
ΑΙhub.org
#AAAI2023 invited talk: Isabelle Augenstein on modelling information change in scientific communication

Isabelle Augenstein was one of the invited speakers at this year’s AAAI Conference on Artificial Intelligence. She presented some of her work relating the communication of scientific research, and how information changes as it is reported by different media.
Accurate reporting of science and technology is of paramount importance. The general public relies principally on mainstream media outlets for their science news. Overhyping, exaggeration and misrepresentation of research findings erode trust in science and scientists. Isabelle noted that survey results have shown (not surprisingly) that the public perception of science is largely shaped by how journalists present the science, rather than the science itself.
One area in particular that tends to fall victim to skewed reporting is health science. In many mainstream outlets it is not usual to see a plethora of headlines claiming that “X cures cancer”, “Y causes cancer”, and very often, that Z can both cause and cure cancer.
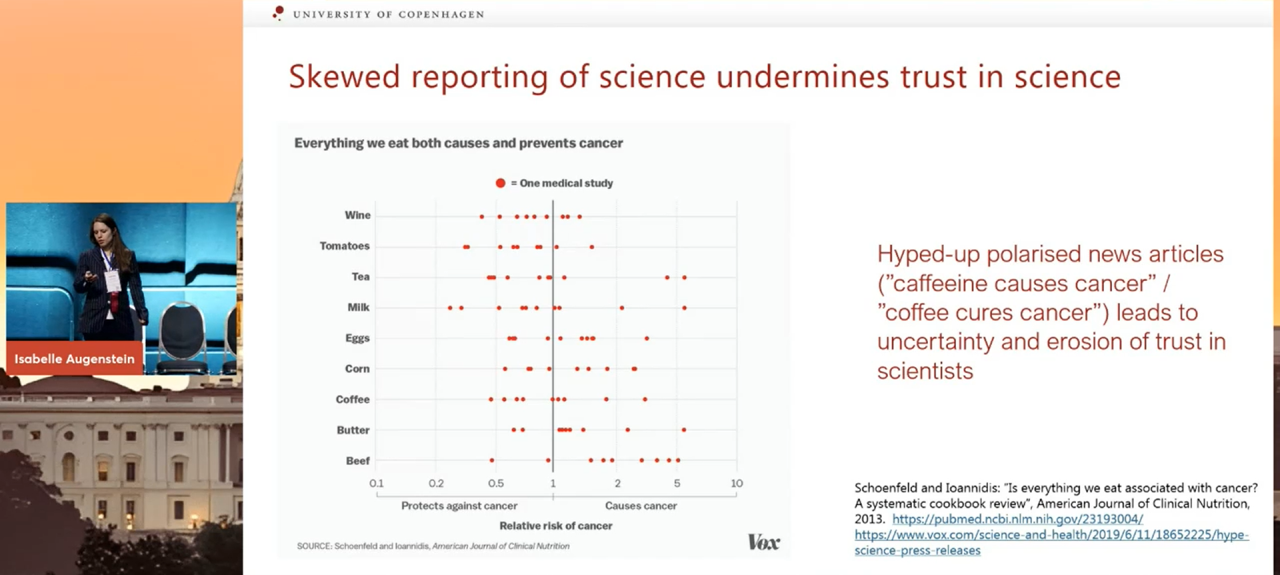 Foods that (both) cure and cause cancer, according to mainstream media outlets.
Foods that (both) cure and cause cancer, according to mainstream media outlets.
One way to combat misinformation is for scientists to become more involved in science communication and to set the record straight when they encounter hype and incorrect or misleading reporting. Isabelle believes that, in parallel to this, it is important to build tools and resources that allow us to better understand how information change happens. She decided to apply her background in natural language processing (NLP) to addressing some of the problems pertaining to science communication. In her talk she covered two main topics: 1) exaggeration detection, 2) modelling information change.
Exaggeration detection in science communication
In this piece of research, Isabelle and her team investigated the difference between original pieces of scientific research and press releases. They focussed their efforts solely on the field of health sciences. The problem was to formalise the task of scientific exaggeration detection by predicting when a press release exaggerates the findings of a scientific article.
As inputs to their model, they took the main finding as reported in a) the abstract of a scientific paper and b) the associated press release. The method they developed was multi-task semi-supervised and based on Pattern Exploiting Training (PET). PET is a procedure that reformulates input examples as cloze-style phrases. In this multi-task method, the two tasks they employed were 1) exaggeration detection and 2) detection of the strength of causal claims made in both the scientific articles and the press releases.
It was found that this multi-task training method, combined with a specially curated expert-annotated dataset of abstract-press release pairs, outperformed previous methods for identifying causal claims, particularly when there was limited training data available.
You can read more about this research in this article: Semi-Supervised Exaggeration Detection of Health Science Press Releases.
Modelling information change
Exaggeration is just one of the ways in which information changes between publication of a scientific article and its coverage in the press. The next step for Isabelle and her team was to investigate information change more broadly. This change can range from completely incorrect claims to messages that aren’t necessarily false, but that miss the nuance and accuracy of the original finding.
 A real example from the dataset that Isabelle and colleagues created as part of their research. It shows how information changes from the original paper, to the press release, to social media.
A real example from the dataset that Isabelle and colleagues created as part of their research. It shows how information changes from the original paper, to the press release, to social media.
Isabelle described the more general model that she and her colleagues built. The goal is that, given a scientific finding and the version described in the press release or in the press, the model outputs a score between 1 and 5 depending on how similar the information content is between the two. The higher the score, the closer the match.
To compile the data, the team used Altmetric, an aggregator which links press releases, blog posts, press coverage, and tweets to scientific papers. They annotated a dataset from four fields: computer science, medicine, biology and psychology, using domain experts. The resulting dataset is called SPICED (Scientific Paraphrase and Information ChangE Dataset), and contains 6,000 scientific finding pairs extracted from news stories, social media discussions, and full texts of original papers. It is the first paraphrase dataset of scientific findings annotated for degree of information change.
After testing and benchmarking the model, Isabelle focussed on three research questions.
- Do findings reported by different types of outlet express different degrees of information change from their respective papers?
The answer is “yes”. Press releases and outlets focussing on science and technology are fairly similar when it comes to how much information they change. However, general outlets change the information a lot more. - Do different types of social media users systematically vary in information change when discussing scientific findings?
One of the findings was that organisational accounts are more likely to be faithful to the original information, whereas verified accounts are more likely to change the information. - Which parts of the paper are most likely to be miscommunicated by the media?
It turns out that the limitations section is most likely to be misreported. Interestingly, the findings reported in the abstract are generally not changed significantly. This is important to know because most studies on miscommunication only consider the abstract (principally because these are much easier to retrieve). However, studying the abstracts alone is not enough to fully understand the extent of information change.
If you are interested in finding out more about this information change research, you can read the scientific article: Modeling Information Change in Science Communication with Semantically Matched Paraphrases.
Concluding
The code and dataset for this information change work is publicly available, and Isabelle invited the audience to try it out. You can find everything you need at this webpage.
In terms of future work, Isabelle hopes that this model and dataset can be applied to other downstream tasks. For example, a) measuring selective reporting of findings, b) investigating which factors affect the scientific findings that journalists choose to cover, or c) the generation of faithful summaries of scientific articles. She is also keen to investigate other types of information change and how and when this occurs throughout the science communication process. The end goal is a taxonomy of information change.
tags: AAAI, AAAI2023

AUAI is supported by:








