
ΑΙhub.org
Learning personalized reward functions with Interaction-Grounded Learning (IGL)
Rewards play a crucial role in reinforcement learning (RL). A good choice of reward function motivates an agent to explore and learn which actions are valuable. The feedback that an agent receives via rewards allows them to update their behavior and learn useful policies. However, designing reward functions is complicated and cumbersome, even for domain experts. Automatically inferring a reward function is more desirable for end-users interacting with a system. As an example, ChatGPT uses Reinforcement Learning with Human Feedback (RLHF) to learn a reward function. It leverages explicit human feedback to better align dialogue responses with those preferred by people.
 Users can help ChatGPT improve by providing explicit thumbs up/down feedback
Users can help ChatGPT improve by providing explicit thumbs up/down feedback
The recent Interaction-Grounded Learning (IGL) paradigm [11,12] is another way to infer reward functions that capture the intent of an end-user. In the IGL setting, an agent infers a reward function via the interaction process itself, leveraging arbitrary feedback signals instead of explicit numeric rewards. Although there is no explicit reward signal, the feedback is dependent on the latent reward. The agent must learn a policy to maximize the unobserved latent reward by using the environment’s feedback.
How can an agent possibly succeed in the challenging environment of IGL? We demonstrate using the following toy problem.
Toy problem: what does Lassie like?
You adopted a new dog, Lassie! As Lassie settles into her new home, you want to make sure she is happy and comfortable. Unfortunately, you cannot directly ask Lassie whether or not she likes kibble or snow or your neighbor’s loud lawnmower. What you can do is observe her reactions to these stimuli. Based on the reaction, you can make an educated guess about her experienced reward.
Or, rather than guess, you can use IGL to learn Lassie’s preferences. IGL requires two criteria to succeed: (1) rare rewards and (2) consistent communication. The rare rewards requirement states that if you choose actions at random, it is unlikely for Lassie to like them. If Lassie were consistently happy with your random actions, then there wouldn’t be much to learn! To satisfy the consistent communication requirement, Lassie’s feedback should depend on her latent reward. It would be impossible to learn Lassie’s preferences if she randomly barked both when happy and not.
These two requirements guarantee that the feedback associated with the latent reward will be rarely observed. IGL is then able to learn which actions result in rarely observed feedback signals. This is done by learning a reward decoder as well as an optimal action policy. The reward decoder associates each feedback signal with a latent reward state and this inferred latent reward is then used in the objective for the optimal action policy.
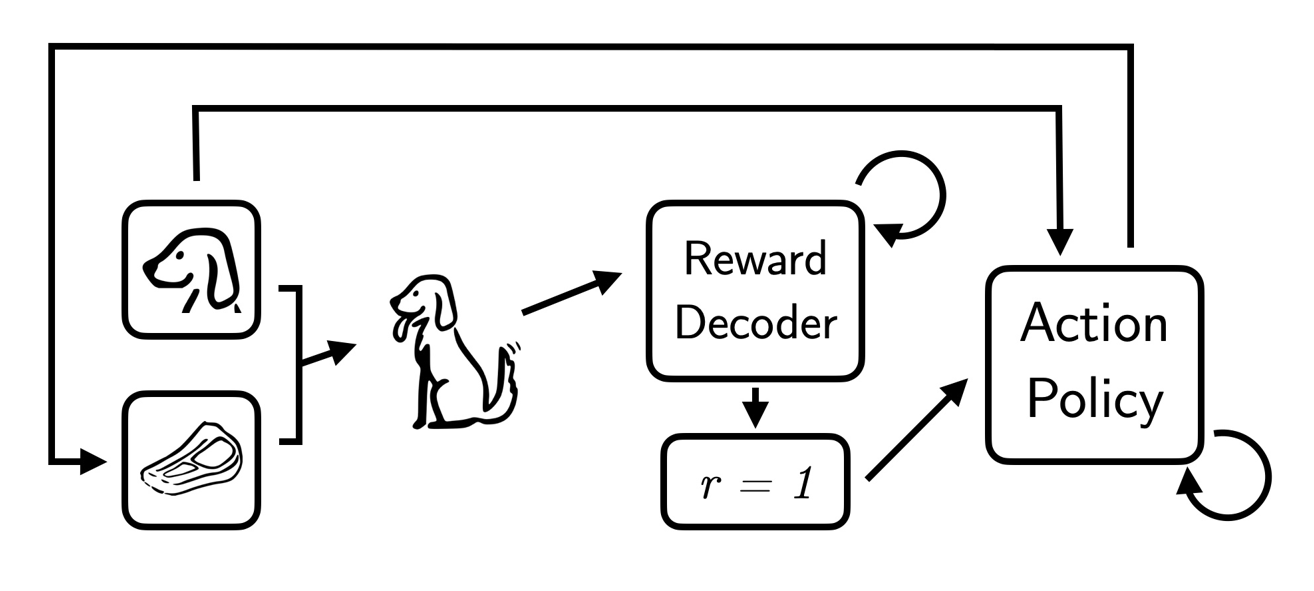
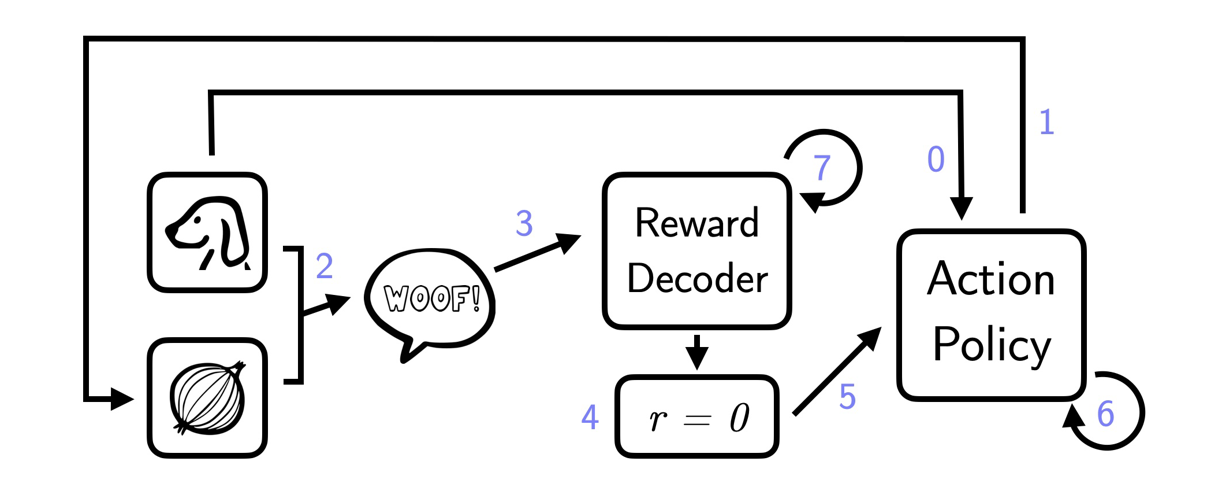 Flowchart demonstrating how IGL optimizes for the latent reward. The action policy observes the context and predicts which available action will maximize the latent reward. Next, the environment emits a feedback signal in response to the action. The reward decoder infers what the latent reward is and passes the value to the action policy which updates accordingly. Since Lassie barks frequently, barking is associated with the r=0 latent state. The action policy then learns that Lassie does not like onions.
Flowchart demonstrating how IGL optimizes for the latent reward. The action policy observes the context and predicts which available action will maximize the latent reward. Next, the environment emits a feedback signal in response to the action. The reward decoder infers what the latent reward is and passes the value to the action policy which updates accordingly. Since Lassie barks frequently, barking is associated with the r=0 latent state. The action policy then learns that Lassie does not like onions.
Our contributions: IGL-P
Our work [3,4] expands on the literature of IGL. Previous work on IGL assumed that rewards were either 0 or 1 — Lassie is either unhappy or happy respectively. This assumption has disastrous consequences if there are rarely-seen undesirable states. For example, if Lassie is scared of your neighbor’s lawn mower, a two latent state model would interpret her rare shaking as a positive feedback signal and seek to maximize that type of feedback. To fix this problem, we introduced a ternary latent model. Our algorithm IGL-P uses three latent states and partially labeled examples to disambiguate extreme positive and extreme negative feedback signals.
IGL-P also allows for personalized reward learning. If you adopt a cat Garfield that communicates differently than Lassie, the variation in communication styles will not prevent you from learning what each pet prefers using IGL-P. Our algorithm personalizes by learning which feedback signals are rare depending on the context (are you interacting with Lassie or Garfield?). The personalization of IGL-P requires no additional computation. In comparison, traditional reward engineering for different contexts requires extensive study and modeling [2].
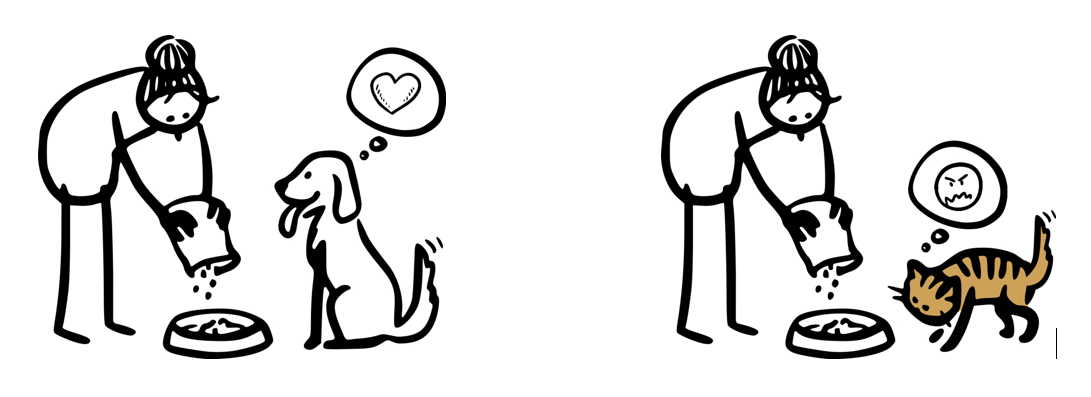 Lassie the dog wags her tail to communicate her excitement for dinner! Garfield the cat wags his tail to communicate his outrage at being served kibble rather than lasagna…
Lassie the dog wags her tail to communicate her excitement for dinner! Garfield the cat wags his tail to communicate his outrage at being served kibble rather than lasagna…
IGL-P for recommender systems: a success story
Recommender systems are a natural candidate for IGL-P due to the data sparsity challenge (when was the last time you rated a movie on Netflix?). Without explicit feedback, recommender systems cannot know for certain whether a user enjoyed the displayed content or not. Implicit signals such as clicks or dwell time are typically used as a proxy for user satisfaction. However no one choice of implicit signal is the true latent reward signal. Even the click through rate (CTR) metric, the gold standard for recommender systems, is an imperfect reward and its optimization naturally promotes clickbait. Current state-of-the-art solutions are costly and either rely on extensive user modeling [10] or meticulously hand-tuned reward signals [6].
The choice of reward function is further complicated by differences in how different types of users interact with recommender systems. A growing body of work shows that recommender systems do not provide consistent performance across demographic subgroups, and that this unfairness has its roots in user engagement styles [7]. In other words, a reward function that might work well for one type of user might (and often does) perform poorly for another type.
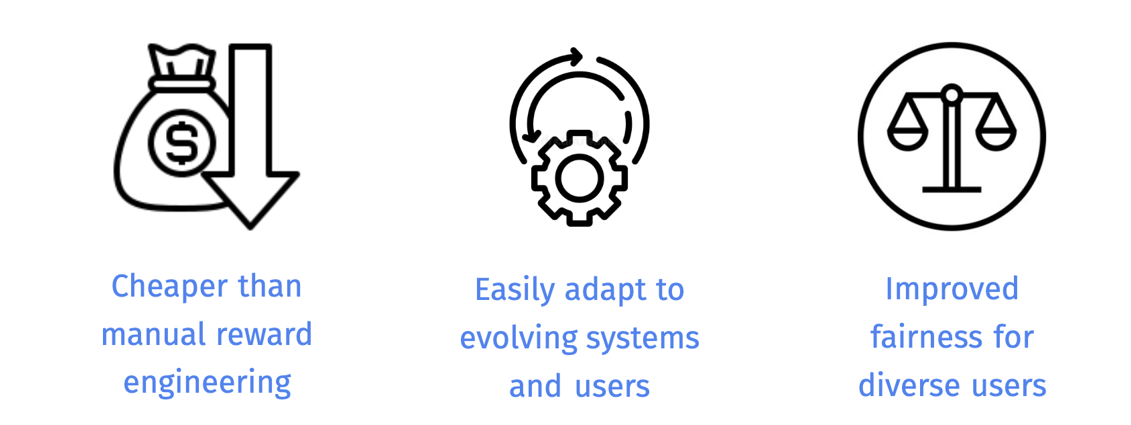 Benefits of IGL-P for recommender systems
Benefits of IGL-P for recommender systems
Our paper “Personalized Reward Learning with Interaction-Grounded Learning (IGL),” to appear at ICLR 2023, demonstrates that IGL-P can successfully solve the challenges of expensive reward engineering and unfair performance in real-world settings. First, we demonstrate that IGL-P is able to outperform the state-of-the-art in an image recommendation scenario for Microsoft. The state-of-the-art policy is trained using a hand-engineered reward function that is non-intuitive and the result of costly trial and error research over many years by product engineers and data scientists. Using large-scale experiments, we show that IGL-P can achieve just as much desirable feedback as the current production policy and fewer negative feedback signals. In other words, IGL-P eliminates the need for hand-engineering of reward functions.
For the second experiment, we consider a Facebook news recommendation scenario. We use a large real-world dataset [5] that demonstrates readers of different Facebook news pages signal preferences using different click-based emoji reactions. We demonstrate that previous iterations of Facebook’s reward function [6] offer disproportionately better recommendations to some types of readers at the cost of other types. However IGL-P is able to learn tailored reward functions for different reader types and consequently provide consistently good recommendations across all user types. Our results demonstrate that IGL-P provides improved fairness for diverse users.
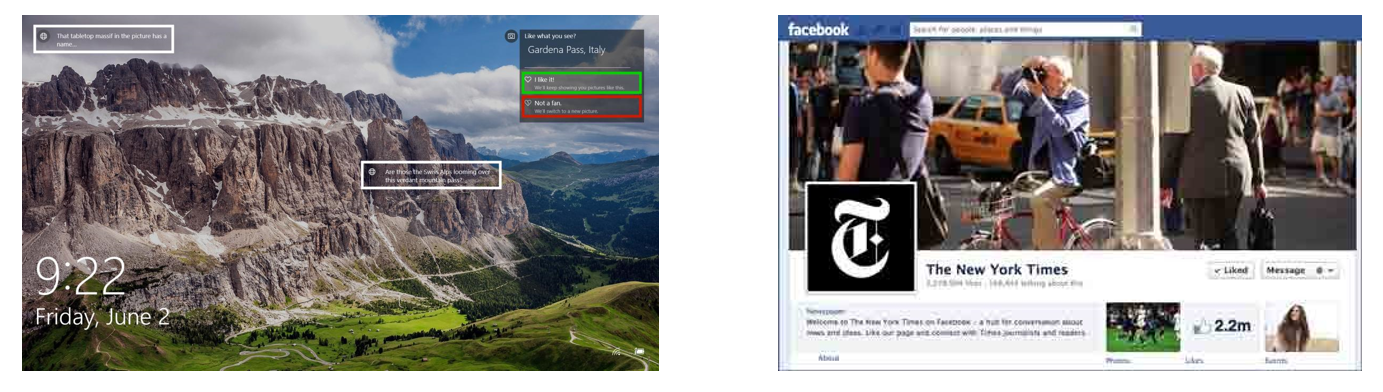 IGL-P succeeds in two real-world recommendation scenarios: (1) image recommendation for Windows users and (2) news recommendation for Facebook readers
IGL-P succeeds in two real-world recommendation scenarios: (1) image recommendation for Windows users and (2) news recommendation for Facebook readers
Personalized reward learning beyond recommender systems
Although we consider the application of recommender systems, personalized reward learning can benefit any application suffering from a one-size-fits-all approach. For instance, chatbots rely on interactive user feedback to calibrate their performance and self-improve. However different users may provide varying types of biased feedback. IGL-P can be used to adjust for user idiosyncrasies so that conversational agents do not overcorrect when incorporating human feedback. Personalized reward learning also has great potential for human-machine interfaces. Technologies such as gaze-assisted tools can utilize IGL-P for self-calibrating eye trackers that adapt [9] to the needs of the user. Finally, personalized reward learning can provide improved fairness for applications such as automated resume screening [8] and consumer lending [1].
![]() IGL-P can enable powerful adaptive interfaces for ability based design [image source: Tobii Dynavox UK].
IGL-P can enable powerful adaptive interfaces for ability based design [image source: Tobii Dynavox UK].
References
[1] Will Dobbie, Andres Liberman, Daniel Paravisini, and Vikram Pathania. Measuring bias in consumer lending. The Review of Economic Studies, 2021.
[2] Bruce Ferwerda and Markus Schedl. Personality-based user modeling for music recommender systems. In Machine Learning and Knowledge Discovery in Databases: European Conference, 2016.
[3] Jessica Maghakian, Kishan Panaganti, Paul Mineiro, Akanksha Saran, and Cheng Tan. Interaction-grounded learning for recommender systems. In ACM Conference Series on Recommender Systems. 2022.
[4] Jessica Maghakian, Paul Mineiro, Kishan Panaganti, Mark Rucker, Akanksha Saran, and Cheng Tan. Personalized Reward Learning with Interaction-Grounded Learning (IGL). In International Conference on Learning Representations. 2023.
[5] Patrick Martinchek. 2012-2016 Facebook Posts, 2016.
[6] Jeremy Merrill and Will Oremus. Five points for anger, one for a ‘like’: How facebook’s formula fostered rage and misinformation. The Washington Post, 2021.
[7] Nicola Neophytou, Bhaskar Mitra, and Catherine Stinson. Revisiting popularity and demographic biases in recommender evaluation and effectiveness. In European Conference on Information Retrieval, 2022.
[8] Prasanna Parasurama and Joao Sedoc. Gendered information in resumes and its role in algorithmic and human hiring bias. In Academy of Management Proceedings, 2022.
[9] Jacob Wobbrock, Shaun Kane, Krzysztof Gajos, Susumu Harada and Jon Froehlich. Ability-Based Design: Concept, Principles and Examples. In ACM Transactions on Accessible Computing, 2011.
[10] Chuhan Wu, Fangzhao Wu, Tao Qi and Yongfeng Huang. User Modeling with Click Preference and Reading Satisfaction for News Recommendation. In International Joint Conference on Artificial Intelligence, 2020.
[11] Tengyang Xie, John Langford, Paul Mineiro, and Ida Momennejad. Interaction-Grounded Learning. In International Conference on Machine Learning, 2021.
[12] Tengyang Xie, Akanksha Saran, Dylan J Foster, Lekan Molu, Ida Momennejad, Nan Jiang, Paul Mineiro, and John Langford. Interaction-Grounded Learning with Action-inclusive Feedback. In Conference on Neural Information Processing Systems, 2022.
Acknowledgments
This work is based upon work supported by the National Science Foundation under Grant No. 1650114. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.


AUAI is supported by:








