
ΑΙhub.org
Estimating manipulation intentions to ease teleoperation

Teleoperation is one of the longest-standing application fields in robotics. While full autonomy is still work in progress, the possibility to remotely operate a robot has already opened scenarios where humans can act in risky environments without endangering their own safety, such as when defusing explosives or decommissioning nuclear waste. It also allows one to be present and act even at great distance: underwater, in space, or inside a patient miles away from the surgeon. These are all critical applications, where skilled and qualified operators control the robot after receiving specific training to learn to use the system safely.
Teleoperation for everyone?
The recent pandemic has yet made even more apparent the need for immersive telepresence and remote action also for non-expert users: not only could teleoperated robots take vitals or bring drugs to infectious patients, but we could assist our elderly living far away with chores like moving heavy stuff, or cooking, for example. Also, numerous physical jobs could be executed from home.
The recent ANA-Xprize finals have shown how far teleoperation can go (see this impressive video of the winning team), but in such situations both the perceptual and control load lie entirely on the operator. This can be quite taxing on a cognitive level: both perception and action are mediated, by cameras and robotic arms respectively, reducing the user’s situation awareness and natural eye-hand coordination. While robot sensing capabilities and actuators have undergone relevant technological progress, the interface with the user still lacks intuitive solutions facilitating the operator’s job (Rea & Seo, 2022).
Human and robot joining forces
Shared control has gained popularity in recent years, as an approach championing human-machine cooperation: low-level motor control is carried out by the robot, while the human is focused on high-level action planning. To achieve such a blend, the robotic system still needs a timely way to infer the operator intention, so as to consequently assist with the execution. Usually, motor intentions are inferred by tracking arm movements or motion control commands (if the robot is operated by means of a joystick), but especially during object manipulation the hand is tightly following information collected by the gaze. In the last decades, increasing evidence in eye-hand coordination studies has shown that gaze reliably anticipates the hand movement target (Hayhoe et al., 2012), providing an early cue about human intention.
Gaze and motion features to estimate intentions
In a contribution presented at IROS 2022 last month (Belardinelli et al., 2022), we introduced an intention estimation model that relies on both gaze and motion features. We collected pick-and-place sequences in a virtual environment, where participants could operate two robotic grippers to grasp objects on a cluttered table. Motion controllers were used to track arm motions and to grasp objects by button press. Eye movements were tracked by the eye-tracker embedded in the virtual reality headset.
Gaze features were computed by defining a Gaussian distribution centered at the gaze position and taking for each object the likelihood for it to be the target of visual attention, which was given by the cumulative distribution collected by the object bounding box. For the motion features, the hand pose and velocity were used to estimate the hand’s current trajectory which was compared to an estimated optimal trajectory to each object. The normalized similarity between the two trajectories defined the likelihood of each object to be the target of the current movement.

 Figure 1: Gaze features (top) and motion features (bottom) used for intention estimation. In both videos the object highlighted in green is the most likely target of visual attention and of hand movement, respectively.
Figure 1: Gaze features (top) and motion features (bottom) used for intention estimation. In both videos the object highlighted in green is the most likely target of visual attention and of hand movement, respectively.
These features along with the binary grasping state were used to train two Gaussian Hidden Markov Models, one on pick and one on place sequences. For 12 different intentions (picking of 6 different objects and placing at 6 different locations) the general accuracy (F1 score) was above 80%, even for occluded objects. Importantly, for both actions already 0.5 seconds before the end of the movement a prediction with over 90% accuracy was available for at least 70% of the observations. This would allow for an assisting plan to be instantiated and executed by the robot.
We also conducted an ablation study to determine the contribution of different feature combinations. While the models with gaze, motion, and grasping features performed better in the cross validation, the improvement with respect to only gaze and grasping state was minimal. Even when checking obstacles nearby at first, in fact, the gaze was already on the target before the hand trajectory became sufficiently discriminative.
We also ascertained that our models could generalize from one hand to the other (when fed the corresponding hand motion features), hence the same models could be used to concurrently estimate each hand intention. By feeding each hand prediction to a simple rule-based framework, basic bimanual intentions could also be recognized. So, for example, reaching for an object with the left hand while the right hand is going to place the same object on the left hand is considered a bimanual handover.
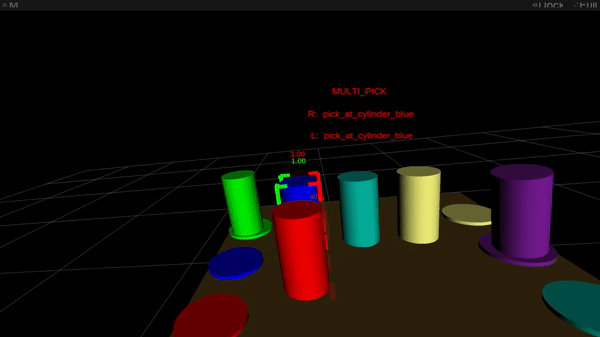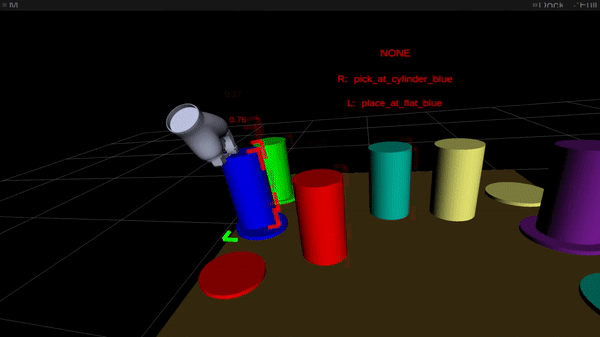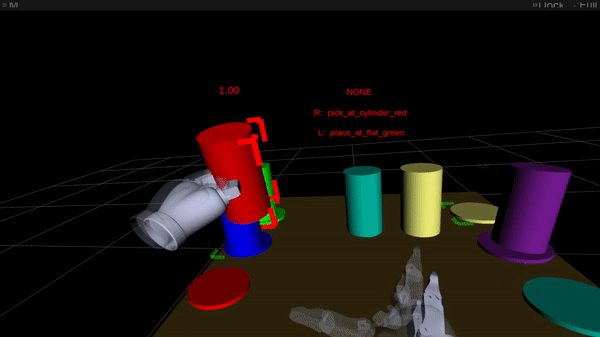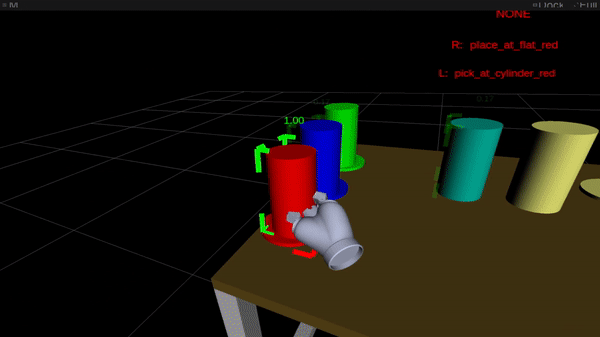 Figure 2: Online intention estimation: the red frame denotes the current right-hand intention prediction, the green frame the left-hand prediction. Above the scene, the bimanual intention is shown in capital letters.
Figure 2: Online intention estimation: the red frame denotes the current right-hand intention prediction, the green frame the left-hand prediction. Above the scene, the bimanual intention is shown in capital letters.
Such an intention estimation model could help an operator to execute such manipulations without focusing on selecting the parameters for the exact motor execution of the pick and place, something we don’t usually do consciously in natural eye-hand coordination, since we automated such cognitive processes. For example, once a grasping intention is estimated with enough confidence, the robot could autonomously select the best grasp and grasping position and execute the grasp, relieving the operator of carefully monitoring a grasp without tactile feedback and possibly with inaccurate depth estimation.
Further, even if in our setup motion features were not decisive for early intention prediction, they might play a larger role in more complex settings and when extending the spectrum of bimanual manipulations.
Combined with suitable shared control policies and feedback visualizations, such systems could also enable untrained operators to control robotic manipulators transparently and effectively for longer times, improving the general mental workload of remote operation.
References
Belardinelli, A., Kondapally, A. R., Ruiken, D., Tanneberg, D., & Watabe, T. (2022). Intention estimation from gaze and motion features for human-robot shared-control object manipulation. 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022.
Hayhoe, M. M., McKinney, T., Chajka, K., & Pelz, J. B. (2012). Predictive eye movements in natural vision. Experimental brain research, 217(1), 125-136.
Rea, D. J., & Seo, S. H. (2022). Still Not Solved: A Call for Renewed Focus on User-Centered Teleoperation Interfaces. Frontiers in Robotics and AI, 9.

AUAI is supported by:








