
ΑΙhub.org
Interview with Mike Lee: Communicating AI decision-making through demonstrations

In a series of interviews, we’re meeting some of the AAAI/SIGAI Doctoral Consortium participants to find out more about their research. The Doctoral Consortium provides an opportunity for a group of PhD students to discuss and explore their research interests and career objectives in an interdisciplinary workshop together with a panel of established researchers. In this latest interview, we chatted to Mike Lee about his work on explainable AI.
Could you tell us a bit about your PhD and what the main topic of the research was?
My work falls under the category of explainable AI. Specifically, I was looking at how to make AI decision making more transparent to humans, by selecting and showing informative demonstrations of the various trade-offs that an AI will make in different situations. As a concrete example, imagine a delivery robot that has learned a policy for navigating outdoor terrain. A couple useful demonstrations would be showing how long a detour a robot is willing to make to bypass mud. Maybe if the mud patch is small, it doesn’t want to risk potentially getting stuck and would detour around. But for a long mud patch, a long detour would be more costly and the robot would just go through the mud (along its shorter axis). Knowing how the robot will navigate will be helpful for the people that are negotiating the same space. To summarize, the idea behind my research was to communicate AI decision making through informative demonstrations of AI behavior.
What was the motivation behind your work?
A common paradigm for selecting demonstrations is to select ones that maximize information gain or provide the most information about the agent’s decision making. But when we tried out this heuristic, we found that those demonstrations were actually overwhelming to people and led to poor objective and subjective results. When a demonstration teaches too much at once, people have a hard time parsing it. Therefore, we turned to inspiration from principles from cognitive science and the education literature to select informative and understandable demonstrations. One key principle was the zone of proximal development, which suggests providing content that is right in the “Goldilocks zone” of not being too easy but not being too difficult. Around that idea we provided three contributions, which each led to a publication that built on the previous works and iteratively refined on shared ideas.
Could you tell us about these three projects?
The first project was on scaffolding demonstrations. This is an idea from the education literature on breaking up a difficult task into incremental steps and gradually reducing assistance as the student progresses. We would provide a sequence of demonstrations that incrementally provides additional information (e.g. providing one trade-off at a time) in a visually salient manner to make it easy to understand.
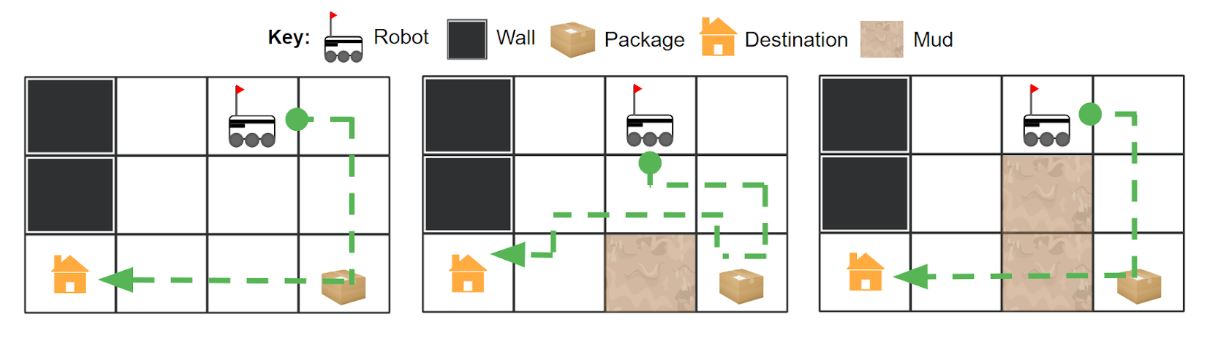 Sample scaffolding of demonstrations that incrementally provide information in a visually salient manner (e.g. maximizing similarity between consecutive demonstrations).
Sample scaffolding of demonstrations that incrementally provide information in a visually salient manner (e.g. maximizing similarity between consecutive demonstrations).
The second project was on maintaining a running model of the human beliefs over the AI’s decision making to select a demonstration that differs just the right amount from their (counterfactual) expectations of AI behavior. You don’t want to do something that’s too different, otherwise it may be really hard for them to understand why. But if it’s too similar, you’re not providing enough information. So again, aiming for that sweet spot as you scaffold demonstrations by maintaining an accurate model of what the human believes and what the human would expect the AI to.
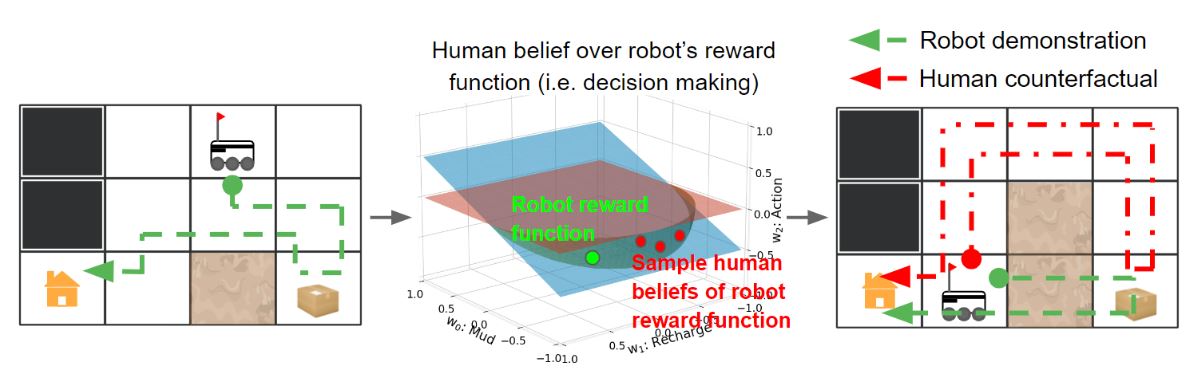 Maintaining a model of human beliefs over AI decision making to provide demonstrations that differ just enough from human (counterfactual) expectations to be informative.
Maintaining a model of human beliefs over AI decision making to provide demonstrations that differ just enough from human (counterfactual) expectations to be informative.
Finally, human learning can always deviate from a curriculum of demonstrations that is selected a priori given a hypothesized model of human beliefs. Thus, the last project developed a closed-loop teaching framework that utilized intermittent testing in between groups of related demonstrations to check whether the human truly understood the material. If not, we’d examine their test answer and provide remedial instruction, such as new demonstrations or new tests, that specifically target their misunderstanding. Our closed-loop teaching framework reduced the suboptimality of human responses in a set of held-out tests by 43% compared to the open-loop (i.e. where demonstrations are selected a priori) baseline.
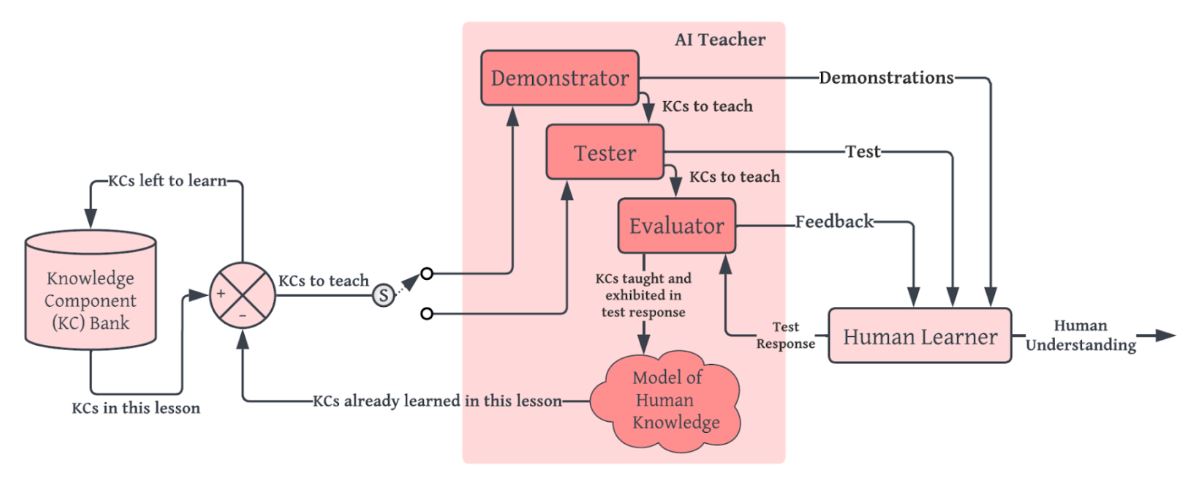 Proposed closed-loop teaching framework for leveraging intermittent testing and feedback (in between demonstrations) to provide targeted remedial instruction as necessary.
Proposed closed-loop teaching framework for leveraging intermittent testing and feedback (in between demonstrations) to provide targeted remedial instruction as necessary.
All three projects nicely flowed into each other, which made writing the thesis a lot easier.
How did you work with people to test out your theories and put the work into practice?
I used a hybrid of in-person pilots and online user studies. Part of the research took place during the pandemic, and I was fortunately working in a domain that could be completely specified online. Using a platform called Prolific, I was able to recruit around 160-200 participants for each online user study to acquire the required statistical power for my analyses and also collect a variety of qualitative responses. While online studies are great for collecting a lot of data in a short amount of time, you can lose out on the richness of in-person interactions. I thus also made sure to pilot each study with people in my lab and friends that weren’t familiar with my work, getting their feedback on things that they found helpful, unhelpful, confusing, etc. These real-time pilots were actually the most enjoyable, because you often find that people interact with your system in ways that you never expected.
Is there anything that really surprised you about any of the results that you got?
Yes, definitely. Two nuances that we observed in our study results come to mind.
At the start of our research, we were naively hoping to provide demonstrations that do not require any mental effort for the human to understand. But we soon discovered that mental effort is often correlated with learning, and you likely cannot drive it down beyond some minimum level while maintaining learning. You want to remove any excess mental effort, but you also need to challenge people with new information that they need to reconcile in their minds. It’s a really interesting balancing act that relates to the concept of the Zone of Proximal Development that I alluded to earlier. For additional examples on how this shows up in other domains, Duolingo has found that tests which a user is 81% likely to get right are best for teaching and keeping the user engaged. There are other studies that show that around 80-85% is the sweet spot for training algorithms that utilize stochastic gradient descent.
Our results also showed a nuanced interaction effect with the two domains that we worked in. They were both grid-world domains with similar state-space sizes and similar reward functions consisting of a weighted linear combination of three features. But despite their similarities, they significantly differed in their difficulty across both objective and subjective metrics. Our demonstration-based teaching model reduced the suboptimality (or regret) of human test responses by 64% compared to a baseline across both domains, but at the cost of increased mental effort. Interestingly, we find that the reduction in suboptimality is much greater in the more difficult domain. This again captures the general sentiment in explainable AI that there really is no one-size-fits-all method. Perhaps the baseline of directly communicating reward functions is sufficient in less difficult domains where the increased mental effort may not justify the smaller reduction in suboptimal responses. There are often these domain-specific trade-offs to keep in mind when selecting an explainability method, and characterizing domains is still an open question.
What was it that made you want to study AI?
I would trace it back to the FIRST Robotics Competition where teams built robots in the fall semester to participate in that year’s unique challenge. My favorite challenge was building a robot that could quickly collect balls lying on the ground and transport them into an opponent robot’s trailing wagon. It was fun to brainstorm, implement, and test different robotic capabilities and strategies in the competition arena (e.g. we found that pinning an opposing robot and dumping our ball collection all at once was more effective than shooting one ball at a time). This experience led me into field robotics, where I explored research in a variety of topics such as prediction of feature-based visual odometry failures (summer internship), and gamma radiation source localization and map representation (Master’s thesis). But as time progressed, I found that some of the richest questions and interactions for me were in how robots interfaced with humans. That’s why I pivoted to explainable AI and human-AI interaction for my PhD, where. I focused on ways to identify and reconcile gaps in the understanding between AI and human decision making.
I wanted to ask you about the AAAI doctoral consortium. How was the experience?
It was great! I enjoyed seeing some familiar faces. For example, I know that you’ve also interviewed Aaquib – he and I were actually HRI pioneers together in 2019. We first met in Korea at that workshop at the start of our PhDs, and it was great to participate in the AAAI doctoral consortium together near the end of our PhDs as well. The connections that you make in these doctoral consortiums can last throughout your career, which I think makes them really special.
I was also able to connect with new colleagues. For example, another student is studying trade-offs of communicating counterfactuals – which I’ve considered in my work – and the complementary idea of semifactuals in helping humans map the AI’s decision boundaries in their mind. With counterfactuals, you ask the question “what would need to change to flip the outcome?”, but with semifactuals you ask “how much can I change while maintaining the same outcome?” As we both leverage similar ideas in our research, it was really helpful to connect and chat. The public poster session also allowed us to engage with a broader audience. For instance, I was able to connect with a professor who also explored counterfactuals in her work, but in a very different domain.
I’m wondering what advice you’d give to someone who’s thinking of doing a PhD in the field?
I have two pieces of advice. The first is to not be afraid of pursuing challenging questions and taking risks in your research. I know that there can be pressure to adhere to a certain graduation timeline, and it can be very easy to settle for projects that provide incremental contributions. In my experience, at least, the first couple of years are truly open-ended and they’re meant for you to explore. So don’t be afraid to really dive in and challenge yourself right from the beginning.
The second one would be to collaborate often with others who have complementary strengths, perspectives, and ideas. I think it’s the most efficient and effective way to learn, contribute meaningful work, and broaden your own horizons. And there are so many ways to connect with others. Obviously, you can do that locally in your department or your school, but you can also reach out to authors from different organizations whose work you admire. People love discussing their own work and are always on the lookout for new ideas and directions. I’d recommend networking at conferences and being very proactive in building those connections. A PhD can often seem like a solitary endeavor, but the best ones are richly connected.
Could you tell us an interesting fact about you?
I’ve always been a very big fan of intentionally building small habits that make a very big difference in your life in the long run. Speaking of which, I really enjoy running – it’s a great way to be healthy and to unwind after a busy day. Everywhere I’ve lived, I’ve picked a route that has a hill around three-quarters of the way through, and I’ve always made it a goal of mine to sprint up that hill no matter how I’m feeling that day. It’s a really good exercise in maintaining discipline and resilience, and I love the satisfaction that you feel at the top.
Another habit of mine is to turn off data on my phone before I go to bed. That way, I don’t wake up to a bunch of notifications that get my mind racing immediately. I instead like to spend some time easing into the day. I grew up in the Christian faith, so I’ll begin my morning with Bible reading and prayer, before turning my data back on and jumping into the rest of the day more intentionally.
About Mike

|
Mike Lee is currently a postdoc in the Robotics Institute at Carnegie Mellon University, supported by Professor Henny Admoni and Professor Reid Simmons. He received his PhD in robotics from Carnegie Mellon University and his bachelor’s in mechanical and aerospace engineering from Princeton University. Mike researches explainable AI, and his PhD thesis explored how AI agents can teach their decision making to humans by selecting and showing demonstrations of AI behavior in key contexts. Mike was also selected as an HRI Pioneer in 2019, was a finalist for the National Defense Science and Engineering Graduate (NDSEG) Fellowship, and has interned at NASA Jet Propulsion Laboratory. |
Find out more
- Machine Teaching for Human Inverse Reinforcement Learning, Michael S. Lee, Henny Admoni, Reid Simmons
- Reasoning about Counterfactuals to Improve Human Inverse Reinforcement Learning, Michael S. Lee, Henny Admoni, Reid Simmons
- Closed-loop Teaching via Demonstrations to Improve Policy Transparency, Michael S. Lee, Reid Simmons, Henny Admoni
- Improving the Transparency of Agent Decision Making to Humans Using Demonstrations, Michael S. Lee, PhD thesis
tags: AAAI, AAAI Doctoral Consortium, AAAI2024, ACM SIGAI

AUAI is supported by:








