
ΑΙhub.org
Interview with Haotian Xue: learning intuitive physics from videos
 Visual intuitive physics grounded in 3D space.
Visual intuitive physics grounded in 3D space.
In their work 3D-IntPhys: Towards More Generalized 3D-grounded Visual Intuitive Physics under Challenging Scenes, Haotian Xue, Antonio Torralba, Joshua Tenenbaum, Daniel Yamins, Yunzhu Li and Hsiao-Yu Tung present a framework for learning 3D-grounded visual intuitive physics models from videos of complex scenes with fluids. In this interview, Haotian tells us about this work and their methodology.
What is the topic of the research in your paper?
Humans have a strong intuition about how a scene can evolve over time under given actions. This type of intuition is commonly referred to as “intuitive physics”, which is a critical ability that allows us to make effective plans to manipulate the scene to achieve desired outcomes without relying on extensive trial and error.
In this paper, we present a framework called 3D-IntPhys which is capable of learning 3D-grounded visual intuitive physics models from videos of complex scenes, which try to enable machines to learn intuitive physics from only visual inputs in explicit 3D space.
Could you tell us about the implications of your research and why it is an interesting area for study?
Visual information serves as the primary medium through which humans interact with and perceive the surrounding world, enabling them to develop an intuitive understanding of their physical environment. Previous research has focused on learning this intuitive physics, but some approaches have been limited to 2D representations or required dense annotations for particle-based 3D intuitive physics. However, with the rapid development of 3D vision, we now have the opportunity to learn intuitive physics in an explicit 3D space.
To leverage these advancements, we propose a novel framework that combines the benefits of recent neural radiance fields with an explicit 3D dynamics learner. This approach allows us to directly learn intuitive physics from videos without the constraints of limited dimensions or heavy annotation requirements. By harnessing the power of explicit 3D representation and the expressiveness of neural radiance fields, our framework opens new avenues for capturing and understanding the complex dynamics of the physical world.
Could you explain your methodology?
Our method is composed of a conditional Neural Radiance Field (NeRF)-style visual frontend and a 3D point-based dynamics prediction backend, using which we can impose strong relational and structural inductive bias to capture the structure of the underlying environment. Unlike existing intuitive point-based dynamics works that rely on the supervision of dense point trajectory from simulators, we relax the requirements and only assume access to multiview RGB images and (imperfect) instance masks acquired using color prior. This enables the proposed model to handle scenarios where accurate point estimation and tracking are hard or impossible.
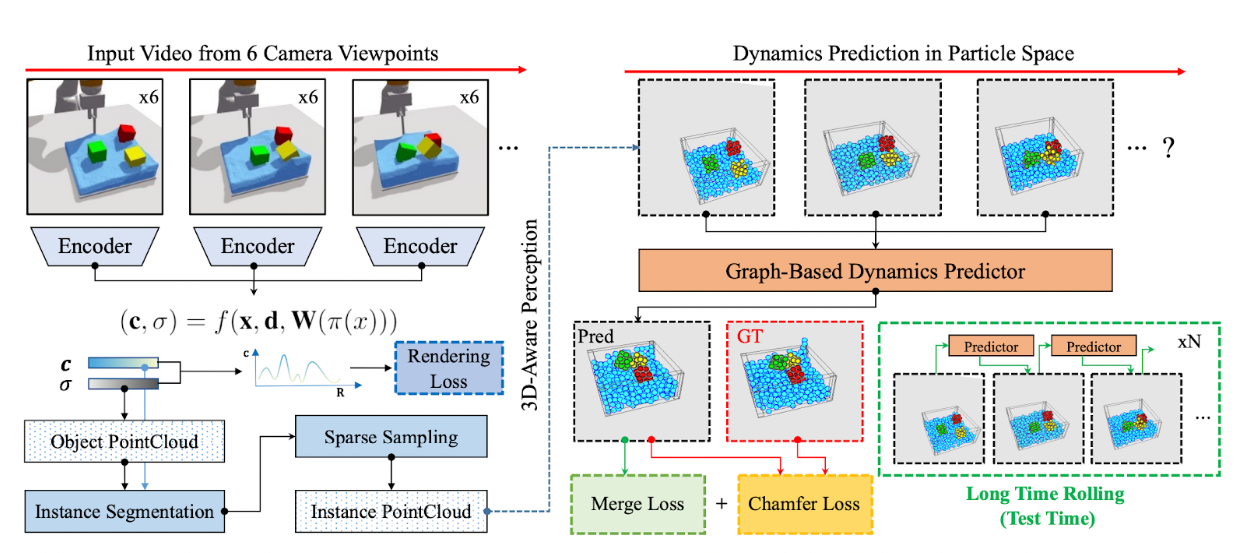 Overview of 3D Visual Intuitive Physics (3D-IntPhys). Our model consists of two major components: Left: The perception module maps the visual observations into implicit neural representations of the environment. We then subsample from the reconstructed implicit volume to obtain a particle representation of the environment. Right: The dynamics module, instantiated as graph neural networks, models the interaction within and between the objects and predicts the evolution of the particle set.
Overview of 3D Visual Intuitive Physics (3D-IntPhys). Our model consists of two major components: Left: The perception module maps the visual observations into implicit neural representations of the environment. We then subsample from the reconstructed implicit volume to obtain a particle representation of the environment. Right: The dynamics module, instantiated as graph neural networks, models the interaction within and between the objects and predicts the evolution of the particle set.
What were your main findings?
We generated datasets including three challenging scenarios involving fluid, granular materials, and rigid objects in the simulation. The datasets do not include any dense particle information so most previous 3D-based intuitive physics pipelines can barely deal with that. We find that 3D-IntPhys can make long-horizon future predictions by learning from raw images and significantly outperforms models that do not employ an explicit 3D representation space. We also find that once trained, 3D-IntPhys can achieve strong generalization in complex scenarios under extrapolate settings.
What further work are you planning in this area?
We are planning to focus on the following two aspects:
1) Learning intuitive physics under more challenging scenes.
2) Learning intuitive physics for transparent objects.
Read the research in full
3D-IntPhys: Towards More Generalized 3D-grounded Visual Intuitive Physics under Challenging Scenes, Haotian Xue, Antonio Torralba, Joshua Tenenbaum, Daniel Yamins, Yunzhu Li and Hsiao-Yu Tung.
About Haotian

|
Haotian Xue is a first-year Ph.D. student at Georgia Tech. He obtained his B.E. in Computer Science from Shanghai Jiao Tong University with honors in 2022. His research interests include aspects of machine learning, computer vision and natural language processing. This work was done when he was a research intern at MIT CSAIL. |

AIhub is supported by:








