
ΑΙhub.org
Interview with Raffaele Galliera: Deep reinforcement learning for communication networks

The AAAI/SIGAI Doctoral Consortium provides an opportunity for a group of PhD students to discuss and explore their research interests and career objectives in an interdisciplinary workshop together with a panel of established researchers. This year, 30 students were selected for this programme, and we’ve been meeting them and talking about their research. In this interview, Raffaele Galliera, tells us about his work on deep reinforcement learning for communication networks.
Could you give us a quick introduction – where are you studying and what’s the main topic of your research?
My name is Raffaele Galliera and I’m a PhD student in the Intelligent Systems and Robotics program at the University of West Florida, located in Pensacola. It’s a joint program between the University of West Florida and the Institute for Human and Machine Cognition (IHMC), which is a nonprofit organization based in Pensacola. The program covers various topics, from AI, machine learning, and robotics to human-machine teaming, natural language processing, and computer networks. There are quite a lot of students in the program and it’s very exciting because you get to do your research, and then also be in contact with people who are doing research and development at IHMC.
My focus is on deep reinforcement learning (RL) for communication networks. I cooperate with the team at IHMC that works on agile and distributed computing, studying the possible roles of reinforcement learning in optimizing communication tasks. The research covers both tasks from the single-agent perspective and the multi-agent perspective. It’s very nice because you have a lot of interactions, and you get different perspectives because not everyone on the team is working in AI. There are people with a strong communication protocols background, in both their theory and development, so that gives me amazing feedback and ideas for my projects.
Could you tell us about the projects you’ve been working on?
I have two main focuses. The first one is working on a reinforcement learning agent for congestion control. That was my very first project on this topic and that really gave me the passion for reinforcement learning applied to communications. I started by trying to apply reinforcement learning to real communication networks. In the laboratory, I built a small network including a router, Wi-Fi access points, switches, and a few hosts, to understand the limitations of partnering a reinforcement learning agent for congestion control with a communication protocol running on one of the hosts. However, the considerations that emerged were not limited to the congestion control task only, as I also wanted to understand what communication protocols in the real world would allow me to do and how to interface with them. For example, there are some limitations due to communication delays or other properties intrinsic to the underlying network that are important to consider. So, after I built this network, I trained an agent to do congestion control, and it was nice to see it acting properly. After we had learned a few lessons from this experiment, I replaced the real network with a network emulator, which allowed me to emulate different scenarios with a higher degree of freedom than a real network.
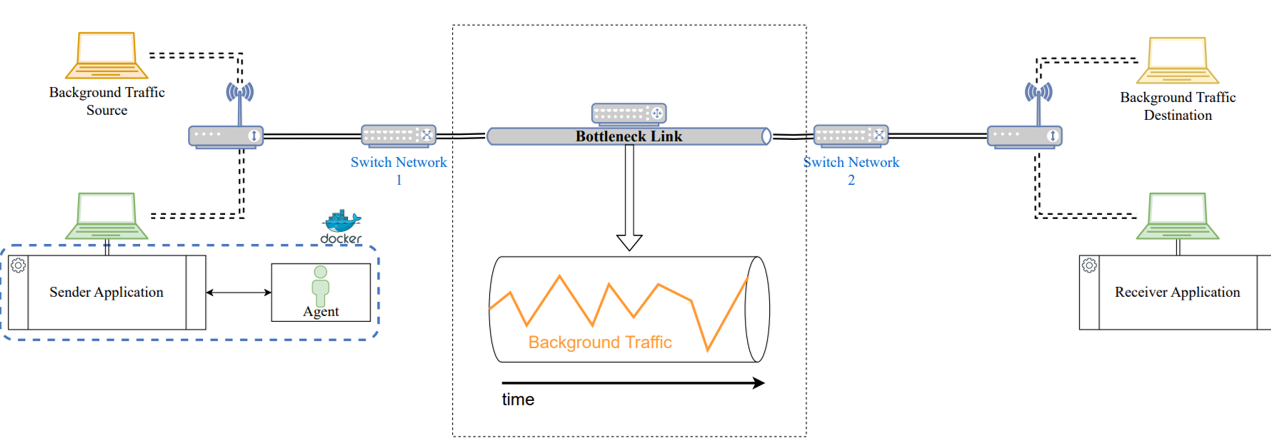 Training and testing the reinforcement learning method for congestion control in a real network.
Training and testing the reinforcement learning method for congestion control in a real network.
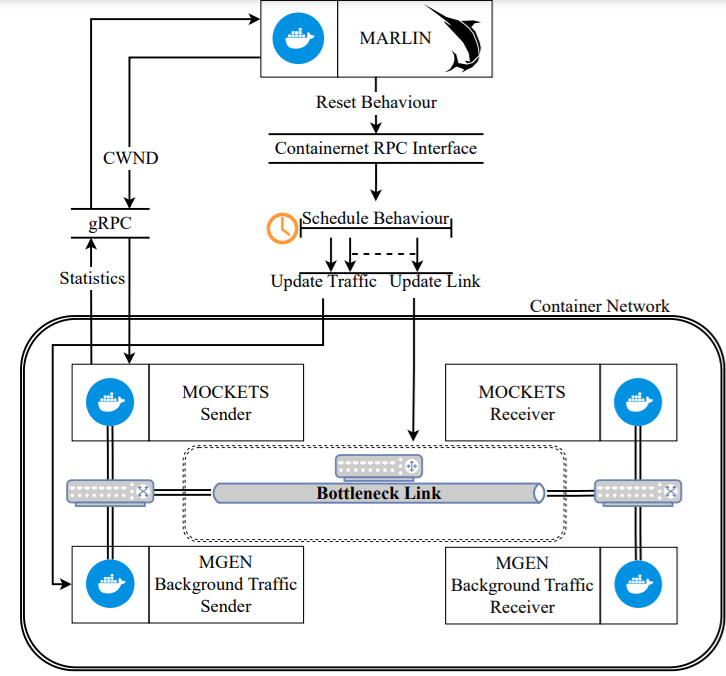 Emulated reinforcement learning framework for congestion control. From Learning to Sail Dynamic Networks: The MARLIN Reinforcement Learning Framework for Congestion Control in Tactical Environments.
Emulated reinforcement learning framework for congestion control. From Learning to Sail Dynamic Networks: The MARLIN Reinforcement Learning Framework for Congestion Control in Tactical Environments.
The other main project that I’m mainly working on right now is more centered on group communication, in particular cooperative message dissemination. For example, in broadcast networks where there are many moving nodes and one of these nodes is the source of some important message, you might want to spread the message while minimizing the number of forwards needed to cover most of the network. The task presents interesting challenges as nodes cannot observe the entire state of the network, but they have only a limited view restricted to their immediate neighbors. However, a node can exchange some bits of information with its neighbors to increase cooperation and decide whether it will forward the message to its neighbors now or later, or if someone else is going to take care of it. For this problem, I use multi-agent reinforcement learning (MARL) to learn the agents’ strategies and graph neural networks (GNNs) to cope with the networked structure of the problem and learn the process of information exchange I mentioned to enable better cooperation among agents. This can be more abstract than congestion control, but still has many applications in real communication networks.
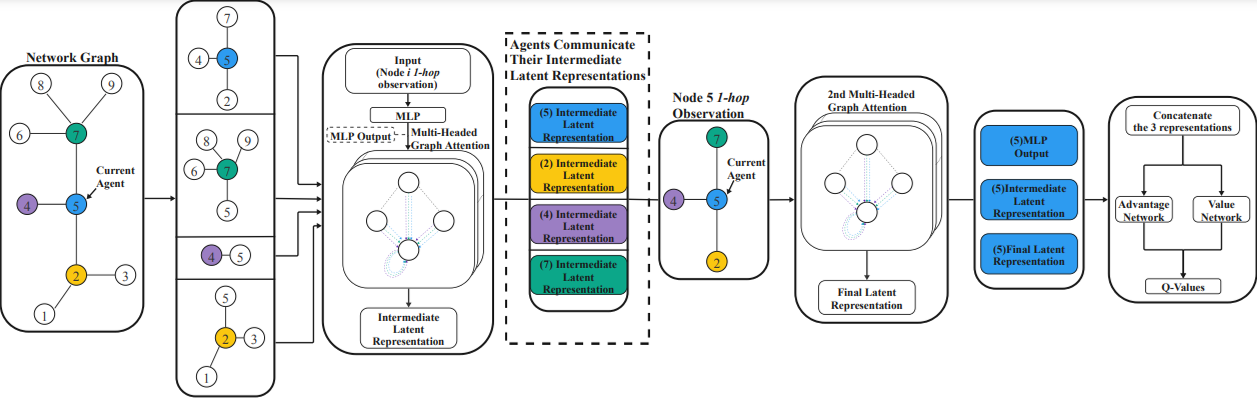 System architecture for the multi-agent reinforcement learning (MARL) approach proposed in Collaborative Information Dissemination with Graph-based Multi-Agent Reinforcement Learning.
System architecture for the multi-agent reinforcement learning (MARL) approach proposed in Collaborative Information Dissemination with Graph-based Multi-Agent Reinforcement Learning.
What’s going to be your main focus for the next few months or year of the PhD?
I’m going to focus on the multi-agent aspects of different group communication tasks and congestion control. I like to see agents cooperate and learn their strategies as well as the information to exchange. I really think it has a place in communication protocols – at least I hope it has a place, anyway! Of course, we’re still a long way from real-world deployment, but I believe that it’s a good direction. I’m interested in how we can use these methods to communicate better, both in an abstract way and in a lower-level applicative way. That’s the path I want to pursue.
How was the AAAI conference experience and did you have any interesting discussions?
It’s my second AAAI, and it’s always nice and fun to be there. I met a lot of cool and interesting people doing cool and interesting research, and there were a lot of PhD students there. I enjoyed the interesting discussions that I had there. There were lots of discussions on large language models (LLMs) and particularly on reasoning. Going around talking to people, we usually ended up asking each other our viewpoints on whether LLMs can reason or not. This was inspired by the panel discussion on LLMs, where the audience had to raise their hands if they thought that LLMs could do some kind of reasoning. I kept my hand down, but I heard some interesting points on both sides.
What was it that made you want to study AI?
I started my master’s degree in Computer Science and Automation Engineering back home in Italy, at the University of Ferrara, after getting my bachelor’s in Electronics and Computer Science Engineering. There was a class that was being run for the first time. It was about deep learning. I was familiar with it, but I was not really a machine learning or AI person. I knew about traditional AI approaches from previous classes, and I didn’t feel attracted by deep learning, but I decided to take the class anyway. After the second lecture, I bought the deep learning book by Ian Goodfellow, Yoshua Bengio, and Aaron Courville and I started reading. From then on, I was hooked, I loved it. I remember that during that period the trend of transformers started, It has been very exciting to see the development of so many different methods and applications from that time on. At the end of my master’s degree, I started exploring reinforcement learning and got attached to that.
How did you go about deciding where and what you wanted to study for your PhD?
During the master’s in Italy, there was the opportunity to go to the USA to study at the University of West Florida, thanks to a collaboration between the two universities. I decided to apply, and I got a place to come and finish my master’s. I learned that there was a PhD program at the same university on Intelligent Systems and Robotics. At the time, I was doing a project with my professor, who works also on communication networks and distributed computing. I started learning more about communication networks and reinforcement learning and then we merged those two things. It was very natural to choose the topic and to continue working on what I’d been researching for the last semester of my master’s.
Could you tell us an interesting fact about you?
I like snowboarding and photography. After many years of using different digital cameras, I am now moving to analogue, it makes me value more each shot that I take! I also used to play basketball back in Italy, we won our league during the last year that I was there. I edit plenty of playlists on Spotify, often with friends. I might have one for every main genre!
About Raffaele

|
Raffaele Galliera is earning a Ph.D. in Artificial Intelligence through the Intelligent Systems and Robotics joint program between The University of West Florida (UWF) and the Institute for Human and Machine Cognition (IHMC). He holds degrees in Computer Science and Electronics Engineering from the University of Ferrara and a master’s in Computer Science from UWF. His research mainly focuses on (multi-agent) reinforcement learning to optimize communication tasks and the deployment of learned policies and strategies in communication protocols. He also has experience in applying machine learning and deep learning models at the network edge (Edge ML). In 2020 and 2021 he served as Vice President and President of the Artificial Intelligence and Data Science student research group at UWF. In 2021 his team placed third at the national challenge “AI Tracks at Sea” organized by the Naval Information Warfare Center (NIWC) Pacific and the Naval Science, Technology, Engineering, and Math (STEM) Coordination Office, managed by the Office of Naval Research. Since 2022, he has been collaborating with different NATO Science and Technology Organization (STO) Information and Technology Systems (IST) research groups and he is an appointed member of the NATO STO IST-194 research group focused on Adaptive Networks. |
tags: AAAI, AAAI Doctoral Consortium, AAAI2024, ACM SIGAI

AUAI is supported by:








