, at the Ben Gurion University. |
Read the paper in full
A balanced data approach for evaluating cross-lingual transfer: mapping the linguistic blood bank
Dan Malkin, Tomasz Limisiewicz, Gabriel Stanovsky

AUAI is supported by:








