
ΑΙhub.org
Pre-trained language models for music captioning and query response
Do you ever find yourself captivated by a song but struggling to put into words what makes it so special? Have you ever wanted to identify the instrument or genre of a piece of music but found yourself at a loss? Perhaps you’ve tried to search for a particular song through text, only to hit a dead end in your quest. In the world of music information retrieval, the tasks of transcribing music scores and retrieving music based on its characteristics are critical areas of research and advanced techniques may help you sometimes. However, for everyday music enthusiasts without formal training, achieving these goals in pre-defined scientific terms can often feel elusive. Instead, you may be searching for answers through natural language-generated tags or questions. This is where MusiLingo comes into play. Imagine having a system that can automatically provide descriptions for the evocative music featured in videos, catering to the needs of the hearing-impaired, or enhancing the search and discovery of musical material for composers through user-friendly queries.
Several models and systems have made strides in the intersection of music and language before MusiLingo. For example, MusCaps leverages convolutional networks and recurrent neural networks for music captioning. MuLan uses contrastive learning to align text and audio embeddings. LP-MusicCaps and ACT employ cross-modality transformer-based encoder-decoder architectures for music/audio captioning. While these models have pushed the boundaries of music captioning, they still have room for improvement when it comes to functioning within a genuine conversational context for question-answering. Inspired by the success of vision-language pre-training, my colleagues and I connected pre-trained music encoders with large language models (LLMs) via a learnable interface for a better performance.
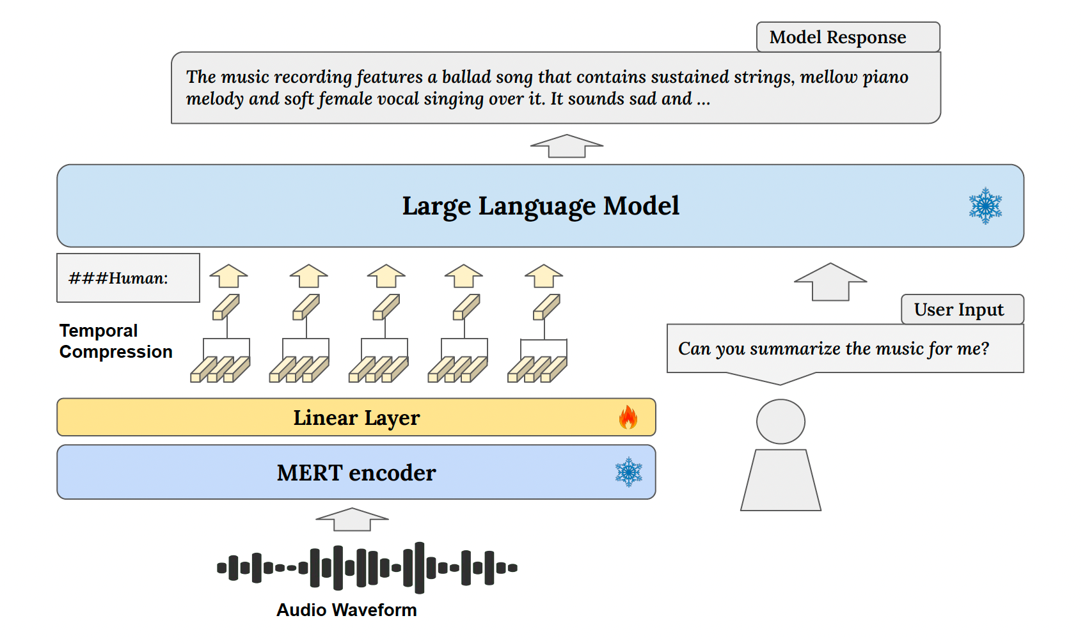
MusiLingo consists of two parts, MERT, a pre-trained model used to interpret the music as an ear, and Vicuna, a pre-trained model of natural language which is capable of captioning and Q&A. More specifically, MusiLingo’s architecture revolves around a single projection layer configuration with temporal compression applied to music embeddings. Unlike some other models that project music embeddings to higher layers, MusiLingo’s simpler projection sends the embedding to the beginning layer of the LLM. This unique approach, combined with a pre-training phase to align music and textual representations, equips MusiLingo with the ability to understand various aspects of musical compositions and provide accurate and natural responses to user queries.
To train our model, we developed a MusicInstruct Dataset, a new dataset featuring 60,493 Q&A pairs, covering general questions about music and specific inquiries related to music genres, moods, tempo, and instruments etc. After finetuning on query response datasets, MusiLingo demonstrates state-of-the-art performance on multiple scenarios: short and objective questions in MusicInstruct, and long and subjective questions in MusicInstruct and MusicQA datasets.
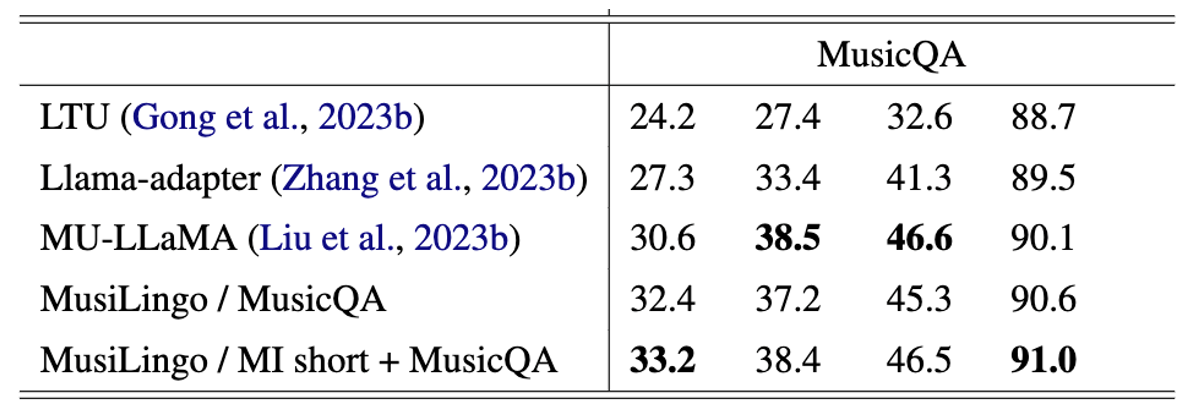
Across these scenarios, we evaluated the performance based on three rule-based evaluation criteria for traditional text generation: Bleu-Uni (B-U), METEOR-Rouge (M-R), and ROUGE-L (R-L), as well as the widely recognised BERT-Score (BERT-S) criterion. The traditional metrics calculate the word alignment between generated text and reference text, and BERT-Score computes token similarity in texts using contextual embeddings instead of exact matches. On the query response performance on MusicQA dataset, MusiLingo emerges as the top performer, displaying the highest overall performance. Specifically, our model excels in B-U and BERT-S metrics, surpassing state-of-the-art methods. These results confirm MusiLingo’s effectiveness in tackling the complexities of music question-answering. Moreover, MusiLingo shines in the MI datasets, handling both short objective questions and long subjective questions. In the objective question scenario, it achieves the highest scores in all rule-based evaluation criteria, outperforming other audio Q&A models. For long-form music instructions, MusiLingo also outperforms other models. These results demonstrate MusiLingo’s versatility, robustness, and ability to handle complex and diverse music-related queries. Besides, it can also provide competitive results for music captioning.
While MusiLingo is a significant step forward, it’s essential to acknowledge its limitations. The fine-tuning process is relatively brief, leaving room for improvement through more extensive training and exploration of hyperparameter configurations. Additionally, the model’s universality on all downstream Q&A datasets is an area for future research. Furthermore, there may be instances where the model generates responses that don’t align perfectly with human interpretations of music, especially for subjective descriptions based on the input music. These challenges are recognized and seen as opportunities for further refinement.
Find out more
- Our paper: MusiLingo: Bridging Music and Text with Pre-trained Language Models for Music Captioning and Query Response, Zihao Deng, Yinghao Ma, Yudong Liu, Rongchen Guo, Ge Zhang, Wenhu Chen, Wenhao Huang, Emmanouil Benetos.
- Our code
tags: Invited post

AUAI is supported by:








