
ΑΙhub.org
Interview with Célian Ringwald: Natural language processing and knowledge graphs

The AAAI/SIGAI Doctoral Consortium provides an opportunity for a group of PhD students to discuss and explore their research interests and career objectives in an interdisciplinary workshop together with a panel of established researchers. This year, 30 students have been selected for this programme, and we’ll be hearing from them over the course of the next few months. In this interview, Célian Ringwald, tells us about his work on natural language processing and knowledge graphs.
Tell us a bit about your PhD – where are you studying, and what is the topic of your research?
I am a PhD student at the Université Côte d’Azur in Inria, the French Institute in Research in AI. I am part of the Wimmics team, a research group bridging formal semantics and social semantics on the web.
My research topic is at the crossroads of two scientific domains: Natural language processing (NLP) and knowledge graphs (KGs). I am working on methods allowing the extraction of targeted information from texts. For that purpose, I adapt pre-trained generative models to extract a small graph of relations from a Wikipedia text. Dbpedia/Wikidata are the most famous knowledge graphs and they are built on the top of Wikipedia. They are huge, they are incomplete, and sometimes inconsistent. Moreover, none of them use the text as a direct source of information.
Could you give us an overview of the research you’ve carried out so far during your PhD?
I am starting my second year of PhD study, the first year was dedicated to understanding the research domain through three aspects: (1) a first contact with the scientific community, (2) a systematic analysis of the literature and (3) the design of an iterative process that I am starting to implement.
I had the opportunity to begin my PhD following two Summer Schools: GEMSS and ISWS. The GEMSS summer school allowed me to meet others and follow training on deep generative AI methods to get familiar with models going beyond transfers. ISWS was also a fantastic and exhausting week of learning within the Semantic Web community, a real adventure that combines talks and group research experiments. It was enjoyable to be part of this because it gave me a new opportunity to work with PhD students from across the world. We wrote together my first workshop paper on an enjoyable question: “Can we generate a representation for a fictional character that hasn’t any pictures on Wikipedia with Wikidata triples?”. This summer school gave me the possibility to participate a month later in a Prompting Hackathon. In my case, we had to work on a multimodal extraction, by benchmarking several models on relation extraction tasks, which is hard to evaluate because these models are trained to answer with sentences and not structured outputs. These two side works aren’t directly related to my PhD topic, but they both feed my thoughts and allow me to collaborate with other PhD students.
Aside from that, as the research community is productive on the topic related to the combination of KGs and LLMs, I spent some time developing a tool to facilitate the writing of a systematic review. This framework allowed me to first underline the surveys and reviews made in my domain, and then to extend it to cited methods and models mentioned in the surveys. I also integrated data coming from Papers with Code that enriches the metadata of the papers collected with useful information related to the datasets, the architecture and their performances. We are working on the last layer of annotation in line with my PhD topic. The use of such a systematic method is, in my opinion, beneficial in analysing and monitoring the research production.
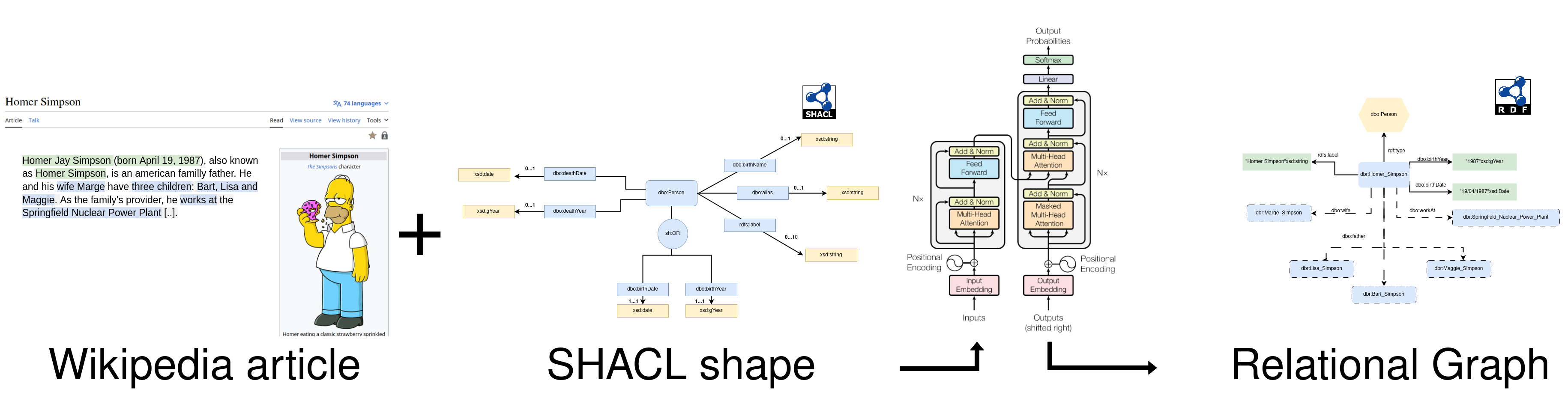
In addition, I also took the time to find a way to divide my research question into smaller sub-questions. Indeed, Wikipedia covers a huge scope of domains and, at the same time, the knowledge graphs built above the encyclopaedia are described by huge ontologies and cover millions of facts. I first chose to focus only the extraction of values: strings, numbers, and dates. For several reasons: the already proposed models don’t insist on these properties, even if they are directly impacted by hallucinations and they don’t need to rely on an entity linkings step. After some early experiments, we decided to restrict the extraction of values that could be found in our text, but also to filter the triples we present in our training set to our model, with a SHACL shape. A SHACL shape represents a graph pattern we want to extract. In our case, we start to focus on person-related relation extraction, our first SHACL shape allows in this context to select only the triples respecting the following constraint: a person must have a birth date. This shape filters our training set but will be integrated as a prompt later.
Once I had my training set I started to conduct several experiments, but I discovered that since today the literature about relation extraction hasn’t investigated the possibility of extracting information by representing triples following Resource Descriptive Framework (RDF) syntaxes proposed by the W3C. Consequently, my first contribution aims to answer the following question: How does the choice of syntax impact the extraction of triples using datatype properties? This is the subject of the student abstract I will present at AAAI.
Is there an aspect of your research that has been particularly interesting?
Firstly, I can say that I like to work in academia and research because it is very varied. You have to experiment, of course, but also write and disseminate your results. It allows me to travel and meet peers and really interesting people. Moreover, in my case, I also have to teach, which is also a really interesting part of my job: students always ask interesting questions that sometimes require deconstructing and re-examining my knowledge.
Concerning my discipline I feel that I have arrived at an exciting era for the research community. LLMs and knowledge bases could be considered two objects deriving from the historical dichotomy in AI: connectionism and symbolism. It’s interesting to be part of this right now because a diversity of disciplines is sitting at the same table today to discuss together what we be neurosymbolic AI.
What made you want to study AI?
I think the first door was opened when my father authorised me to use his computer. I was a teenager and I was passionate and fascinated by the unlimited knowledge I could find on the web. I decided at this time to learn how to program, firstly for creating my website that focused on my comic readings. Later, as I was good at math and statistics, I followed a Bachelor’s degree, convinced that I would enter, after it, the job market. But the first course of data mining amazed me. We had an enthusiastic teacher who was researching bee algorithms. This first contact gave me the desire to continue.
Then I went to Belgium for a Master’s internship where I had the chance to work on my first Textmining software: a tool made for the analysis of big corpora of poetry of famous poets of Liege for editorialisation support. This experiment confirmed my taste for working on NLP. This is the path I chose to follow when I joined DataObserver, a startup specialising in social and media monitoring. As I liked the research aspect of my work, I decided to conduct a second academic curriculum in Digital Humanities in parallel with my job, and then pursue a PhD. It was fantastic to have this occasion to study social sciences applied to IT, it allowed me to approach texts differently. I had the opportunity to be a research assistant at Ottawa, and that was my first serious contact with Linked Open Data, a subject that amazed me, and led me naturally today to my research question.
What advice would you give to someone thinking of doing a PhD in the field?
Before your PhD: allow time for your idea to grow, meet people and let your idea grow with them. I think another important aspect before engaging in that kind of journey is to be sure that you will have the opportunity to discuss weekly your progress and your discoveries.
During the PhD: Take the time to talk and meet people, but also to do something aside from your PhD. This journey is an intense experiment, generally spent far from your family and social habits. Take time to do something else and also meet people out of your work circle.
Could you tell us an interesting (non-AI related) fact about you?
I moved to Nice for my PhD, and it was surprisingly the occasion to meet an instrument that always fascinated me: the diatonic accordion. So for a year, I’ve also been an accordion student in a traditional collective with which I play every weekend at balls. I never expected that a year ago.
About Célian

|
Célian Ringwald is a PhD student at the Université Côte d’Azur in Inria Wimmics team. His research focuses on the combination of large language models with knowledge graphs for relation extraction. He graduated from Université Lyon 2 with a first Master’s degree in Data Science and worked for three years for a startup specialising in NLP applications. Having a strong taste for research, he pursued a second Master’s degree in Digital Humanities, which led him to his PhD topic. He maintains the French DBpedia Chapter and is also editor at Programming Historian. |
tags: AAAI, AAAI Doctoral Consortium, AAAI2024, ACM SIGAI

AUAI is supported by:








