
ΑΙhub.org
Interview with Safa Alver: Scalable and robust planning in lifelong reinforcement learning
In their paper Minimal Value-Equivalent Partial Models for Scalable and Robust Planning in Lifelong Reinforcement Learning, Safa Alver and Doina Precup introduced special kinds of models that allow for performing scalable and robust planning in lifelong reinforcement learning scenarios. In this interview, Safa Alver tells us more about this work.
What is the topic of the research in your paper and why it is an interesting area for study?
It has long been argued that in order for reinforcement learning (RL) agents to perform well in lifelong RL (LRL) scenarios (which are scenarios like the ones we, biological agents, encounter in real life), they should be able to learn a model of their environment, which allows for advanced computational abilities such as counterfactual reasoning and fast re-planning. Even though this is a widely accepted view in the community, the question of what kinds of models would be better suited for performing LRL still remains unanswered. As LRL scenarios involve large environments with lots of irrelevant aspects and environments with unexpected distribution shifts, directly applying the ideas developed in the classical model-based RL literature to these scenarios is likely to lead to catastrophic results in building scalable and robust lifelong learning agents. Thus, there is a need to rethink some of the ideas developed in the classical model-based RL literature while developing new concepts and algorithms for performing model-based RL in LRL scenarios.
In this paper, we introduce certain kinds of models that only model the relevant aspects of the agent’s environment, which we call minimal value-equivalent (VE) partial models, and we argue that these models would be better suited for performing model-based RL in LRL scenarios. Overall, both our theoretical and empirical results suggest that minimal VE partial models can provide significant benefits to performing scalable and robust model-based RL in LRL scenarios. Our hope is that studies like ours will bring the RL community a step closer to building model-based RL agents that are effective in LRL scenarios.
What are these minimal VE partial models? Can you be more specific and give a concrete example?
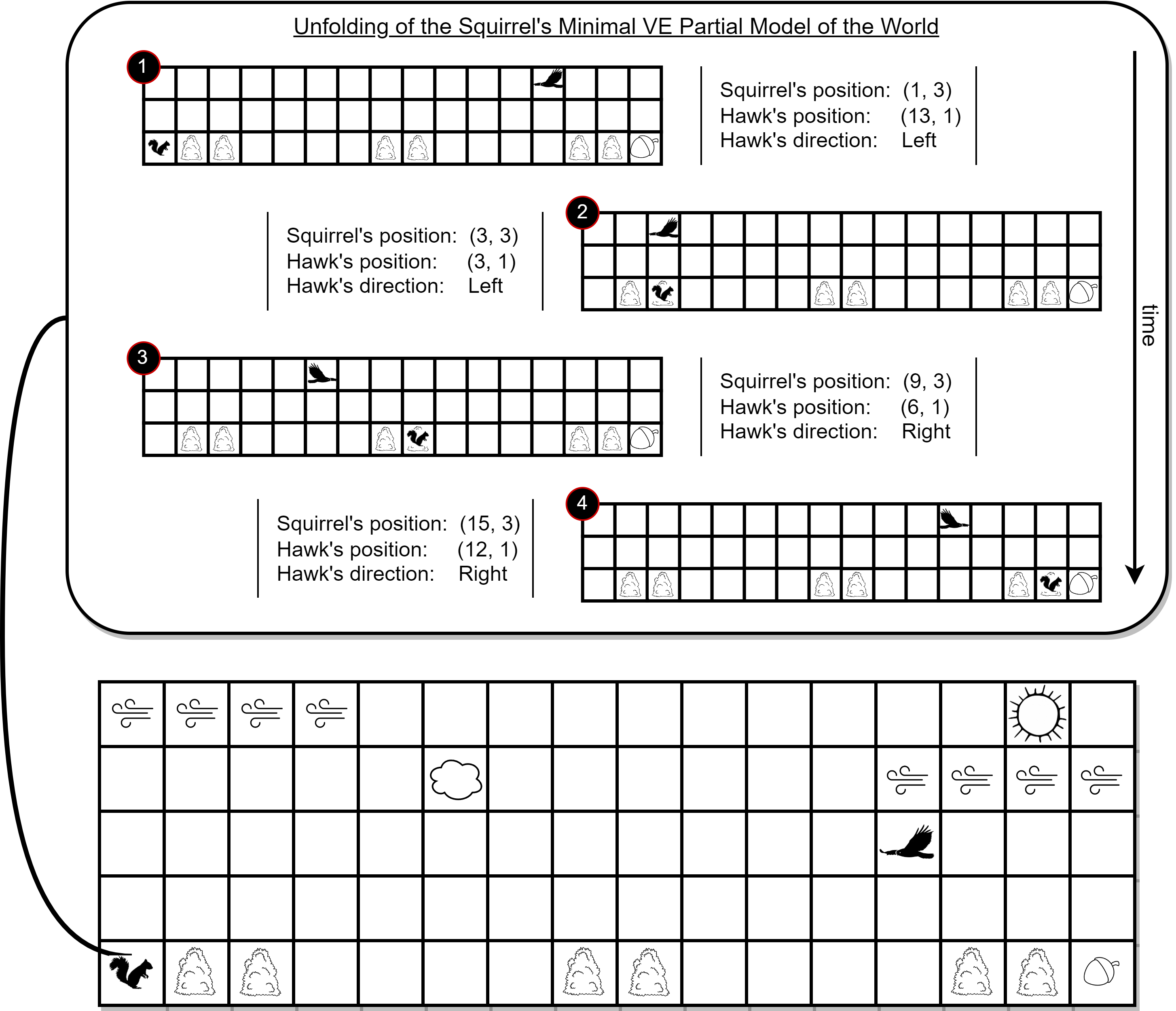
Leaving the technical details aside, we define minimal VE partial models to be models that only model the relevant aspects of the agent’s environment. As an illustrative example, let us start by considering the Squirrel’s World (SW) environment which is depicted in the figure below. Here, the squirrel’s (the agent) job is to navigate from the bottom-left cell to the bottom-right one to pick up the nut, without getting caught by the hawk that flies back and forth above it. At each time step, the squirrel receives as input a 5×16 image of the current state of the environment and then, through the use of its encoder, transforms this image into a feature vector that contains information regarding all aspects of the current state of the environment, i.e., the feature vector contains the following information:
- The current position of the squirrel
- The current position of the hawk
- The current position of the cloud
- The current direction of the hawk
- The current wind direction in the top two rows
- The current weather condition
Based on this, the squirrel selects an action that either moves it to the left or right cell, or keeps its position fixed. If the squirrel gets caught by the hawk, it receives a reward of 0 and the episode terminates, and if the squirrel successfully navigates to the nut, it gets a reward of +10 and the episode terminates. As the hawk moves 5x the speed of the squirrel, a straightforward policy of always moving to the right will not get the squirrel to the nut. Thus, while coming up with decisions, the squirrel would have to take into account both the cells with bushes, which allow for sheltering, and the position and direction of the hawk. In this environment, an example of a minimal VE partial model would be a model that only models the evolution of the three relevant features: (i) the squirrel’s position, (ii) the hawk’s position, and (iii) the hawk’s direction (see the unfolding of such a model in the figure below).
One of the core motivations for this study was to base our models on the models that biological agents use to model the world and achieve tasks within it. From our simple and informal day-to-day models like predicting whether it will rain or not to our sophisticated physics models that predict the instantaneous airflow in different regions of the atmosphere, our models are always built on top of a few relevant aspects of our environments. In this study, we have tried to endow RL agents with similar kinds of models so that they can perform well in LRL scenarios (which mimic real-life scenarios).
Why are these models useful? Can you elaborate through examples?
We argue that minimal VE partial models are useful for at least the following two main reasons:
- They allow for performing scalable model-based RL in large environments with lots of irrelevant aspects, which is typical in LRL scenarios. As an example, consider an agent with a minimal VE partial model and an agent with a regular model (that models every aspect of the environment) in the SW environment. Let us refer to former agent as
 and to the latter one as
and to the latter one as  . As the agent models fewer aspects of the environment, compared to the agent, we would expect it for the agent to take fewer samples in learning an accurate model over its corresponding aspects of the environment, and we would also expect the agent to take fewer planning steps to come up with an optimal (or near-optimal) policy with its learned model.
. As the agent models fewer aspects of the environment, compared to the agent, we would expect it for the agent to take fewer samples in learning an accurate model over its corresponding aspects of the environment, and we would also expect the agent to take fewer planning steps to come up with an optimal (or near-optimal) policy with its learned model. - They allow for performing robust model-based RL in environments with unexpected distribution shifts, which is again typical in LRL scenarios. As an example, let’s again consider the and agents in the SW environment. As the agent only models the relevant aspects of the environment, compared to the agent, we would expect it to be more robust to the distribution shifts happening in the irrelevant aspects of the environment (like the changes in the weather condition, wind directions in the upper atmosphere and positions of the clouds) as it would not be modeling these aspects and thus they would have no effect on the final policy of the agent.
What are the main findings of your study?
Our theoretical results suggest that minimal VE partial models can provide significant advantages in the value and planning losses that are incurred during planning and in the computational and sample complexity of planning. Our empirical results (i) validate our theoretical results and show that these models can scale to large environments, that are typical in LRL, and (ii) show that these models can be robust to distribution shifts and compounding model errors. Overall, our findings suggest that minimal VE partial models can provide significant advantages in performing model-based RL in LRL scenarios.
What further work are you planning in this area?
We are planning to focus on the following two aspects:
- One limitation of our work is that, rather than providing a principled method, we have only provided several heuristics for training deep model-based RL agents so that they can come up with only the relevant features of the environment. However, we note that this is mainly due to the lack of principled approaches in the representation learning literature, and we believe that this limitation can be overcome with more principled approaches being introduced to the literature.
- Another important limitation is that as our main focus was to perform illustrative and controlled experiments, we have only performed experiments in environments where there is just a single task and no sequence of tasks that unfold over time. However, experiments with additional environments that have this sequential task nature can be helpful in further validating the advantages of minimal VE partial models in LRL scenarios, which we also are hoping to tackle in future work. Note that under these scenarios the agent would have to gradually build a set of minimal VE partial models as it faces multiple tasks over its interaction with the environment.
Read the research in full
Minimal Value-Equivalent Partial Models for Scalable and Robust Planning in Lifelong Reinforcement Learning, Safa Alver and Doina Precup.
About Safa
Safa Alver is a Ph.D. candidate at McGill University and Mila who is working with Doina Precup. He obtained an M.Sc. and B.Sc. in Electrical & Electronics Engineering and a B.Sc. in Physics from Middle East Technical University (METU). Broadly, his research focuses on understanding and developing concepts and algorithms to tackle the lifelong reinforcement learning (RL) problem. More recently, he took interest in endowing RL agents with special types of models that allow for efficient and robust planning in lifelong RL scenarios.

AUAI is supported by:








