
ΑΙhub.org
Interview with Nina Wiedemann and Valentin Wüest: developing a gradient-based control method for robotic systems
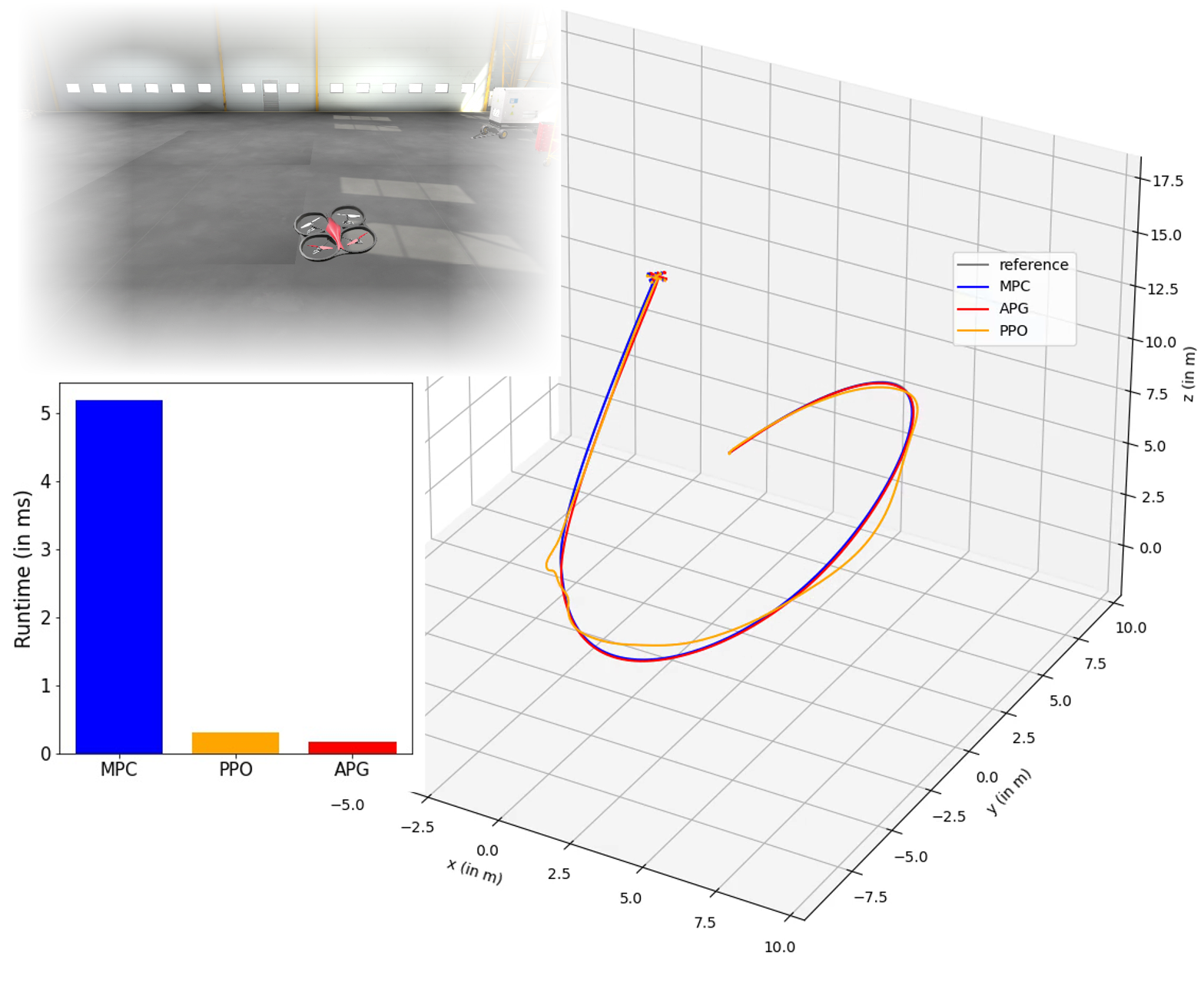
Nina Wiedemann, Valentin Wüest et al present an efficient and accurate control policy that is trained with the Analytic Policy Gradient method, and experiment with complex aerial robots such as a quadrotor (left). Their controller can track a reference trajectory accurately (right), within a fraction of the runtime required by online-optimisation methods such as MPC (bottom left).
In their recent paper, Training Efficient Controllers via Analytic Policy Gradient, Nina Wiedemann, Valentin Wüest, Antonio Loquercio, Matthias Müller, Dario Floreano, and Davide Scaramuzza propose a gradient-based method for control of robotic systems. First authors Nina Wiedemann and Valentin Wüest told us more about their approach, the motivation for the work, and what they are planning next.
What is the topic of the research in your paper?
Our paper is about control for robotic systems, with a focus on aerial vehicles. The state-of-the-art in this context are online-optimization methods such as Model Predictive Control (MPC). The issue with online optimization approaches is that they are quite computationally heavy. Other approaches rely on reinforcement learning to run the computationally-heavy training offline and thereby to reduce the computation cost during deployment. While reducing computation at runtime, such approaches treat the system as an unknown black box and in practice hardly achieve the same accuracy in trajectory tracking. We propose a gradient-based method called Analytic Policy Gradient (APG) that is also trained offline, as RL, but achieves high accuracy due to the use of knowledge about the system in the form of gradients.
Could you tell us about the implications of your research and why it is an interesting area for study?
While many other fields have been transformed completely by deep learning methods, the control literature is still predominantly optimization-focused. Our research provides a systematic comparison of optimization- and learning-based methods and demonstrates the existence of a learning-based method that is competitive. The higher computational efficiency of this method is particularly relevant for aerial vehicles where the payload weight and volume is limited. Also, learning methods have further advantages such as the possibility to easily integrate images or other high-dimensional inputs.
Could you explain your methodology?
The APG method is based on backpropagation-through-time; i.e., several actions are predicted by the model and executed in the environment while keeping track of the gradients. The error, i.e. the divergence from a desired reference trajectory, is then backpropagated through all time steps of the horizon. However, training with backpropagation-through-time is known to be unstable and to lead to exploding or vanishing gradients, as has also been encountered in training RNNs. We solve this issue with a curriculum learning algorithm, where we gradually increase the difficulty of the tracking task. In the end, the method achieves very similar behavior to MPC and can actually be trained with the same cost function.
What were your main findings?
We find that the tracking error of APG is almost on-par with MPC, while PPO and PETS (a model-free and a model-based RL baseline) perform significantly worse. In terms of runtime, APG is 10 times faster to compute than MPC. We also show that the learning paradigm allows for vision-based control and for fast adaptation to new environments.
What further work are you planning in this area?
We would, for example, like to further investigate the performance of the method for adaptation tasks. And, of course, we would like to test our algorithm on a real drone!
About the authors

|
Nina Wiedemann has worked on control in the Robotics Perception Group of Davide Scaramuzza and is now a PhD student in the Mobility Information Engineering Lab at ETH Zürich. |

|
Valentin Wüest is a PhD student in robotics, control, and intelligent systems at Swiss Federal Institute of Technology Lausanne (EPFL). |
Read the research in full
Training Efficient Controllers via Analytic Policy Gradient, Nina Wiedemann, Valentin Wüest, Antonio Loquercio, Matthias Müller, Dario Floreano, Davide Scaramuzza.

AIhub is supported by:








