
ΑΙhub.org
Interview with Amine Barrak: serverless computing and machine learning
 Amine Barrak at the AAAI conference, Vancouver, in February 2024.
Amine Barrak at the AAAI conference, Vancouver, in February 2024.
The AAAI/SIGAI Doctoral Consortium provides an opportunity for a group of PhD students to discuss and explore their research interests and career objectives in an interdisciplinary workshop together with a panel of established researchers. This year, 30 students were selected for this programme, and we’ve been hearing from them about their research. In this interview, Amine Barrak, tells us about his work speeding up machine learning by using serverless computing.
Could you give us a quick introduction – where are you studying, and the topic of your research?
I’m Amine Barrak, and I’m doing my PhD at the University of Quebec. My focus is on speeding up machine learning by using serverless computing.
My research is about finding a way to do machine learning training efficiently in small serverless settings. This means breaking down the big tasks of the training into smaller ones that can run in parallel. This saves a lot of time and money.
Could you tell us more about serverless technology, and the link to machine learning?
Serverless computing is the technology within the cloud where you can execute a piece of code. It’s a function that you can write and execute, and you’re only going to be charged for the time it takes to execute this function, and the memory (the RAM) used to execute this function.
When I heard about this technology I wondered if I could use it for machine learning. I started by doing a systematic literature review on serverless on machine learning to find out if people were already using it for machine learning or not. I found out that it was already being used for different stages of machine learning from data preprocessing, model training, hyperparameter tuning and model deployment. So, I did a literature review, and this work was accepted.
After this review, I asked what was missing? How can we use this technology to improve the training? The first idea that came into my mind was about how to adapt machine learning training for this kind of technology. So, I focused on the training. It’s a bit different to regular training. In a normal computer, everything runs within this computer, where you are limited to its resources – you don’t have to download data, send data, etc. In serverless computing it’s stateless, so you don’t keep any data after it finishes the assigned task and shuts down. This means you need to adapt it to use it for machine learning training. You need somewhere where it can be stateful, in other words, a place where the data can be stored during the training. The presence of the database was crucial and to save time, we needed to integrate machine learning operations within the database.
Using serverless computing you can save a lot of time by doing parallel machine learning operations. We take into consideration fault tolerance by keeping the training decentralized inspiring from peer-to-peer network. This approach can be applied within an environment having limited computing resources such as Internet of Things (IoT) environments. I’m applying this within a company as well, preparing solutions for different clients.
Is there a specific project that’s been particularly interesting within your PhD?
One particular PhD project is about modeling the Redis database to realize operations within the database. I was wondering why we always need to rely on the database only as a communication channel. So instead of fetching the data, doing some computation and saving it back to the database, why don’t we use it to do additional computations within the database. The Redis database was the perfect one to use. In our case we use Redis AI, where they integrate multiple frameworks of machine learning within the database. We modify it to do the training and the model update within the database. I believe this could be very useful to people in the future. People could do more operational machine learning within the database, especially when we talk about technologies that do not keep state, like serverless computers.
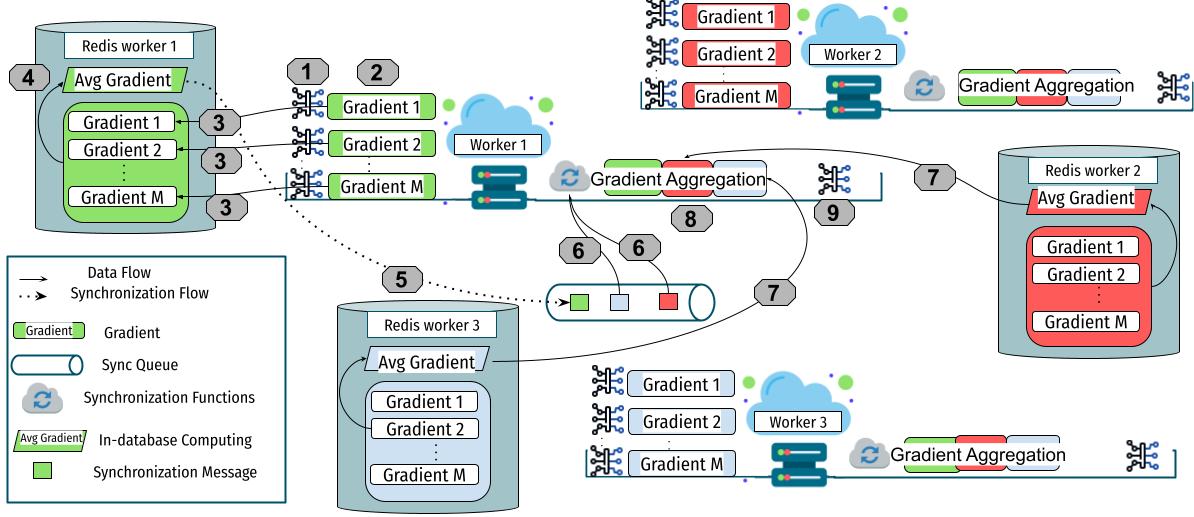 SPIRT architecture, a serverless machine learning architecture that streamlines training in distributed settings. SPIRT was proposed by Amine Barrak, Mayssa Jaziri, Ranim Trabelsi, Fehmi Jaafar and Fabio Petrillo in SPIRT: A Fault-Tolerant and Reliable Peer-to-Peer Serverless ML Training Architecture.
SPIRT architecture, a serverless machine learning architecture that streamlines training in distributed settings. SPIRT was proposed by Amine Barrak, Mayssa Jaziri, Ranim Trabelsi, Fehmi Jaafar and Fabio Petrillo in SPIRT: A Fault-Tolerant and Reliable Peer-to-Peer Serverless ML Training Architecture.
What’s the next step in your research?
I’m currently working on comparing this work with other solutions. Talking specifically about architectures, my idea was based on distributed and decentralized training inspired from the peer-to-peer paradigm. For example, there are systems that rely on one server to orchestrate the processing, and therefore they are exposed to a single point of failure. My idea is to find a way to distribute the processing to avoid these kinds of failures.
My future research is going to focus on improving the machine learning pipeline starting from data preprocessing until model inference. I’m working on the training aspect right now, but I plan to also explore securing the model development process.
How was the AAAI experience?
It was an amazing conference; I learned a lot. I met a lot of people working with large language models. I got new ideas and inspiration for where to apply my research in the future. The doctoral consortium session was especially helpful – I was really inspired by that. They gave us advice on what to do after the PhD, how to get ready for postdoctoral positions or to become a professor. They also talked about the possibility of going into industry, which is a good opportunity as well.
Professor Scott Sanner was the person who chaired the doctoral consortium. He, and his postdoc, evaluated my work and gave me some insights. He told me how the different parts of my projects are interesting, how they could be applied in industry, and some advice for future work.
 Amine presenting his poster at AAAI 2024.
Amine presenting his poster at AAAI 2024.
Have you got any ideas about what you want to do following the PhD?
My goal is to continue as a postdoc at the University of Toronto or at the University of Waterloo. I’m looking to make a partnership between an industrial partner and the university. In Canada, we have Mitacs programs, where we can find an industrial partner who pays half of the amount of the salary of a postdoc. Mitacs then pays the other half. You then need to find a professor to collaborate with. Achieving this would be a significant milestone in my plan.
What was it that made you want to study machine learning? What was the inspiration?
Before my PhD, I worked with simple machine learning models like logistic regression and random forest during my master’s. I got really good results, which made me think I could do more than just use these tools. Moreover, my involvement in a project that explored the traceability of ML pipeline evolution deeply influenced my decision. This experience strengthened my determination to focus on improving machine learning pipeline development in my further studies.
I’m really interested in the machine learning techniques behind the recent developments in large language models and their applications. I saw an interesting talk at the University of British Columbia. The professor talked about her work on explainable AI. I got inspiration from that talk.
Could you tell us an interesting fact about yourself?
So, I come from Tunisia, and I was studying at the Higher Institute of Computer Science (ISI), when the Tunisian government awarded me a scholarship in computer science to continue my studies in Canada. I was really lucky because this scholarship is only given to two to four people each year from the whole of Tunisia, and I was one of these four people in 2016. I will always be thankful to Tunisia for changing my future and for allowing me to have such a great environment for continuing my research.
About Amine

|
Amine Barrak is a Ph.D. candidate in Software Engineering at the University of Quebec, specializing in the integration of serverless computing with distributed machine learning training. Holding a master’s degree from Polytechnique Montreal, his focus was on security vulnerability changes in software code. Throughout his academic career, Amine has published in leading journals and international conferences, earning the Best Student Paper Award at CASCON 2018. During his Ph.D., Amine also contributed to academia by giving courses on cloud computing, distributed systems, and cryptography. |
tags: AAAI, AAAI Doctoral Consortium, AAAI2024, ACM SIGAI

AUAI is supported by:








