
ΑΙhub.org
Mixing tokens with Fourier transforms to improve the efficiency of large language models
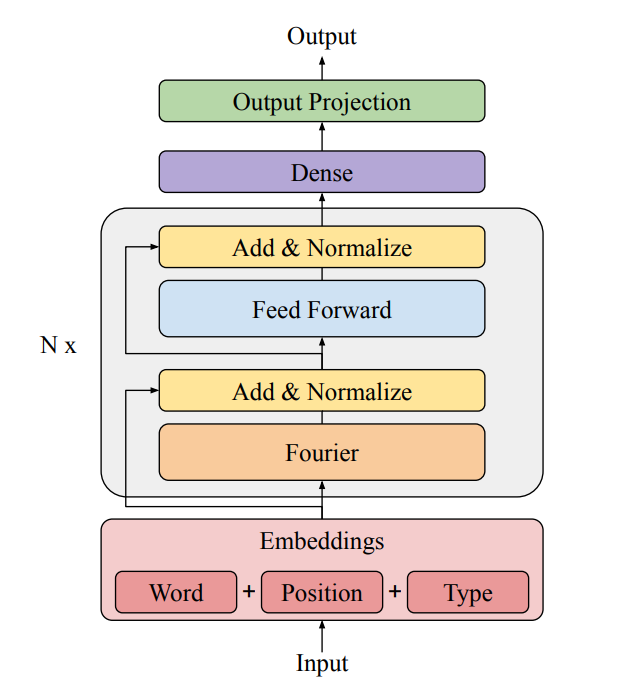 FNet model architecture.
FNet model architecture.
James Lee-Thorp, Joshua Ainslie, Ilya Eckstein and Santiago Ontañón won the best efficient NLP paper award at NAACL 2022 for their paper FNet: Mixing Tokens with Fourier Transforms. Here, the authors tell us about how they are working to improve the efficiency of large language models.
What is the topic of the research in your paper?
In our paper, we study faster transformer models. Transformers have proven remarkably successful at modeling everything from language to protein structures. We replace the computationally expensive self-attention layers in transformer encoders with faster, linear transformations. In the FNet model, we are essentially replacing self-attention with discrete Fourier transforms. This relatively simple substitution turns out to be quite effective.
Could you tell us about the implications of your research and why it is an interesting area for study?
Language models are incredibly powerful but generally compute heavy and relatively slow. More efficient variants of language models will enable a wider range of use cases (e.g. real-time serving in low latency settings), lower the energy footprints, and allow researchers to iterate on model designs and training faster.
Beyond the practical efficiency advantages of FNet, we make a few particularly exciting observations in our paper:
- While much of the power of transformer models is often attributed to the attention mechanism, our work suggests that you can actually build competitive models with little to no attention.
- FNet suggests searching for completely new transformations may be more fruitful than further efforts to design efficient but faithful approximations of attention.
Could you explain your methodology?
We started from the premise that the attention transformation in a transformer is really a mechanism for “mixing” tokens. That is, the attention layer combines inputs with relevance weighted coefficients in a basis of the original inputs. We asked if other transformations, and in particular faster, linear transformations, might serve a similar purpose by mixing inputs in a different basis, such as the Fourier basis.
We tested a number of different mixing replacements in BERT, and compared their performance in a classic NLP transfer learning setting: masked language modeling pre-training on a large corpus followed by fine-tuning on the GLUE suite of benchmarks.
What were your main findings?
We found that while the linear mixing transformations showed some limited quality degradations relative to BERT, they were generally much faster. FNet, which uses Fourier transforms to mix tokens, turned out to be particularly efficient. For typical input sizes, FNet achieves 92% of BERT’s accuracy on GLUE, but runs up to 80% faster. For longer input sizes, FNet performs even better: it is faster than all of the efficient transformer variants evaluated on the original Long Range Arena (a long input benchmark).
What further work are you planning in this area?
We want to close the quality gap with BERT, while maintaining the speed-ups of FNet. To this end, we are currently exploring combining mixing transformations with sparsity.
We also plan to look beyond encoder / BERT-style models. Can FNet and its mixing cousins be adapted to T5 encoder-decoder models and GPT style decoder-only models?
Finally, we only explored a limited number of mixing transformations. FNet gains its computational speed in part from the efficiency of the fast Fourier transform. We’d like to see if we can find other optimized transformations that could power different components of these models.
A final note:
This paper is dedicated to our colleague and co-author Ilya Eckstein, who passed away after the paper was written but before it was presented at NAACL. Ilya was a dear friend and a fierce advocate of this project and general out-of-the-box thinking. We miss him terribly.

|
James Lee-Thorp is a software engineer at Google. His research focuses on efficient methods in NLP: “can’t this thing go any faster!?” |

|
Josh Ainslie is a software engineer at Google whose current research centers around efficient deep learning architectures for NLP, especially for long sequences. His previous work has involved applications in dialog modeling, recommender systems, time series forecasting, and general quantitative analysis. |

|
Santiago Ontañón is a Research Scientist at Google, and an Associate Professor at Drexel University. His research interests include large language models, and applications of AI and machine learning to computer games. |
Read the research in full
FNet: Mixing Tokens with Fourier Transforms
James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontañón

AUAI is supported by:








