
ΑΙhub.org
Counterfactual explanations for reinforcement learning: interview with Jasmina Gajcin

In their recent paper, Jasmina Gajcin and Ivana Dusparic study counterfactual explanations for reinforcement learning. In this interview, Jasmina told us more about counterfactuals and some of the challenges of implementing them in reinforcement learning settings.
What is the area of research that you cover in your paper, and why is it an interesting area for study?
In this work, we explored the topic of counterfactual explanations for reinforcement learning (RL). RL enables intelligent agents to learn sequential tasks through a trial-and-error process. In the last decade, RL algorithms have been developed for healthcare, autonomous driving, games etc. (Li et al. 2017). However, RL agents often rely on neural networks, making their decision-making process difficult to understand and hindering their adoption to real-life tasks (Puiutta et al. 2020).
In supervised learning, counterfactual explanations have been used to answer the question: Given that model produces output A for input features f1 …fk, how can the features be changed so that model outputs a desired output B? (Verma et al. 2020) Counterfactual explanations give actionable advice to humans interacting with an AI system on how to change their features and achieve a desired output. For example, if a user is rejected for a loan by an AI system, counterfactual explanations could assist them in changing their failed application to receive a loan in the future. Since user trust in the system can depend on counterfactual explanations, it is important that they do not suggest infeasible changes to features and provide the easiest path to the desired outcome.
While explored in supervised learning, counterfactual explanations have been seldom applied to RL. In this work we explore the problem of applying this powerful, user-friendly explanation method to RL tasks.
As part of your work you carried out a survey into counterfactual explanations in supervised learning scenarios. What were the main conclusions that you came to?
Counterfactual explanations in supervised learning are a recently emerging field and classifying work on this topic is a challenging task. However, after conducting a survey into the most important approaches we identified the common themes among the methods. Firstly, a large majority of methods follow a similar approach, in which a loss function consisting of different counterfactual properties is defined and optimized over the training data set to find the most suitable counterfactual. For example, the first work on counterfactual explanations for supervised learning (Wachter et al. 2017) optimizes proximity and validity properties, to ensure that the counterfactual instance is close to the original and produces the desired outcome. There is, however, little consensus on the best metrics for counterfactual properties, with each method taking a slightly different approach. This issue is additionally exacerbated by the presence of categorical features, that are usually not straightforward to measure and compare across counterfactuals.
What are the main differences between counterfactual explanations in supervised learning and reinforcement learning?
The need for explainability of supervised learning and RL methods comes from the same source — reliance on neural networks. For that reason, some explainability techniques such as saliency maps have been successfully translated from supervised to RL tasks without much modification (Simonyan et al. 2013, Huber et al. 2022).
However, the differences between supervised and RL frameworks are more substantial from the perspective of counterfactual explanations. Supervised learning focuses on the one-step prediction tasks, and input features are considered the only causes of a prediction. RL agents, on the other hand, solve sequential problems, and their decisions can be influenced by both state features and other components such as goals, objectives or outside events. Incorporating all possible causes of decisions into counterfactual explanations is essential for achieving user understanding. For example, consider an autonomous vehicle which at every time step optimizes different objectives such as speed, safety, driver comfort etc. If the car fails to slow down in a critical situation, and as a consequence causes an accident, counterfactual explanation could identify that, had the agent preferred safety over speed in the state, it would have chosen to slow down and the collision would have been avoided. Such explanations cannot be provided unless additional explanation components such as goals, objectives and outside events are included in the counterfactual explanations.
Another difference between counterfactuals for supervised and RL is exemplified in the notion of reachability. Ideally, counterfactuals should be easily obtainable from the original instance, to give users the easiest path to the desired outcome. In supervised learning, the notion of reachability is behind different counterfactual properties such as proximity, sparsity, actionability and data manifold closeness, which all ensure that a counterfactual instance is realistic and easy to obtain. However, all these properties rely only on feature-based metrics. For example, proximity is often represented as feature-based distance between two states, and sparsity as the number of features that need to be changed to obtain the counterfactual. In RL, however, two states can be similar in terms of features but far away in terms of execution. Reachability in RL for that reason does not depend only on feature values, but also on the RL actions needed to navigate from the original to the counterfactual instance. Ignoring the sequential and stochastic nature of RL tasks could produce misleading counterfactuals which suggest to the user similar but unreachable situations.
In this context, what are some of the challenges in implementing methods that work for supervised learning in a reinforcement learning setting?
One of the main challenges for generating counterfactual explanations in RL is the absence of natural search space. In supervised learning, training data set is often used as a proxy for a space of realistic instances and counterfactual search is performed over it. In RL, however, the training data set is not naturally available. While a dataset could be obtained by unrolling agent’s policy, if a counterfactual requires changing a goal or an objective of the agent, it is unlikely to be represented in the agent’s policy.
Additional challenges of implementing counterfactual explanations in RL include estimating reachability of counterfactual instances from the original instance and integrating different explanation components such as goals and objectives. Reachability needs to take into account not just the difference between state features, but also the distance between states in often stochastic RL environments. Introducing different explanation components requires research on metrics for evaluating counterfactual properties that can integrate changes in state features, with changes in more complex components such as goals and objectives.
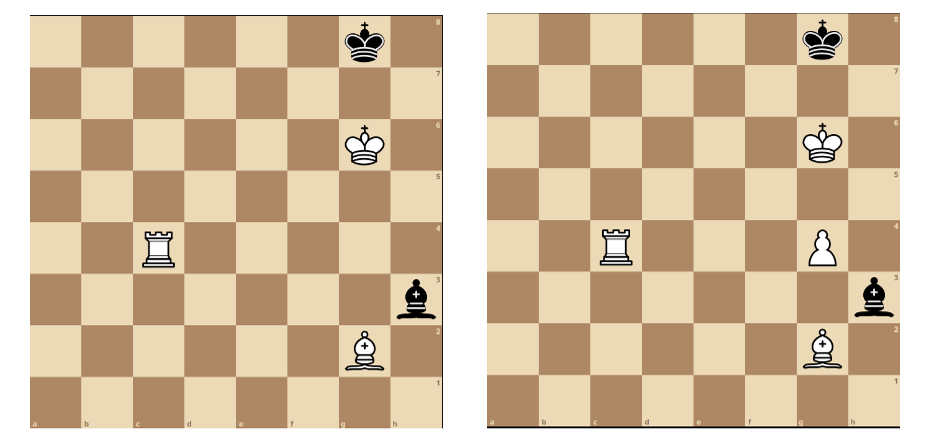 Illustrating one of the challenges of counterfactual explanations in RL. Left: original game state ?. Right: cf game state ?′, answering the question “In what position would c4c8 be the best move?”. While the provided counterfactual is similar to the original state based on its state features, it is not reachable from the original state using the rules of the game, and as such does not offer actionable advice to the user.
Illustrating one of the challenges of counterfactual explanations in RL. Left: original game state ?. Right: cf game state ?′, answering the question “In what position would c4c8 be the best move?”. While the provided counterfactual is similar to the original state based on its state features, it is not reachable from the original state using the rules of the game, and as such does not offer actionable advice to the user.
Finally, there are some challenges that exist both in supervised and RL learning. For example, handling categorical features is challenging in both fields, as it can be difficult to define their relationships and ordering. Additionally, in both fields there is a lack of consistent evaluation metrics and benchmark tasks, making it difficult to evaluate and compare different methods.
What are your recommendations for implementing counterfactuals in reinforcement learning?
In this work we propose a complete reimagining of counterfactual explanations for RL. We propose that counterfactual explanations and their properties need to be redefined for RL use. Firstly, counterfactuals need to rely on changing not only features but also other causes of decisions such as goals, objectives or outside events. As a consequence, counterfactual properties such as proximity, sparsity and actionability need to be redefined to account for different explanation components. Existing work on reward function similarity can for example serve as an inspiration for developing metrics that rely on the RL-specific explanation components.
Additionally, we propose that counterfactual explanations need to incorporate temporal and stochastic constraints and offer easily and certainly reachable counterfactuals to the users. The notion of reachability can depend on the task, and further research is necessary to identify most promising metrics for evaluating how quickly and with what certainty the counterfactual can be achieved.
Finally, further research is needed in incorporating categorical features in counterfactual methods. This problem is present in supervised learning as well, but it is additionally exacerbated by the introduction of RL-specific explanation components such as goals or objectives, which are often categorical in nature. Further work is also necessary on benchmark environments, to enable evaluation and comparison of different counterfactual methods. Preprint of our publication containing these findings can be found here.
About Jasmina

|
Jasmina Gajcin is a PhD student at Trinity College Dublin funded by Science Foundation Ireland CRT-AI program. Her research focuses on explainability for reinforcement learning agents and specifically on developing counterfactual explanations. Aside from research, she enjoys teaching and serves as a tutor in Scholar Ireland and CodePlus programs for promoting computer science careers to secondary school students. |
References
Li, Y. (2017). Deep reinforcement learning: An overview. arXiv preprint arXiv:1701.07274.
Puiutta, E., & Veith, E. (2020, August). Explainable reinforcement learning: A survey. In International cross-domain conference for machine learning and knowledge extraction (pp. 77-95). Springer, Cham.
Verma, S., Dickerson, J., & Hines, K. (2020). Counterfactual explanations for machine learning: A review. arXiv preprint arXiv:2010.10596.
Wachter, S., Mittelstadt, B., & Russell, C. (2017). Counterfactual explanations without opening the black box: Automated decisions and the GDPR. Harv. JL & Tech., 31, 841.
Simonyan, K., Vedaldi, A., & Zisserman, A. (2013). Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv preprint arXiv:1312.6034.
Huber, T., Limmer, B., & André, E. (2022). Benchmarking perturbation-based saliency maps for explaining Atari agents. Frontiers in Artificial Intelligence, 5.
Adam Gleave, Michael Dennis, Shane Legg, Stuart Russell, and Jan Leike. (2020). Quantifying differences in reward functions. arXiv preprint arXiv:2006.13900.

AUAI is supported by:








