
ΑΙhub.org
Interview with Paula Harder: super-resolution climate data with physics-based constraints

Paula Harder, and co-authors Qidong Yang, Venkatesh Ramesh, Alex Hernandez-Garcia, Prasanna Sattigeri, Campbell D. Watson, Daniela Szwarcman and David Rolnick, recently wrote a paper on Generating physically-consistent high-resolution climate data with hard-constrained neural networks. In this interview, Paula tells us more about how they developed a method for super-resolution climate data where conservation laws are enforced.
What is the topic of the research in your paper?
Our paper looks at super-resolution for climate data, which is called downscaling. Deep learning has been applied a lot recently in that area, but the neural networks employed tend to violate physical laws, such as mass conservation. In this work, we look at how to change neural super-resolution architectures such that given constraints like conservation laws are enforced.
Could you tell us about the implications of your research and why it is an interesting area for study?
With our new methodology super-resolution can be made feasible for scientific application, where a guarantee for conservation of some quantities is required. For example, if we look at climate model data, often already small violations of mass conservation can lead to huge instabilities when the data is fed back into a model. Our method can also help in many other application domains as well as potentially improve super-resolution in general.
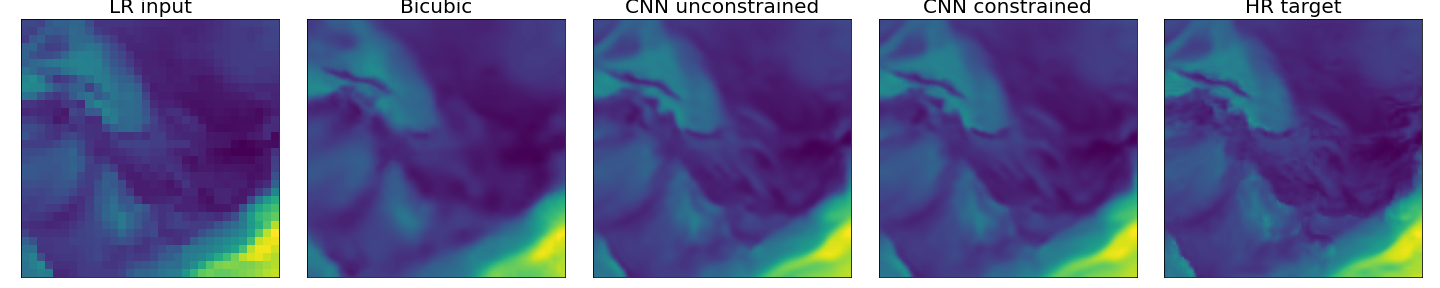 An example of spatial super-resolution prediction for different methods. Shown here is the low resolution input, different constrained and unconstrained predictions and the high-resolution image as a reference.
An example of spatial super-resolution prediction for different methods. Shown here is the low resolution input, different constrained and unconstrained predictions and the high-resolution image as a reference.
Could you explain your methodology?
Our first methodology is introducing a new layer at the end of a neural network, the constraint or renormalization layer. It is an adaption of a softmax layer, such that quantities between low-resolution input and predicted high-resolution output are conserved and the values are forced to be positive. This layer can then also be applied successively if we increase the resolution by a large factor.
What were your main findings?
Interestingly, we found that the constraining methodology not only gives us a prediction that obeys the physical laws but also has an increased predictive accuracy compared to the same architectures without that layer. This effect showed in all the architectures ranging from CNNs, over GANs to RNNs that also do super-resolution in the time dimension.
What further work are you planning in this area?
So far we only used one data set to develop and test our methodology. We would like to extend the application of our work to new data sets in climate science and other areas as well as to new architectures. We also plan to apply the constraining methodology to other climate model tasks besides downscaling.
About Paula
Paula Harder is an intern at Mila and a Ph.D. student in computer science at the Fraunhofer Institute. Her research focuses on physics-constrained deep learning for climate science, where she worked on emulating an aerosol model as a visiting researcher at the University of Oxford. Besides her work on climate machine learning (ML), she did work on adversarial attack detection and was involved with NASA’s and ESA’s Frontier Development Lab for projects on ML for space and earth science. Paula holds a master’s degree in mathematics from the University of Tübingen and worked in the automotive industry as a development engineer.
Read the research in full
Generating physically-consistent high-resolution climate data with hard-constrained neural networks
Paula Harder, Qidong Yang, Venkatesh Ramesh, Alex Hernandez-Garcia, Prasanna Sattigeri, Campbell D. Watson, Daniela Szwarcman and David Rolnick.

AUAI is supported by:








