
ΑΙhub.org
The power of collaboration: power grid control with multi-agent reinforcement learning

In our rapidly evolving world, effectively managing power grids has become increasingly challenging, primarily due to rising penetration of renewable energy sources and the growing energy demand. While renewable sources like wind and solar power are crucial on our path towards a 100% clean energy future, they introduce considerable uncertainty in power systems, thereby challenging conventional control strategies.
Transmission line congestions are often mitigated using redispatch actions, which entail adjusting the power output of various controllable generators in the network. However, these actions are costly and may not fully resolve all issues. Adaptively changing the network using topological actions, such as line switching and bus switching, is an under-utilized yet very cost-effective strategy for network operators facing rapidly shifting energy patterns and contingencies.
To navigate the complex and large combinatorial space of all topological actions, we propose a Hierarchical Multi-Agent Reinforcement Learning (MARL) framework in our paper “Multi-Agent Reinforcement Learning for Power Grid Topology Optimization” [1] (a preprint submitted to PSCC 2024). This framework leverages the power grid’s inherent hierarchical nature. The inherent scalability of this approach makes it a promising AI tool for assisting network operators in their real-time decision-making and operations.
The challenge: a complex network and combinatorial huge action space
The Learning to run a power network (L2RPN) challenge [2] initiated in 2019 pushed researchers to explore reinforcement learning (RL) control strategies for power network operations. The challenge provided an open-source framework, Grid2Op [3], that simulates real-world power grids and is designed for testing sequential decision-making in power systems. The aim of the L2RPN challenge was to ensure a safe power network by avoiding line contingencies and ensuring constant connectivity.
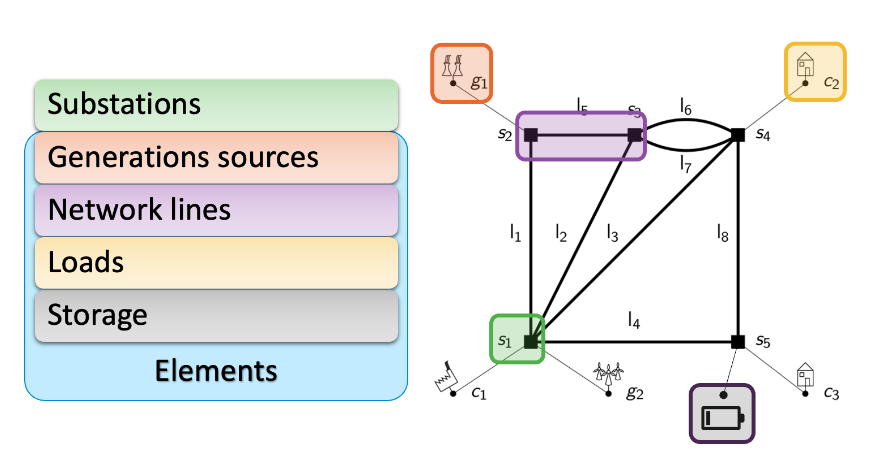
The power network is modelled as a graph where nodes represent substations and edges denote transmission lines. Substations can connect various elements like generators, loads, and storage units. See the figure above for an example of a visual representation of the power network as a graph.
Utilizing the Grid2Op framework, the problem is well suited for RL. In this setup, we design the agent to play the role of a network operator, and the network operation problem itself serves as the environment (this is integrated into Grid2Op). For a visual representation of how the agent interacts within the Grid2Op environment, refer to the figure below.
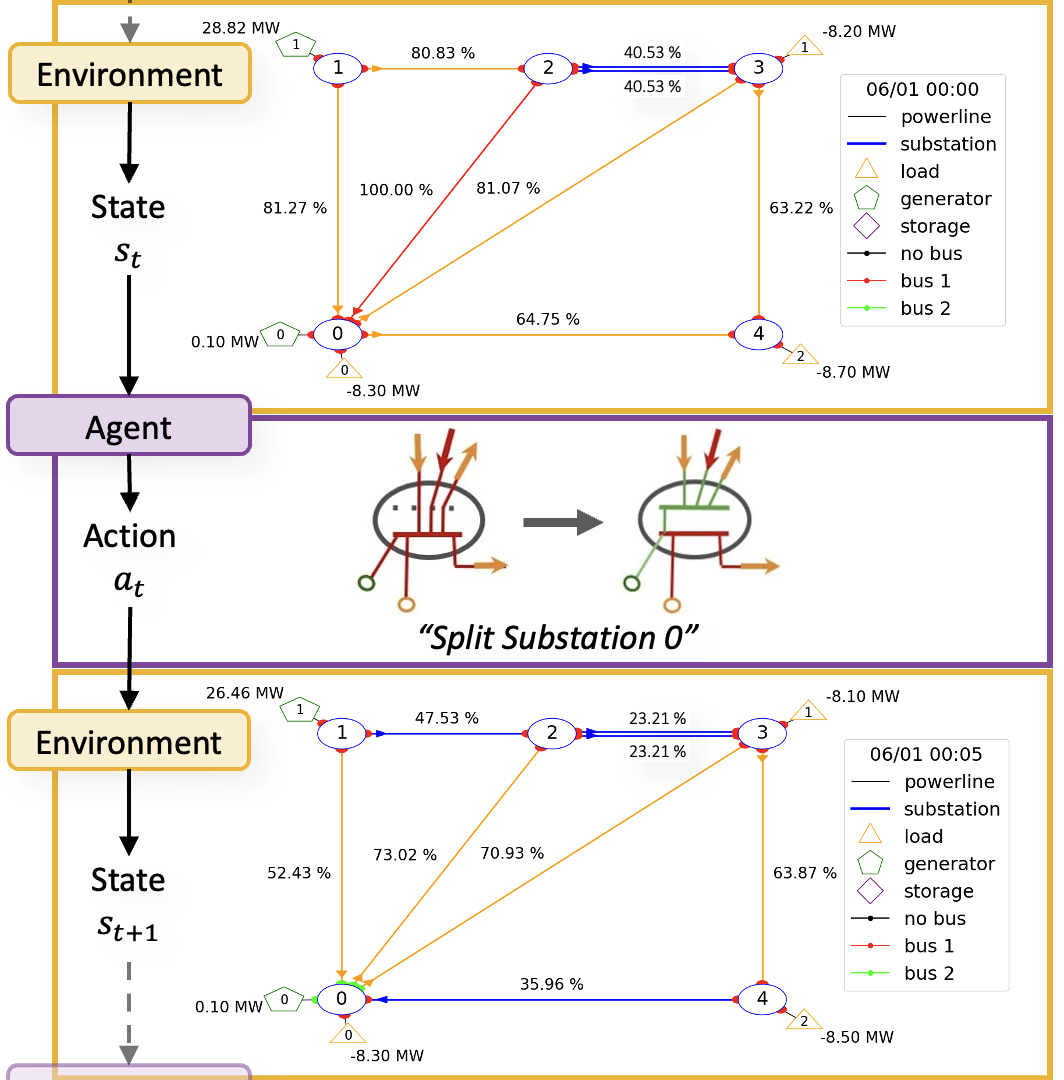
The actions available for the agent to deal with congestions in the network are:
- Switching of lines: With this action, a transmission line can be switched off when needed for maintenance, protection, or power flow management. If already disconnected, a line can be reconnected.
- Splitting buses: A topologically more complex action that can take place within each substation, inside which there are two buses. Initially, each element is connected to the same bus within the substation. ‘Bus splitting’ involves moving one or more elements to the other bus, essentially this can be seen as creating a new node in the network as shown in the figure below.
- Generator redispatch or curtailment: This action entails increasing or decreasing production at a generator. This action is more costly.
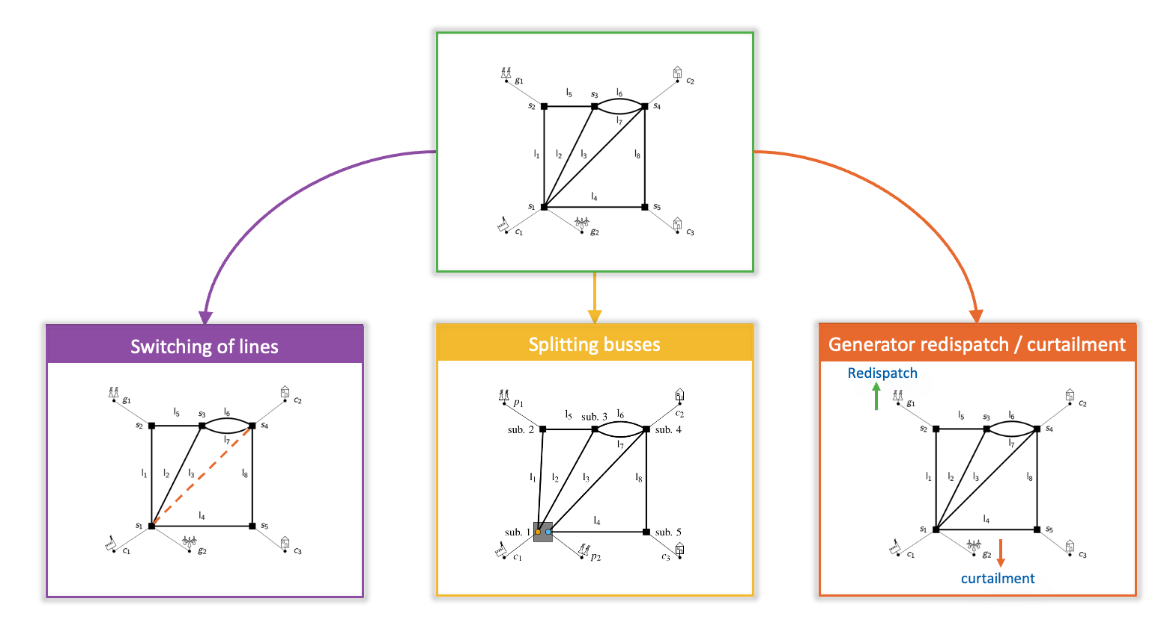
The topological key actions, such as line-switching and bus-splitting, must be optimized for maximum efficiency. However, as networks grow, the action space becomes vast, necessitating innovative strategies to navigate this complex decision-making landscape.
A potential solution: Hierarchical Multi-Agent Reinforcement Learning
Traditional RL approaches face scalability challenges in dealing with combinatorially large action spaces, such as those resulting from topological actions. To address this, we introduce a new Hierarchical Multi-Agent Reinforcement Learning (MARL) approach, tailored to tackle the expansive action spaces within power grids, embracing the inherent hierarchical structure of power grids. This approach distributes tasks among multiple RL agents per substation, effectively reducing the action space per agent, enhancing scalability, and enabling seamless integration of actions such as generator redispatching.
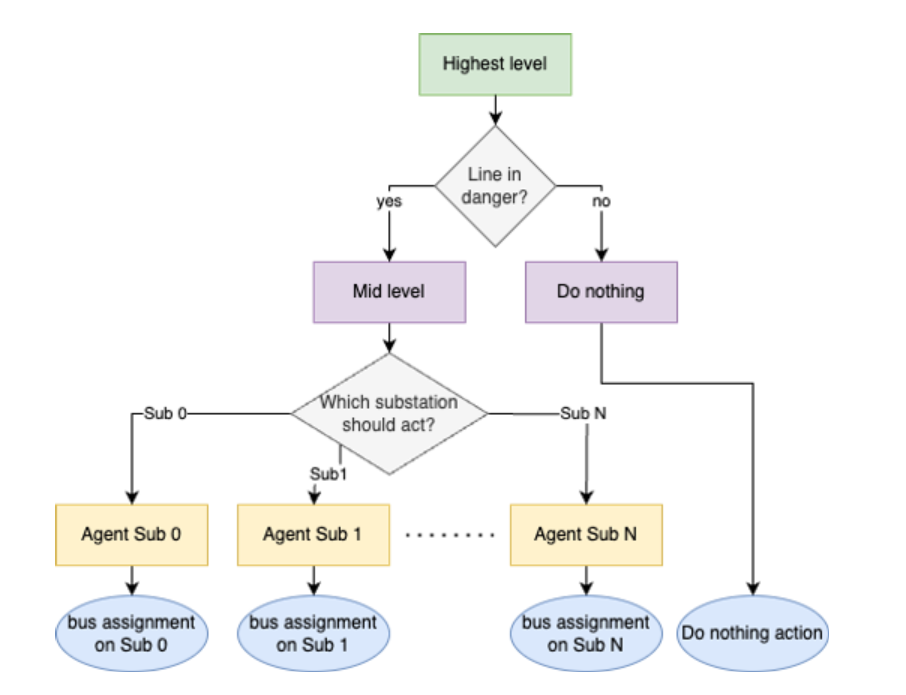
In the proposed hierarchical MARL framework, decisions are categorized into three levels, as shown in the figure above. At the highest level, a single agent determines whether action is needed, often choosing to remain passive in safe environments. The mid level consists of a single agent that selects the substations requiring action, prioritizing based on network conditions. The lowest level features substation-specific agents, each responsible for selecting bus assignments for their substation’s elements. This hierarchical architecture mirrors the tiers of decision-making present in power network control, aligning seamlessly with the domain’s inherent structure.
Independent vs. collaborative MARL approaches
In the realm of MARL, two fundamental strategies are at play: independent and dependent agents. Independent agents operate in isolation, treating other agents as part of the environment. This approach offers simplicity but introduces non-stationarity within the environment, causing an unstable learning process. On the other hand, dependent agents collaborate, share information, and work cohesively to craft effective multi-agent policies. However, handling the dependencies among agents can introduce computational challenges. Our paper embraces the Centralized Training with Decentralized Execution (CTDE) paradigm for dependent agents, balancing global information during training with localized decisions during execution.
To put these ideas into practice, we explore two powerful RL variants: Soft Actor-Critic Discrete [3] (SACD) and Proximal Policy Optimization [4] (PPO), resulting in four distinct MARL strategies.
- Independent agents SACD (ISACD);
- Independent agents PPO (IPPO);
- Dependent agents SACD (DSACD);
- Dependent agents PPO (DPPO).
We applied hyperparameter tuning to improve the performance of the MARL algorithms. The results show that indeed different hyperparameters need to be used for MARL compared to single agent RL. Furthermore, adding dependent learners to the model significantly improves the agent scores and stability compared to independent learners.
These MARL strategies bring fresh perspectives to power grid management and demonstrate that they are able to achieve optimal scores while navigating the challenging terrain of power grid topology optimization.
Our paper opens up numerous possibilities for future research and development. While the current focus is on a smaller-scale power grid, the strategies explored can be extended to more extensive networks, showcasing the true potential of MARL in power grid management. Future work aims to fine-tune policies, address inter-level dependencies, and expand experiments.
References
[1] Multi-Agent Reinforcement Learning for Power Grid Topology Optimization, E. van der Sar, A. Zocca, S. Bhulai, arXiv:2310.02605 (2023).
[2] Learning to run a power network challenge for training topology controllers, A. Marot, B. Donnot, C. Romero, B. Donon, M. Lerousseau, L. Veyrin- Forrer, I. Guyon, Electr. Power Syst. Res. 189 (2020) 106635.
[3] Grid2op 1.9.4 documentation
[4] Soft actor-critic for discrete action settings, P. Christodoulou, arXiv:1910.07207 (2019).
[5] Proximal policy optimization algorithms, J. Schulman, F. Wolski, P. Dhariwal, A. Radford, O. Klimov, arXiv:1707.06347 (2017).



AUAI is supported by:








