
ΑΙhub.org
#ECAI2023 outstanding paper: Interview with Xuan Liu – multi-agent sparse reward tasks
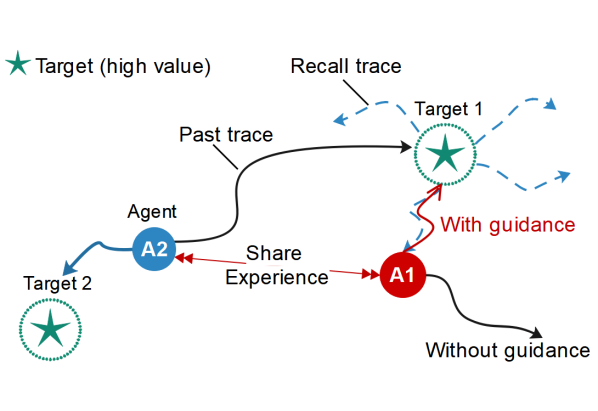 Exploiting high-value experience to provide guidance.
Exploiting high-value experience to provide guidance.
Xuan Liu, and colleagues Xinning Chen, Yanwen Ba, Shigeng Zhang, Bo Ding, Kenli Li, won an outstanding paper award at the 26th European Conference on Artificial Intelligence (ECAI 2023). In this interview, Xuan tells us more about their work.
What is the topic of the research in your paper?
Our paper Selective Learning for Sample-Efficient Training in Multi-Agent Sparse Reward Tasks focuses on improving sample efficiency for multi-agent cooperative tasks with sparse reward. Learning effective polices in multi-agent environments with sparse reward is a great challenge for agents as the concurrent learning of multiple agents induces the non-stationarity problem and sharply increases joint state space. In this paper, we present an effective multi-agent selective learning framework, which selects only valuable experiences of other agents, instead of the whole, huge trajectory space, to accelerate the learning process.
Could you tell us about the implications of your research and why it is an interesting area for study?
The sparse reward problem is one of the core problems of reinforcement learning in solving practical tasks. Recently, successful approaches in reinforcement learning have relied on reward functions that give clear feedback to agents at every step. However, for some complex tasks with sparse reward, such as autonomous driving and robotic control, learning an optimal policy becomes extremely difficult for agents due to the lack of feedback signals. Sparse rewards are delayed, which provide feedback to agents only in a few states, leading to poor sample efficiency. In multi-agent tasks, the sparse reward challenge is aggravated by the need for policy coupling and the non-stationarity of environments.
Previous multi-agent reinforcement learning methods have attempted to promote sample efficiency through experience sharing. However, learning from a large collection of shared experiences is inefficient as there are only a few high-value states in sparse reward tasks, which may instead lead to the curse of dimensionality in large-scale multi-agent systems. In our work, we propose a novel method that improves exploration efficiency and balances learning efficiency with stability simultaneously, which greatly promotes the application of multi-agent reinforcement learning in complex sparse reward tasks.
Could you explain your methodology?
The key idea of our method is to selectively reuse valuable experiences to accelerate the learning process. Our method adopts a centralized training and decentralized execution paradigm. First, to improve sample efficiency in sparse reward tasks, we introduce a centralized backtracking model, which consists of an observation generator and an action generator. The backtracking model generates recall traces from high-value samples. Each agent not only speeds up learning by imitating its own recall traces, but also shares the traces with other agents for aiding effective exploration. Second, we introduce a selector to select K agents’ information based on the correlation between agent observations, which effectively mitigates the non-stationarity of the multi-agent environments and enhances the scalability of our approach in scenarios with more agents. Moreover, considering that it is difficult to identify high-value experiences when all agents obtain a shared team reward, we specifically consider the fully cooperative setting with shared team reward and design a retrogression-based selection method to overcome the difficulty of recognizing contributors from the shared reward.
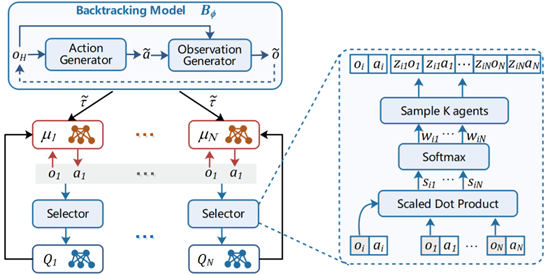 Multi-agent selective learning framework.
Multi-agent selective learning framework.
What were your main findings?
By evaluating our method in several multi-agent cooperative tasks with sparse reward, we found that our method significantly improves sample efficiency for sparse reward tasks, especially in tasks with large-scale agents. We also found that our method has broad applicability to multi-agent tasks with different reward settings.
What further work are you planning in this area?
Sparse rewards remain an ongoing challenge. In the future, we will explore the issue of sparse rewards in more intricate multi-agent environments. Our attention will be directed towards optimizing the utilization of valuable experiences and identifying the interaction relationship between agents in diverse environments.
About Xuan Liu

|
Xuan Liu (Member, IEEE) is currently a Professor in the College of Computer Science and Electronic Engineering at Hunan University, China. She received a MSc from National University of Defense Technology, and a PhD from Hong Kong Polytechnic University. Her research interests include multi-agent reinforcement learning and its applications, and Internet of Things. |
Read the work in full
Selective Learning for Sample-Efficient Training in Multi-Agent Sparse Reward Tasks, Xinning Chen, Xuan Liu, Yanwen Ba, Shigeng Zhang, Bo Ding, Kenli Li.
tags: ECAI2023

AUAI is supported by:








